




谷歌最近推出了他们的最新科技产品——Gemini Pro,这一产品的发布引起了广泛关注。紧随其后,他们还计划推出性能更强的 Gemini Ultra。
目前,各大媒体正对 Gemini Pro 和 Gemini Ultra 与其他先进技术进行比较。例如,Claude 2 被认为在某些方面超越了 GPT-4,谷歌的 Bard 也表现的非常出色,而现在谷歌的 Gemini 系列似乎正在成为新的领跑者。这引发了大家比较关注的一个问题:Gemini 系列是否真的在性能上超过了 GPT-4?

这个话题正成为最近业界热议的焦点。他们引用了一张表格,声称基于一项广受尊敬的基准测试,Gemini 已经超越了 GPT-4。而众所周知,数据是客观的,并不能代表实际使用者的观点。以下是相关的数据对比:
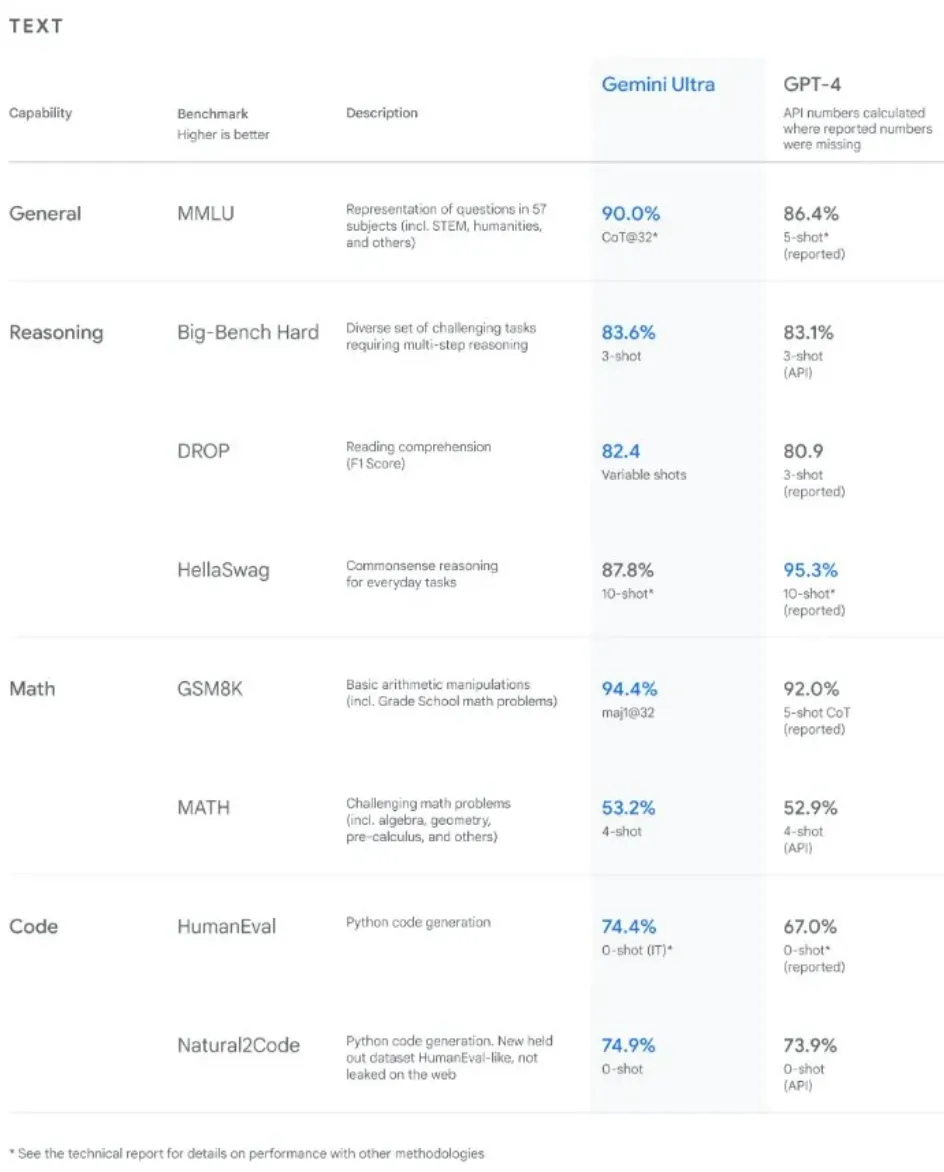
关于基准测试,我们需要明白一个重要事实:它们并不是完全无懈可击的。想象一下,如果一个语言模型是用与它测试时相同的数据进行训练的,这就相当于在考试前就已经看到了题目。如果模型仅针对这些特定内容进行学习,它当然能够表现得很好。但这并不一定意味着它本身就更先进,可能只是因为它对这些内容准备得更充分。
因此,虽然我们并不是在质疑谷歌采取了不恰当的手段,但在接受这些基准测试结果时,我们还是应该保持谨慎,对结果进行实事求是的评估。
现在,我们来仔细比较一下谷歌的 Gemini Pro 和 GPT-4。如果你还没有试过 Gemini Pro,它是可以免费使用的。你可以在 https://bard.google.com/ 了解更多信息。此外,Gemini Pro 还能直接与谷歌的 Bard 进行连接。接下来,让我们看看它们在不同方面的表现情况。如下图所示:
对比项 | GPT-4 | Gemini Pro |
|---|---|---|
推理能力 | 高效准确,友好解决逻辑问题 | 较差,答案有时不够精确 |
视觉能力 | 准确理解和解释图像内容 | 在图像识别和解释方面不如 GPT-4 |
Token限制 | 处理长文本能力强,例如可处理约17,408字的文本 | 相对较低的Token限制,处理大文本时可能达到极限 |
长文本摘要 | 结构清晰、连贯 | 能对 YouTube 视频进行摘要,但文本摘要略逊一筹 |
知识更新 | 更新至2023年4月 | 最后更新时间不明确 |
数学技能 | 解决数学问题表现出色 | 在数学问题解答中有波动 |
网络搜索能力 | 在网络搜索方面存在局限 | 强大的网络搜索能力,优于 GPT-4 |
推理
大型语言模型的类似人类思维能力可以通过考察其解决逻辑问题的能力来评估。例如,以下是一个逻辑问题:
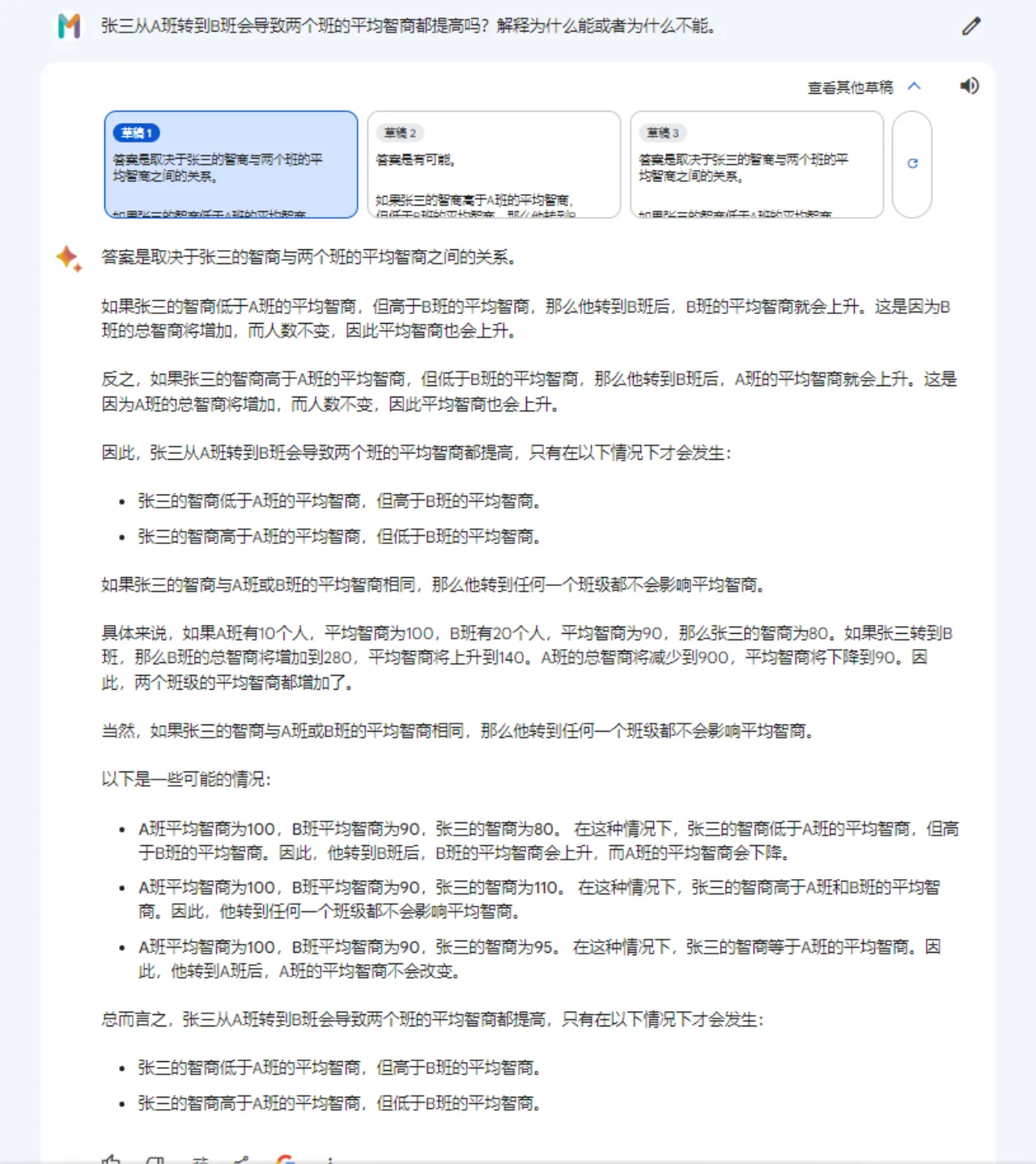
张三从A班转到B班会导致两个班的平均智商都提高吗?解释为什么能或者为什么不能。
答案很简单:如果杰克的智商低于 A 班的平均智商,但高于 B 班的平均智商,那么他转到 B 班后,B 班的平均智商就会上升。反之,如果张三的智商高于 A 班的平均智商,但低于 B 班的平均智商,那么他转到 B 班后,A 班的平均智商就会上升。因此,张三从 A 班转到 B 班会增加这两个班级的平均智商。
我们看看 ChatGPT-4 的表现如何:

GPT-4 提供了一个精准而友好的答案,直击要点。
相比之下,Gemini Pro 的尝试并未达到同样的标准。以下是其较为友好的一次尝试:
在进行常识知识测试时,我们遇到了一个非常说明性的例子。问题十分直白:
假设我有一个12升的水壶和一个6升的水壶,我想要量出6升水,应该如何操作?
其解决方案非常简单明了:只需使用6升的水壶来量取所需的6升水。
虽然 GPT-4 给出的回答可能稍显冗长,但它确实解决了这个问题:

然而,相比之下,Gemini Pro 的处理方式则显得更为复杂:

这里是一个典型的常识性问题:
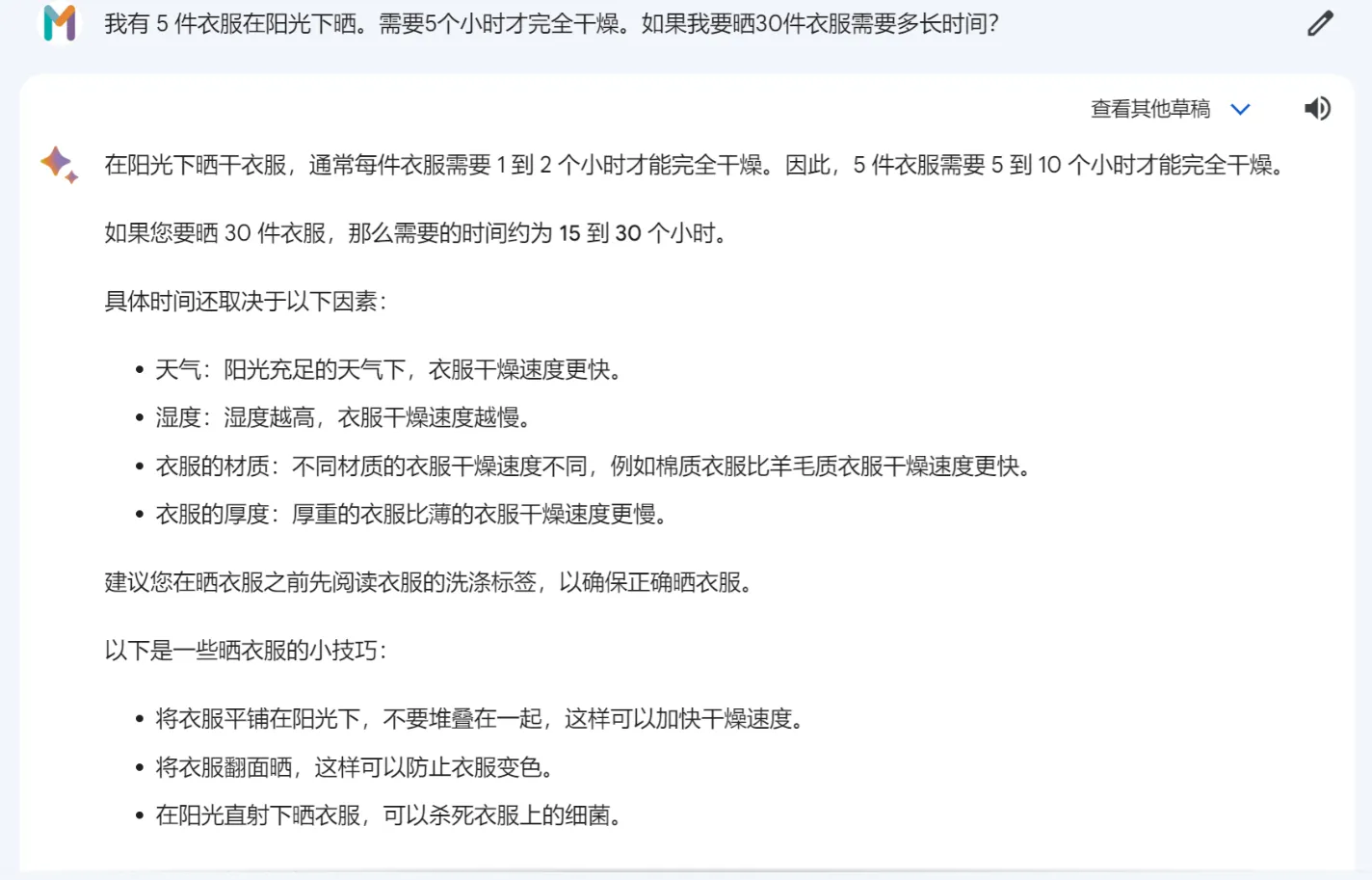
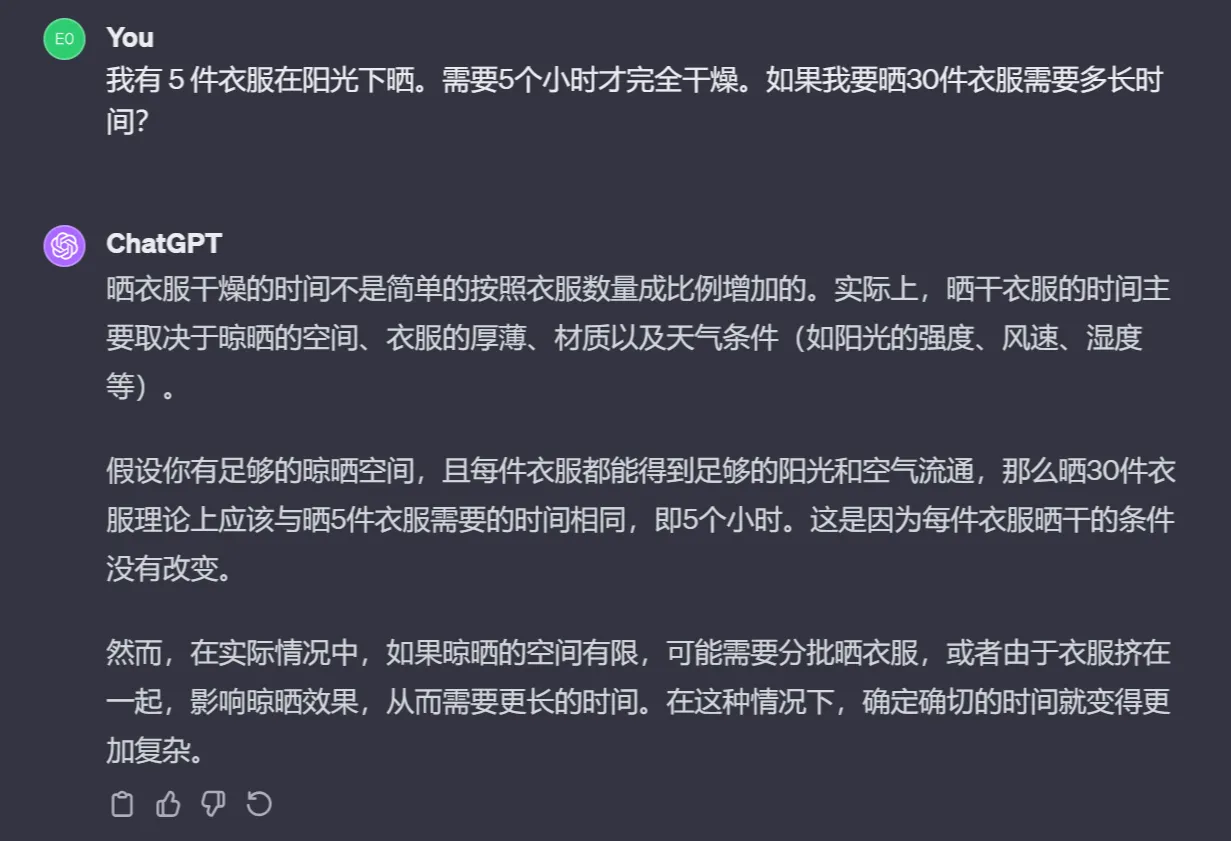
我有 5 件衣服在阳光下晒。需要5个小时才完全干燥。如果我要晒30件衣服需要多长时间?
众所周知的答案是 — 只需5个小时。
Gemini Pro 对此问题的回答并不友好,给出了错误的答案。
另一方面,ChatGPT-4提供了正确答案:
这一比较揭示了 Gemini Pro 和 GPT-4 在推理和常识方面的显着差距。
这次比较清晰地展示了 Gemini Pro 与 GPT-4 在推理和常识处理能力上的显著差异。
视觉能力
与 GPT-4 一样,Gemini Pro 也是一种多模态模型,具备包括图像识别在内的印象深刻的能力。我使用了 “LMMs黎明:对GPT-4V(ision)的初步探索” 论文中的图片和问题来测试这一点。
当向 Gemini Pro 展示一个特定图像并询问其幽默方面的内容时,其回应并不十分准确。

