




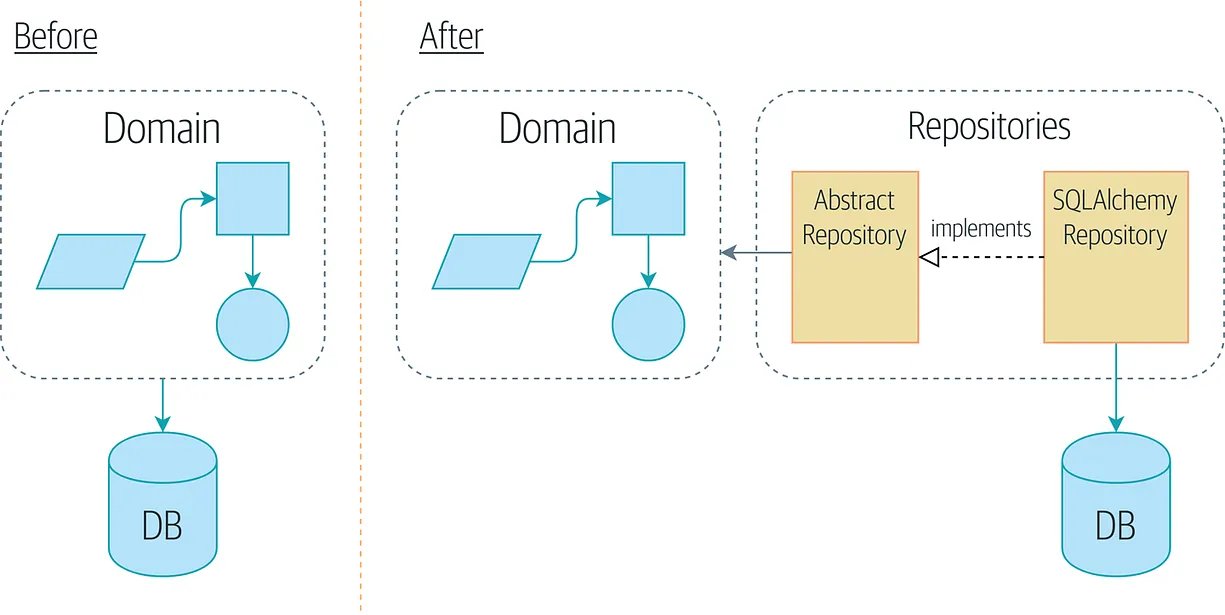
存储库设计模式,即Repository Design Pattern,是一种强大的编程模式,它的核心思想在于将数据访问逻辑与业务逻辑清晰地分离开来。这个模式的关键之处在于,它创建了一个中间层,将应用程序与底层数据存储隔离开来,这个中间层被称为"存储库"。
这个存储库不仅仅是一个简单的数据存储容器,它更像是一个通用接口,为应用程序提供了一系列方法,用于方便地与数据进行交互。这种抽象层面的设计使得应用程序不必关心数据存储的具体细节,而只需专注于业务逻辑的处理。
存储库设计模式的精髓还体现在其多重角色上。它不仅可以被看作是一个外观模式(Facade),提供了一个简化的、易于操作的接口,用来访问底层的复杂数据系统,还可以被视为一个工厂模式(Factory),以高度灵活和可扩展的方式创建对象。此外,由于存储库通常提供类似集合的接口,它还扮演了迭代器模式(Iterator)的角色,为遍历对象集合提供了便捷的方法。尽管存储库设计模式扮演了多重角色,但它仍然具有自己独特的特点,是一种独立而重要的设计模式。
当应用程序需要与数据进行交互时,它只需调用存储库中适当的方法。然后,存储库会负责将这些方法调用转化为适当的查询或命令,与底层的数据存储机制进行交互,使得应用程序能够以一种高度抽象和可维护的方式管理数据。这使得代码更容易理解和维护,同时也增加了系统的灵活性和可扩展性。
具体实施
为了开始实施存储库设计模式,我们首先需要创建一个抽象的 IRepository 接口。这个接口将充当整个模式的基础,为后续的具体实现提供了规范和结构。
from abc import ABC, abstractmethod
class IRepository(ABC):
@abstractmethod
def get_all(self):
raise NotImplementedError
@abstractmethod
def get_by_id(self, id):
raise NotImplementedError
@abstractmethod
def create(self, item):
raise NotImplementedError
@abstractmethod
def update(self, item):
raise NotImplementedError
@abstractmethod
def delete(self, id):
raise NotImplementedError
InMemoryRepository 类承担了实现 IRepository 接口的责任,并为我们提供了一个基于内存的数据存储解决方案。这意味着,它充当了一个在内存中管理数据的仓库,而不依赖于外部数据库或持久化存储。
class InMemoryRepository(IRepository):
def __init__(self):
self._data_source = []
def get_all(self):
return self._data_source
def get_by_id(self, id):
return next((item for item in self._data_source if item['id'] == id), None)
def create(self, item):
item['id'] = len(self._data_source) + 1
self._data_source.append(item)
return item
def update(self, item):
index = next((i for i, obj in enumerate(self._data_source) if obj['id'] == item['id']), None)
if index is not None:
self._data_source[index] = item
return True
return False
def delete(self, id):
index = next((i for i, obj in enumerate(self._data_source) if obj['id'] == id), None)
if index is not None:
self._data_source.pop(index)
return True
return False
我们创建了一个名为 SQLRepository 的类,它实现了 IRepository 接口,并采用 SQL 数据库作为数据存储方式。重要的是,这个类可以与 InMemoryRepository 类无缝交替使用,因为它们均实现了相同的 IRepository 接口。这意味着,无论是内存中的数据存储还是 SQL 数据库,应用程序都可以轻松切换,并享有一致的接口,这为数据管理提供了更大的灵活性。
class SQLRepository(IRepository):
def __init__(self, connection_string):
# initialize database connection
self._connection_string = connection_string
self._connection = db.connect(connection_string)
def get_all(self):
# query all records from database
cursor = self._connection.cursor()
cursor.execute("SELECT * FROM items")
results = cursor.fetchall()
return results
def get_by_id(self, id):
# query record by id from database
cursor = self._connection.cursor()
cursor.execute("SELECT * FROM items WHERE id=?", (id,))
result = cursor.fetchone()
return result if result is not None else None
def create(self, item):
# insert record into database
cursor = self._connection.cursor()
cursor.execute("INSERT INTO items(name, description) VALUES (?, ?)", (item['name'], item['description']))
self._connection.commit()
item['id'] = cursor.lastrowid
return item
def update(self, item):
# update record in database
cursor = self._connection.cursor()
cursor.execute("UPDATE items SET name=?, description=? WHERE id=?", (item['name'], item['description'], item['id']))
