




才一天,谷歌Gemini被质疑造假、夸大宣传的议论声淹没了。多模态视频是剪辑拼贴的,打败GPT-4靠的是后期视频剪辑,AlphaGo也并未结合进Gemini中。谷歌这波公关,属实是着急了。
谷歌的宣传视频,竟然作假了?
在谷歌昨天发布的Gemini的宣传视频中,所有人都被那一段6分钟一镜到底的互动视频惊艳到了。
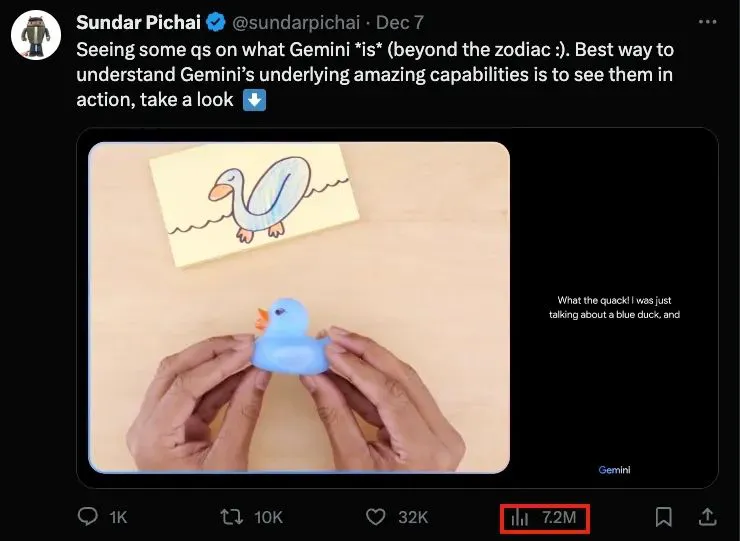
一天之内有720万的播放量。网友惊呼,Gemini看起来就像一个能随时事无巨细地向你解释一切的朋友。

视频中看起来,好像Gemini能够实时地感知人类的动作,并且直接做出语音回应。
然而,有越来越多的人质疑demo的真实性。
彭博社的Parmy Olsen,第一个质疑视频造假。
.png)
随后,谷歌官博也放出了解释——
是的,视频的确有后期制作和剪辑的成分。
根据官方发布的一个技术文档,Gemini所有的这些交互都不是实时感知到的,而是通过提示词问出来的。比如:

视频中显示,似乎Gemini能直接看懂人类在玩石头剪子布,
但其实,真实的过程是,向Gemini上传一张手比剪刀的照片,问它看到了什么。然后用人声把它的回复读了出来。
而石头剪子布的视频,则是把三张照片依次传给Gemini,让它把这三张照片连在一起推理,它直接给出回答,这是在玩石头剪子布。
所以,实际上并不是Gemini看懂了一段视频,它只是看懂了三张图片,并且做出了推理而已。
.png)
人类给Gemini传了一张「剪刀」的照片,Gemini回复说:「这似乎是伸出了两个指头的手势,一般来说这个手势代表着数字2」。然后人类又传了3张「石头剪刀布」的手势照片,问它这三张照片合在一起是什么意思。Gemini才说了这是「石头剪子布」游戏
同样,在识别行星的演示,视频给人营造的感觉仿佛是直接问Gemini「这个顺序正确吗」,它就能回答不正确,应该是太阳、地球、土星。