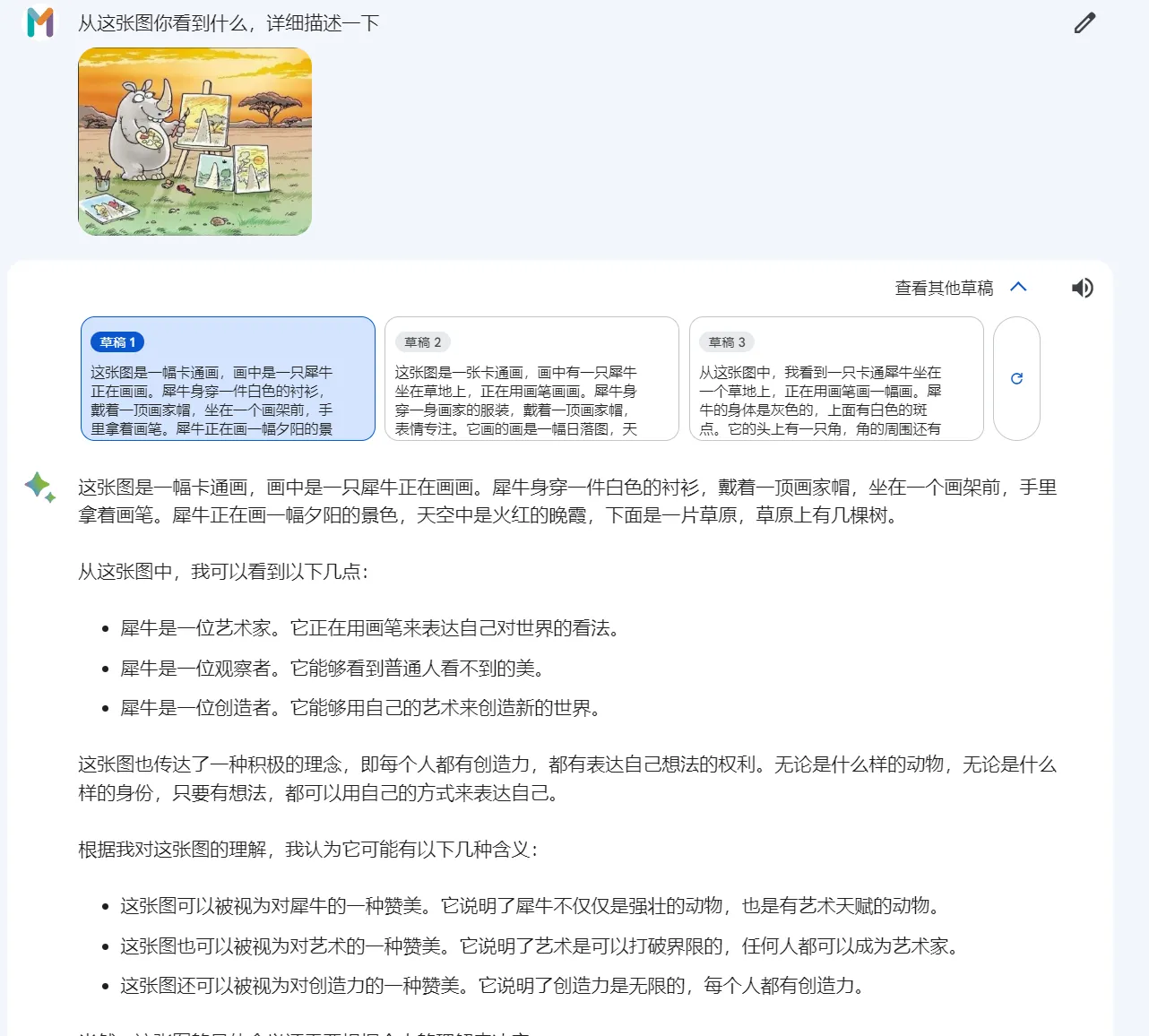
它错误地将犀牛角识别为乌龟,忽略了图像中真正的幽默。
相比之下,GPT-4 表现出了对图像内容和含义的精确理解。

我还测试了他们解读另一个图像的能力,要求他们描述其内容、汉字,并确定食物的原产地城市。

Gemini Pro 的回答是:
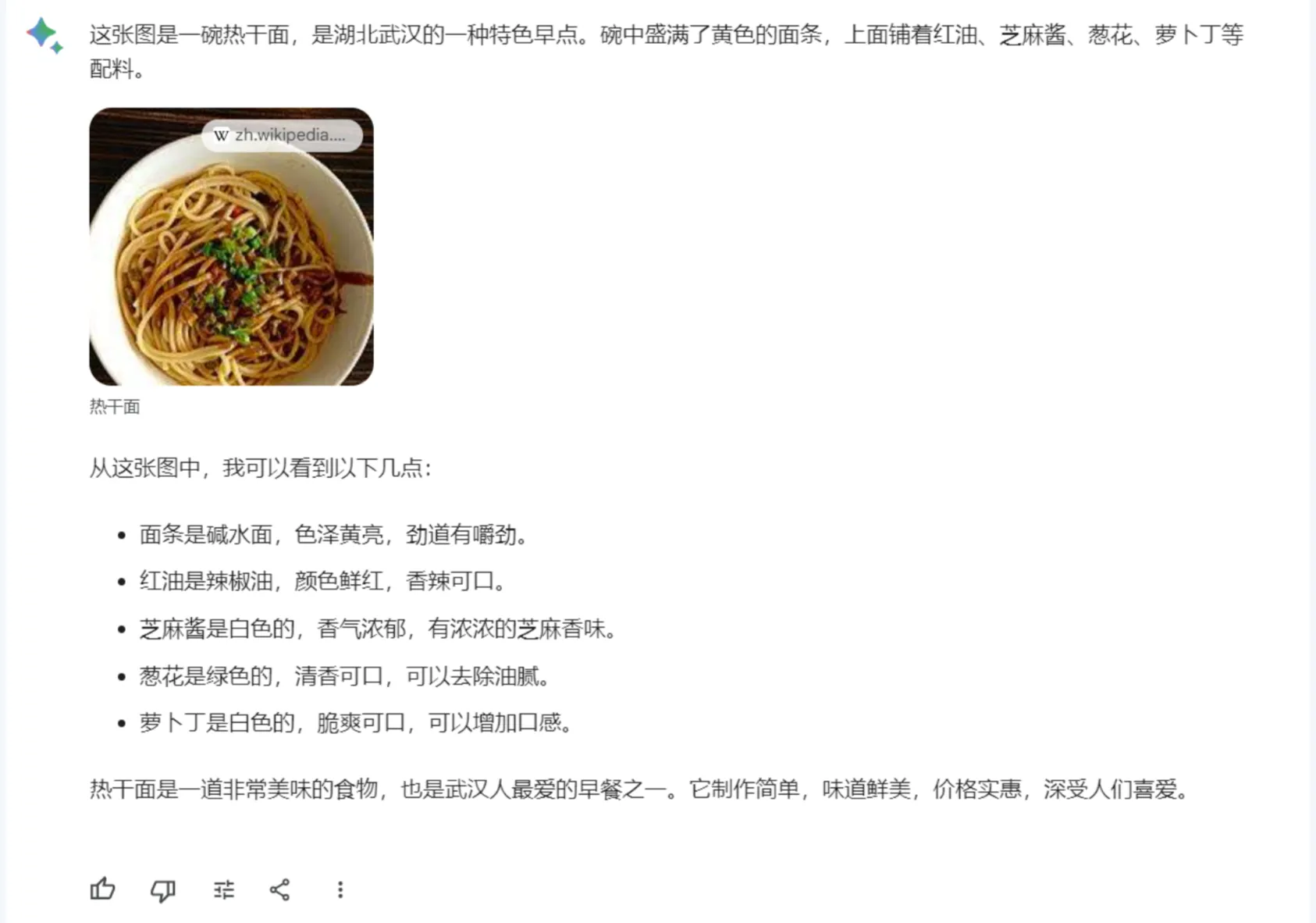 而在相同的测试中,GPT-4 提供了如下的回应:
而在相同的测试中,GPT-4 提供了如下的回应:

这种比较显示出,尽管 Gemini Pro 在多语言处理方面可能更为强大,但 GPT-4 在图像识别和解读方面的表现略胜一筹,对于理解和解释图像内容更为准确。
Token限制
在大型语言模型的应用领域中,Token的容量是一个关键因素。所谓Token容量,指的是模型在一次对话中能够处理和记忆的词汇数量。Token限制越高,模型能够进行的对话就越长久、细节越丰富。
举个例子,当要求模型对一本书进行总结时,它一次能处理的词汇越多,其提供的总结就越全面。在持续对话的情境中,更高的Token限制意味着模型具有更好的记忆能力,使得聊天过程更为流畅和连贯。
在测试中,Gemini Pro的Token限制显著低于GPT-4。举例来说,我曾尝试让它将Sam Altman在OpenAI DevDay上的45分钟演讲转化为一篇文章。但Gemini Pro在处理到30分钟时就已达到其处理极限。
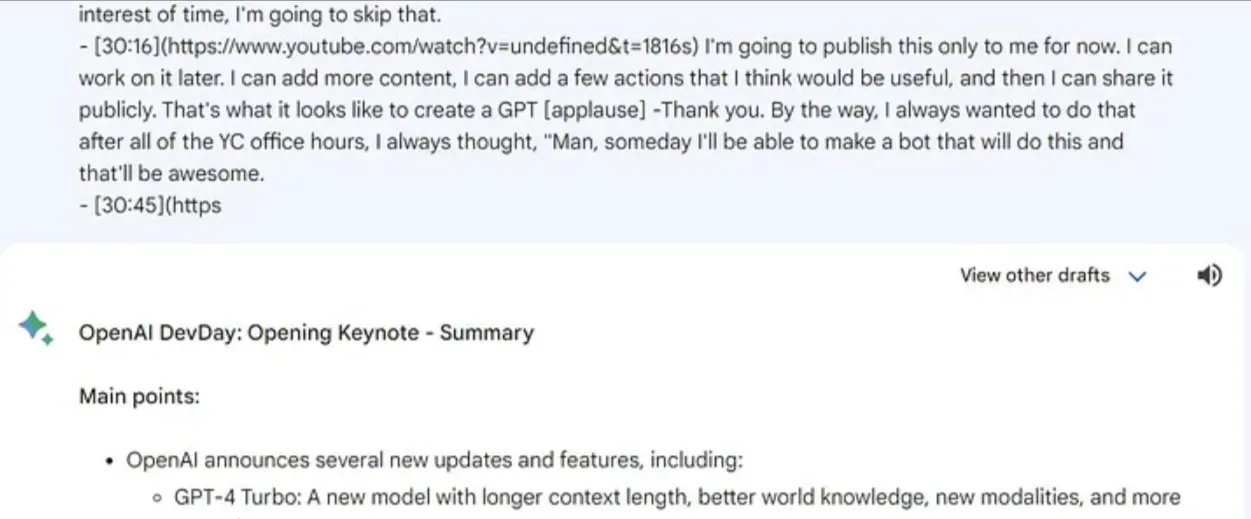
Gemini Pro 在这项任务中处理的总词数大约为5327个词。
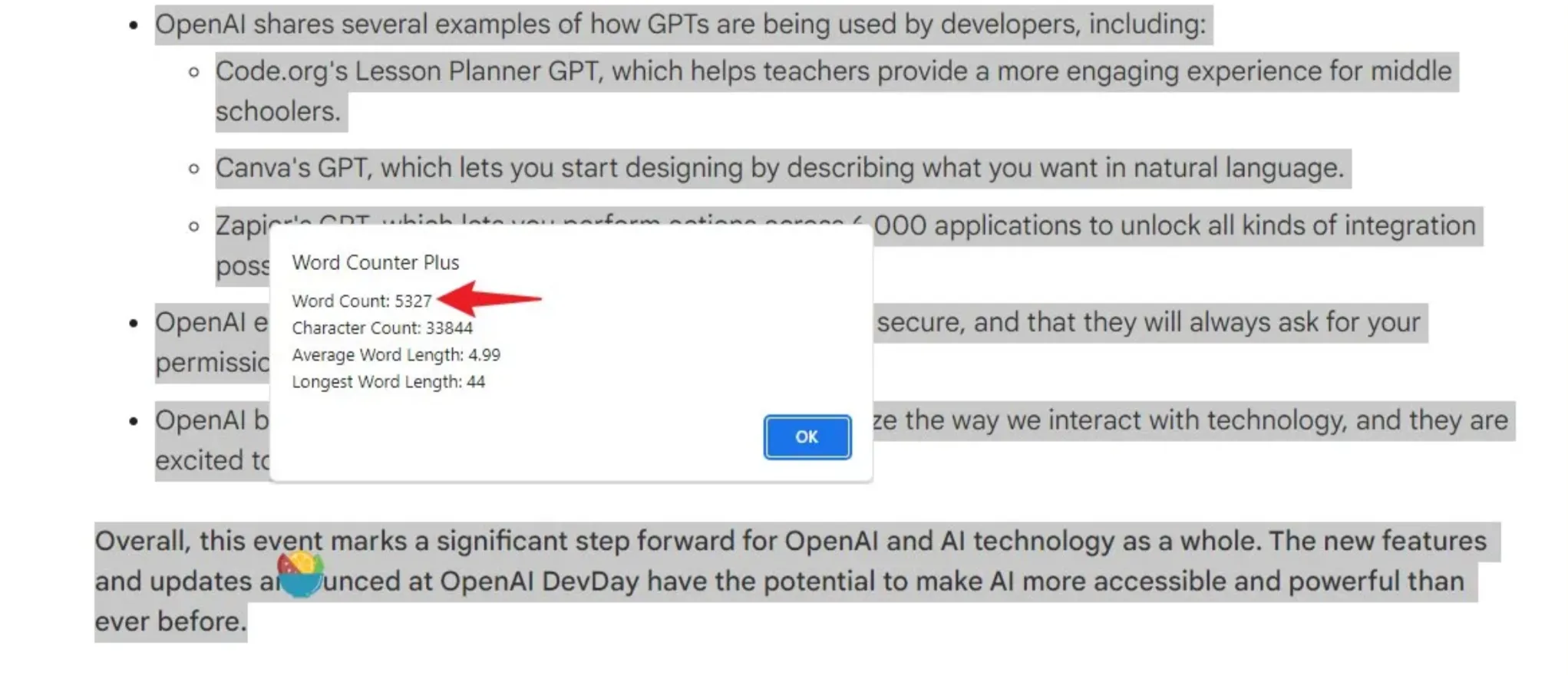
此外,Gemini Pro 还提供了一个非常实用的功能,即用户可以从三种不同的回应中选择一种。通过这种方式,用户可以将回应的总字数增加到大约6000字。