self._connection.commit()
return cursor.rowcount > 0
def delete(self, id):
# delete record from database
cursor = self._connection.cursor()
cursor.execute("DELETE FROM items WHERE id=?", (id,))
self._connection.commit()
return cursor.rowcount > 0
通过允许多种数据存储机制互相替代使用,这有助于更容易地扩展应用程序。
现在,让我们编写一个示例服务,利用这些存储库,并展示客户端代码:
class ItemService:
def __init__(self, repository):
self._repository = repository
def get_all_items(self):
return self._repository.get_all()
def get_item_by_id(self, id):
return self._repository.get_by_id(id)
def create_item(self, name, description):
item = {'name': name, 'description': description}
return self._repository.create(item)
def update_item(self, id, name, description):
item = self._repository.get_by_id(id)
if item is None:
return False
item['name'] = name
item['description'] = description
return self._repository.update(item)
def delete_item(self, id):
return self._repository.delete(id)
# client code
in_memory_repository = InMemoryRepository()
item_service = ItemService(in_memory_repository)
item_service.create_item('item 1', 'description 1')
item_service.create_item('item 2', 'description 2')
items = item_service.get_all_items()
print(items)
item = item_service.get_item_by_id(1)
print(item)
item_service.update_item(2, 'updated item', 'updated description')
items = item_service.get_all_items()
print(items)
item_service.delete_item(1)
items = item_service.get_all_items()
print(items)
这个实现的最显著好处在于它实现了关注点分离。这意味着我们将数据访问和操作的核心任务与整体结构分开处理。IRepository 定义了一系列方法,用来与数据进行交互,而具体的实现则负责处理不同数据结构的具体细节。
在客户端代码中,我们创建了一个InMemoryRepository的实例,并将其传递给ItemService的构造函数。接下来,我们可以利用ItemService的方法来操作数据存储。由于ItemService依赖于IRepository接口(这符合依赖倒置原则),因此客户端代码与存储库的具体实现细节解耦,这使得切换到不同IRepository接口的实现变得轻而易举。
另外,为了进行测试,我们可以为ItemService类编写一组单元测试。通过使用MockRepository,我们能够创建一个虚拟的IRepository接口实现,从而能够在测试过程中精确控制存储库的行为。这有助于确保ItemService在不同情况下都能正常运行。
import unittest
class TestItemService(unittest.TestCase):
def setUp(self):
self.mock_repository = MockRepository()
self.item_service = ItemService(self.mock_repository)
def test_create_item(self):
item = self.item_service.create_item('item 1', 'description 1')
self.assertIsNotNone(item)
self.assertEqual(item['name'], 'item 1')
self.assertEqual(item['description'], 'description 1')
self.assertTrue(self.mock_repository.create_called)
def test_update_item(self):
self.mock_repository.set_return_value({'id': 1, 'name': 'item 1', 'description': 'description 1'})
result = self.item_service.update_item(1, 'updated item', 'updated description')
self.assertTrue(result)
self.assertTrue(self.mock_repository.update_called)
def test_delete_item(self):
self.mock_repository.set_return_value({'id': 1, 'name': 'item 1', 'description': 'description 1'})
result = self.item_service.delete_item(1)
self.assertTrue(result)
self.assertTrue(self.mock_repository.delete_called)
if __name__ == '__main__':
unittest.main()
通过采用IRepository的虚拟实现,我们能够将ItemService与数据操作的具体细节有效地隔离开来,这为编写、理解和维护单元测试提供了极大便利。
仓储设计模式在软件开发领域扮演着重要的架构模式角色,它为数据访问提供了一种规范化的途径,并将数据存储和检索的复杂细节与应用程序的其余部分分离开来。这有助于实现关注点的分离,从而使代码库更易于维护和测试。此外,它还提供了更好的可扩展性,允许无缝地在多个数据源之间切换,而无需影响应用程序的核心逻辑。