但实际上,是谷歌给了Gemini一句prompt:「这个顺序正确吗?请考虑它们与太阳的距离,并且解释你的理由」,随后,Gemini才回答了那样一句话。
.jpg) 很多网友也认为,谷歌这种有意地误导性呈现,反而让用户会怀疑,到底模型的真实能力有多强。
很多网友也认为,谷歌这种有意地误导性呈现,反而让用户会怀疑,到底模型的真实能力有多强。
.png)
毕竟,产品不能永远停留在宣传视频里,最终都要交到用户手上去体验。
这个视频最大的误导性在于,似乎让用户误以为Gemini能实时的读取视频信息,并且能够通过自己的理解直接推测用户的问题并直接回复。
而实际情况是,谷歌员工是通过读取图片+良好的提示词工程才能让Gemini生成这些回复的。
虽然说从技术原理上来看,能够读取图片和能够看懂视频之间,并没有技术上的鸿沟。
但是从产品实现落地的角度看,把读取图片约等于能实时看懂视频,并且过于强调实时性而压缩了交互过程中的延迟,这几乎已经可以理解为虚假宣传了。
而是否需要良好的提示词工程,更是评价模型能力的关键问题。
谷歌的这些「后期加工」,只能说明,他们太想让Gemini「看起来」比竞品好太多了。
毕竟,起了个大早却赶了个晚集的谷歌,在大模型上确实太需要流量了。
在YouTube描述中,谷歌也承认了该视频被编辑为延迟,这样就能使得模型看起来响应速度比实际更快。
Olson表示,谷歌的营销非常巧妙,所以我们真的应该在AI炒作中更加谨慎,保持清醒的头脑和判断力。
.png)
谷歌,令人失望了
本来,昨天Gemini的演示一出立马惊艳了众人,本来是多模态理解领域的一次令人兴奋的展示。
现在被扒出伪造,显然会让用户对谷歌的诚信失去信心。谷歌这一出,着实得不偿失。
其实本来,Gemini确实输出了视频中显示的回应。
但视频的剪辑效果,却会让用户对于Gemini的交互速度、准确性和基本模式产生误解。
石头剪子布的demo,和实际上Gemini对于三张图片的识别,是完全不同的交互。
前者是一种直观的反应,表示Gemini可以即时捕捉一个抽象的想法;而后者,则是经过精心设计、充满大量暗示的交互,虽然的确体现了Gemini的能力,但也具有不少局限性。
如果视频一开始就明确指出,「这是研究人员测试Gemini互动的一种风格化演示」,可能会让公众的期待者降低一些,也就不会像如今这样失望。
而且,视频名叫「Hands-on with Gemini」,暗示了视频中展示的就是和Gemini的原样互动。然而实际上Gemini的参与程度,是掺了水分的。
视频中也没有明说,视频中的模型,到底是Gemini的哪个版本。
总的来说,这段视频半真半假,尽管包含一些真实的成分,但它根本没有反映现实。
网友深表理解
Perplexity AI的首席执行官将网友对谷歌Gemini造假视频,做了客观的分析。
当前有两种激进派的人,是这样看待Gemini的发布:
极端看法1:「DeepMind伪造了评估和演示。Gemini很糟糕」。
极端看法2:「OpenAI 完蛋了。谷歌回来了。Bard将免费运行Gemini,因为计算芯片的利润空间,它会击败 ChatGPT」。
而现实情况是,Gemini很酷,是第一个真正可以与GPT-4媲美的模型,也是谷歌真正的成就之一。尤其它仅仅是一个密集型模型(原生模型)。
这次,只能说谷歌的市场营销手段过火了,但众所周知DeepMind喜欢高调公关。
而谷歌视频演示的多模态能力,实际上在一年内就能实现。
.png)
一位网友对此表示深度赞同,太多人想要给谷歌扣上「伪造」视频的黑帽。
.png)
还有人表示完全理解炒作的行为,毕竟谷歌对微软OpenAI的反击晚了一步。
网友试用体验
我让Gemini画了一幅一个人开着电卡车在树林里露营的图,它生成的样子如下。
.png)
还是需要稍加修改,有待进步。
.png)
这位网友发出了自己测试基于Gemini Pro的Bard,对于很多事实类问题还是有错误。
他问了两遍Bard奥斯卡2023年的获奖情况,Bard给了两个不同的错误获奖名单。
.png)
另一个网友又问了一个和翻译有关的问题,结果也不太对。
.png)
似乎它对语言中单词字数非常不敏感,经常会数错。
.png)
而对于谷歌重点宣传的代码能力,似乎Bard的表现也不够好,难道原因是在Stackoverflow上没有对应的答案?
.png)
还有人也模仿谷歌的行为,让ChatGPT从MP4中提取视频帧,然后解释视频......
.png)
ChatGPT自主从从视频中提取帧,然后网友上传6张对应图片,让ChatGPT给出具体的解释。
.png)
.png)
.png)
.png)