然而,在相同的任务中,ChatGPT-4 的表现非常出色。我向它输入了两个45分钟视频的字幕,并且它轻松地完成了转换任务,处理的单词总数达到了大约17,408个。
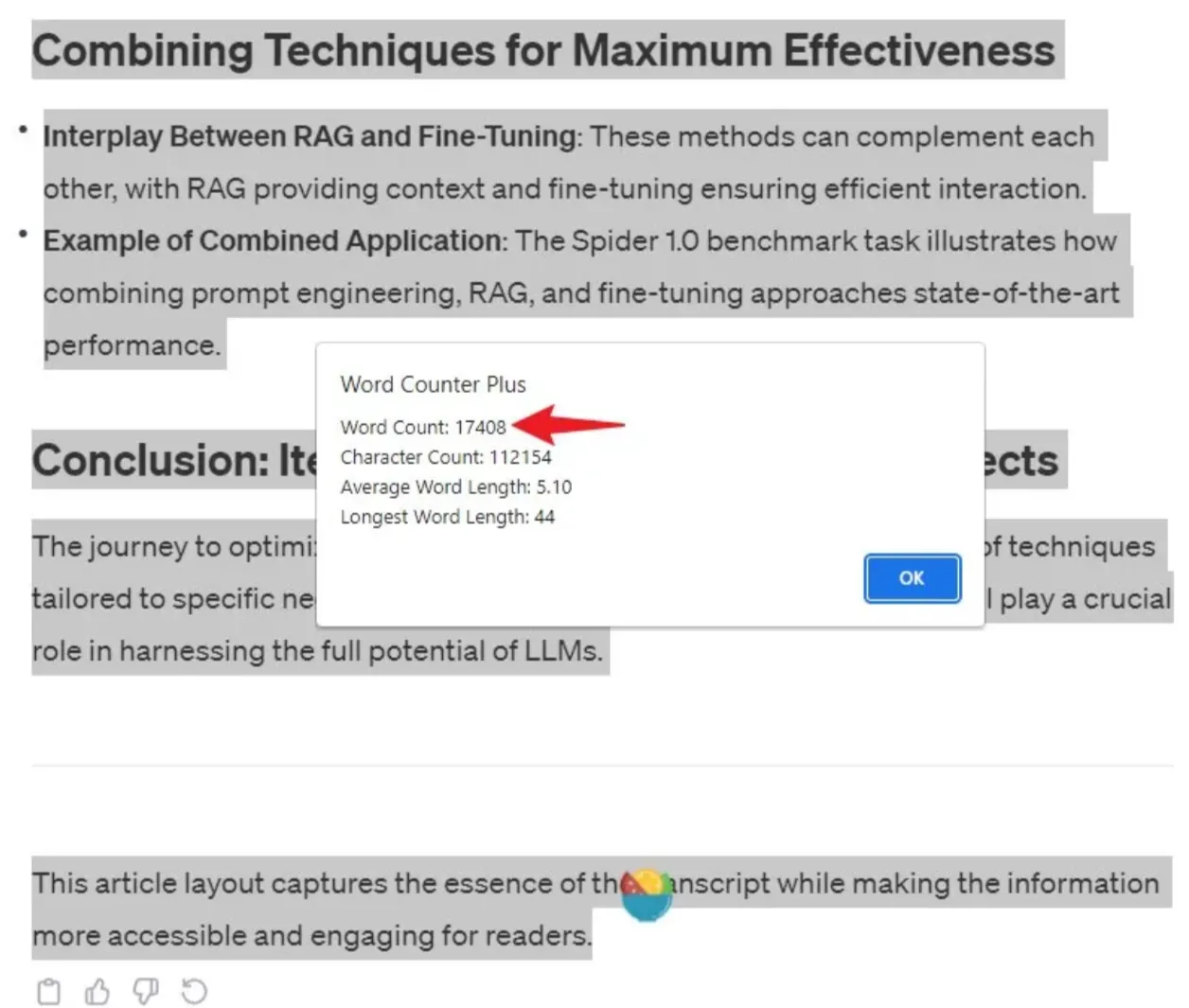
还需注意的是,GPT-4 Turbo 能够在其上下文窗口中处理高达128,000字的大量文本。
长文本摘要的对比
在进行文本摘要的对比时,我们来看看 Gemini Pro 和 GPT-4 的表现如何。
我所设定的任务是将 YouTube 字幕转换成一篇文章。如下图所示,Gemini Pro 采取了对字幕进行直接摘要的方式。
另一方面,虽然 ChatGPT-4 的输出内容较短,但其格式清晰且结构良好。
-kwoj.png)
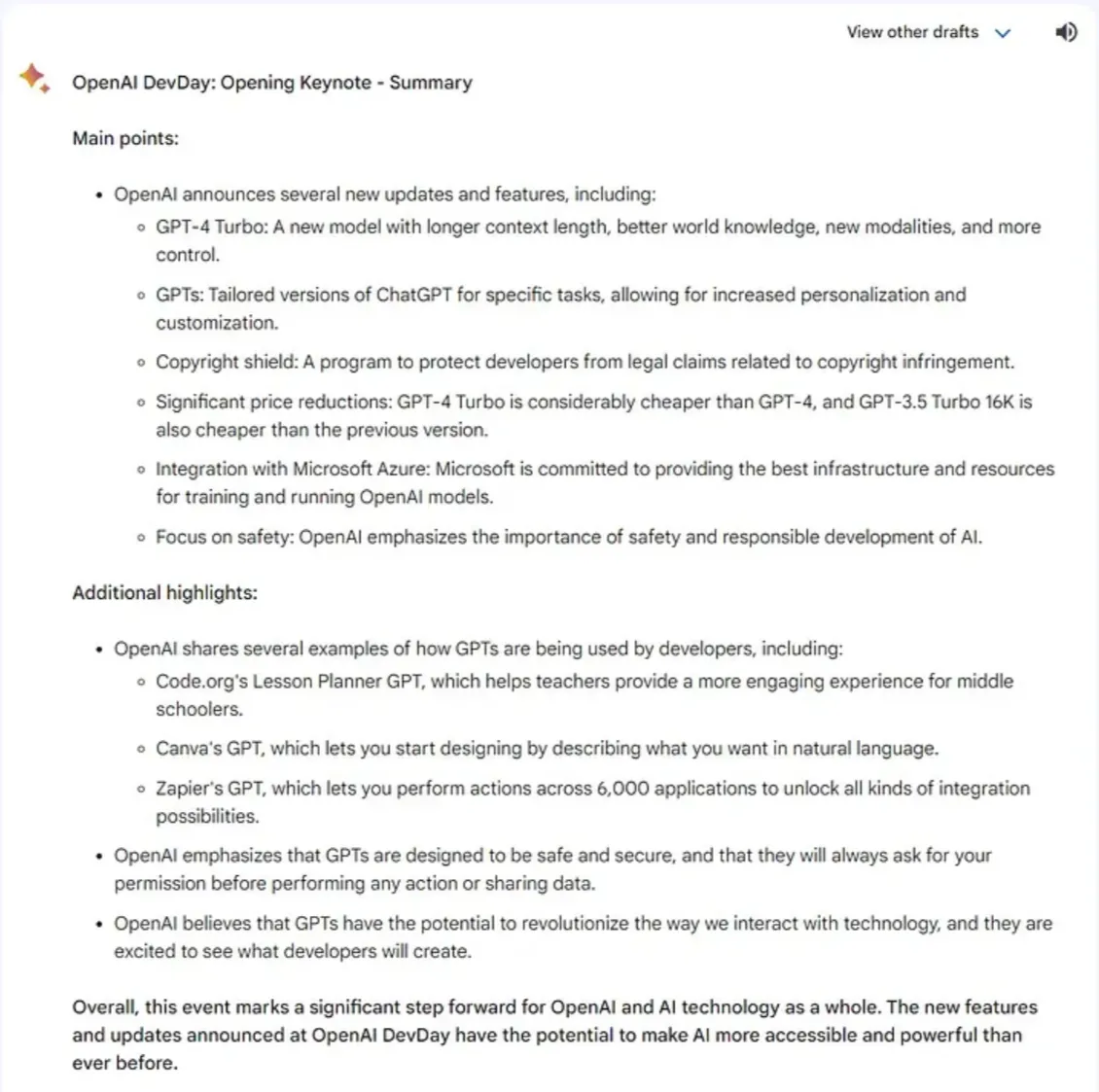
值得一提的是,Gemini Pro 实际上能够直接对 YouTube 视频内容进行摘要。鉴于谷歌是 YouTube 的所有者,这一功能并不令人意外。而且,其生成的摘要质量相当不错。
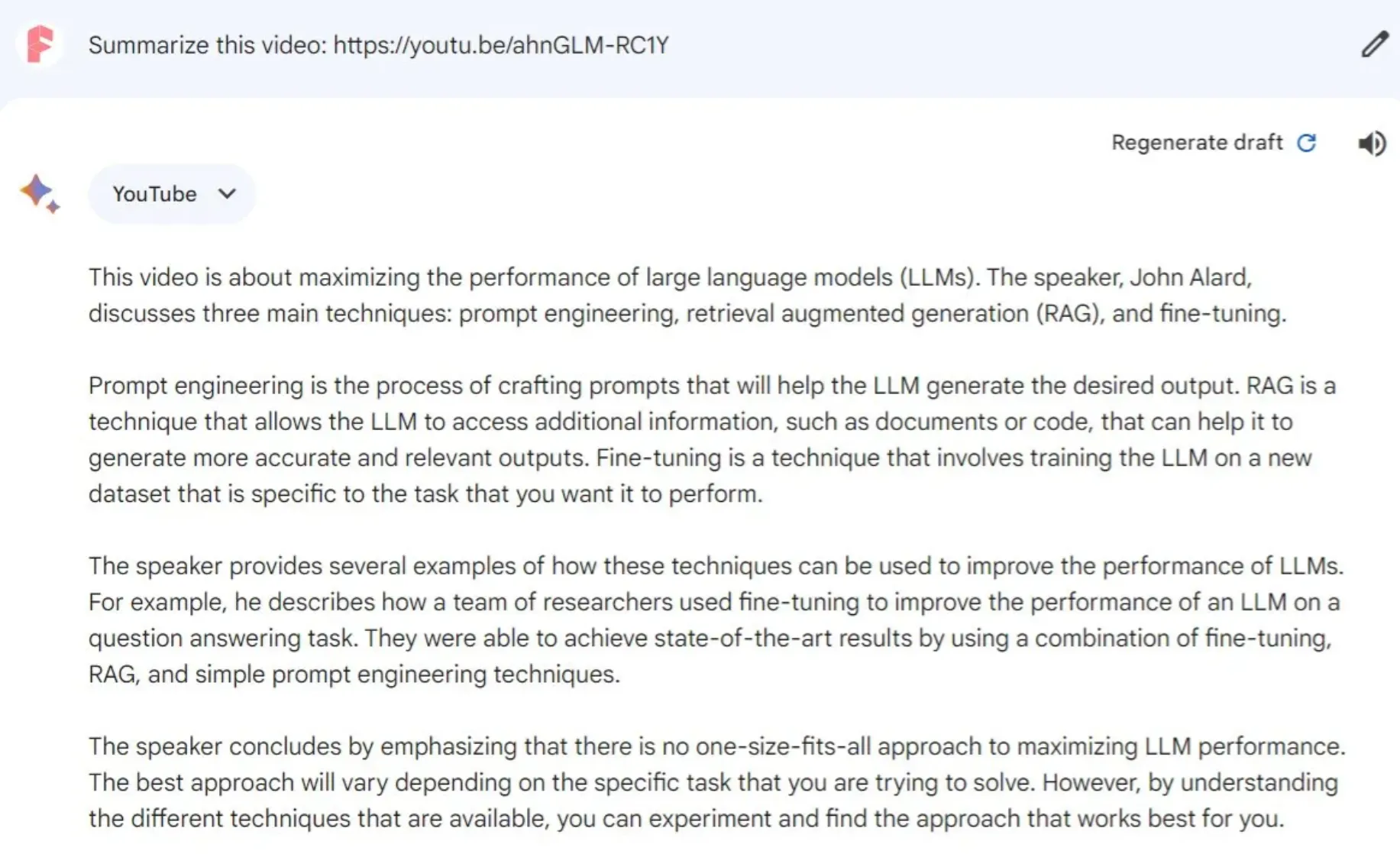
然而,特别是在结合了 VoxScript 插件之后,GPT-4 在摘要 YouTube 视频方面显示出了一定的优势。它生成的摘要包含有清晰的开头、结构化的中间部分以及一个结尾,使得整个内容更加连贯和易于理解。
-beys.png)
从冗长文本中提取关键信息是对任何大型语言模型(LLM)的一次真正考验。到目前为止,在这一领域中,Gemini Pro 略显不及 GPT-4。尽管如此,Gemini Pro 对 YouTube 内容的摘要能力仍然是一个实用的特性。由于 OpenAI 缺乏直接访问 YouTube 的途径,这可能使 Gemini Pro 保持其独特性。
知识更新方面的比较
在11月,OpenAI 对 ChatGPT 进行了重要更新,将其训练数据扩展到了2023年4月,并计划通过持续更新来保持数据的时效性。当我询问 Gemini Pro 关于其最后一次更新的时间时,它的回答含糊且称这是“机密信息”。

出于好奇,我测试了它们对于一个较新话题的掌握程度:如何在 ChatGPT 中创建自己的 GPT 模型。Gemini Pro 给出了不错的回答,但这让我产生了疑问:它的回答是基于自身的训练数据,还是依赖于互联网上的数据。
-cqqq.png)
相比之下,如下图所示,GPT-4的训练数据中并不包含如何创建GPT的相关信息。
-zhov.png)
GPT-4 的网络功能使其能够对同一个问题做出更详细和准确的回答,在这一领域超越了 Gemini Pro。

数学技能
数学技能是大型语言模型推理能力的关键组成部分。以一个具体的不定积分问题为例,这个问题源自加州大学伯克利分校,网上的资料显示它有四个正确答案。

Gemini Pro 在尝试解决这个问题时表现有所不同。在其提供的首个选项输出中,它遗漏了其中一个正确答案。
-eqso.png)
有趣的是Gemini Pro 在其第二个输出选项中,还多出一个答案,哪位小伙伴能帮忙解释是否这个答案是否正确。
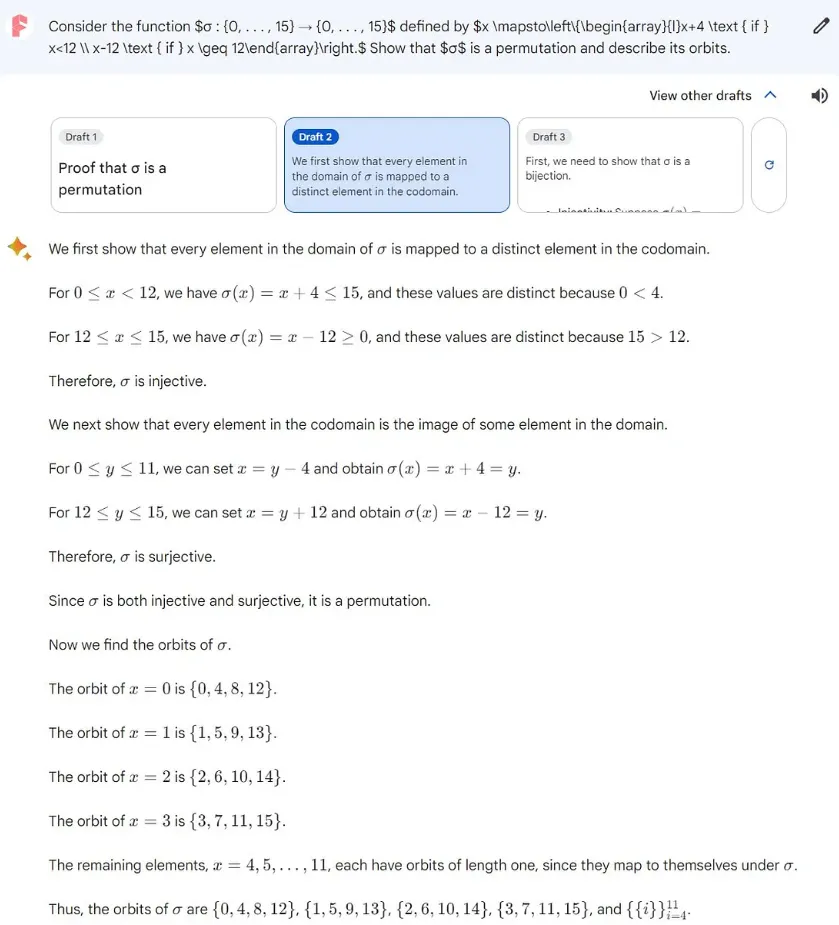
然而,在第三次尝试中,Gemini Pro 的答案完全偏离了正确答案。
相比之下,GPT-4 则展现了其能力,成功提供了正确标准答案。

这个测试清晰地展现了 GPT-4 在数学和推理能力方面相比于 Gemini Pro 的优势。
网络搜索能力
在复杂的网络搜索任务中,Gemini Pro 的表现让我印象深刻!我用以下特定的请求来测试它的能力:
为一家虚构的消费品公司研究可持续包装解决方案。请识别前三家可持续包装供应商,并提供一份关于他们的产品、定价和环境影响的报告。
在这项任务中,Gemini Pro 的表现非常出色。
.png)
特别值得一提的是,Gemini Pro 能够将信息高效地总结成表格格式,并且这些表格可以轻松地下载到 Google 表格中,这一功能极为便捷!

另一方面,在这一领域,GPT-4 的本地网络搜索能力显得不足。即便是在使用了 WebPilot 插件后,GPT-4 也未能达到 Gemini Pro 的表现水平,它在生成表格和访问某些数据(例如价格信息)方面存在一定的局限。

在网络搜索这一方面,Gemini Pro 凭借谷歌强大的搜索引擎背景,对 GPT-4 构成了实质性的挑战。这对微软和 OpenAI 来说是一个警示,提示他们需要在网络搜索能力方面进一步提升。
总结
Gemini Pro 标志着相比其前身 Bard 的一次重大飞跃。虽然 Bard 在特定场合(如地图阅读)有其用途,但 Gemini Pro 提供了更多功能。尽管它还未能达到 GPT-4 的水平,但在几个关键领域已明显超越了 GPT 3.5。
一个关键的问题是:Gemini Ultra 与 GPT-4 相比将会表现如何?我认为,它可能仍会稍逊于 GPT-4。
对于用户来说,像 Gemini 这样的免费工具,以及 ChatGPT 和 Claude 2 的可用性,无疑是巨大的胜利。这是 AI 领域激动人心的时刻,每一次新的进展都带来了更多的多样性和实用性。
性能指标 | GPT-4 | Gemini Pro |
|---|---|---|
推理能力 | 高效准确,友好解决逻辑问题 | 较差,答案有时不够精确 |
视觉能力 | 准确理解和解释图像内容 | 在图像识别和解释方面不如 GPT-4 |
Token限制 | 处理长文本能力强,例如可处理约17,408字的文本 | 相对较低的Token限制,处理大文本时可能达到极限 |
长文本摘要 | 结构清晰、连贯 | 能对 YouTube 视频进行摘要,但文本摘要略逊一筹 |
知识更新 | 更新至2023年4月 | 最后更新时间不明确 |
数学技能 | 解决数学问题表现出色 | 在数学问题解答中有波动 |
网络搜索能力 | 在网络搜索方面存在局限 | 强大的网络搜索能力,优于 GPT-4 |
总体评价 | 多领域表现优越,尤其在文本处理和逻辑推理方面 | 在网络搜索等特定领域表现优异 |