




如果我们无法测量它,我们就无法改进它
在使用检索增强生成(RAG)技术的过程中,我们面临一个共同的挑战:缺乏有效的方法来客观评估RAG的搜索效果。与所有机器学习模型相同,在RAG技术投入日常使用之前,我们必须对其性能进行严格的测试和监控。这一步骤非常关键,因为它允许工程师根据评估结果来判断是否需要对模型进行调整或者重新训练。
尽管关于检索增强生成(RAG)聊天机器人的成功案例落地,但很少有研究深入探讨如何准确评估RAG的实际效果。这背后有两个原因。第一:这些模型的评估通常需要依赖人工标注数据,这种方法不仅耗时而且难以在大规模上实施;第二:为特定应用领域构建高质量的基准数据集也面临诸多挑战。
在RAG系统中,文档检索基本上是一个相似性搜索过程。在这种搜索系统中,我们通常使用NDCG(归一化折损累积增益)评分来评估搜索结果的质量。
需要注意的是,我们在进一步测试中发现,虽然GPT-4生成的内容看起来很有道理,但有时它的相关性评分可能不够稳定。因此,我们可以考虑采用其他的算法来改善这个问题,比如使用余弦相似度、语义相似度度量,或者基于图的方法。此外,为了更好地评估RAG的表现,我们还可以利用人工标注的方法,或者使用像BERI这样的专门的标注数据集来帮助我们。这样的方法能帮助我们更准确地评估模型的效果。
1、NDCG 是什么
NDCG(归一化折损累积增益)是一种评价排序质量的指标,广泛用于衡量搜索、推荐系统等信息检索系统的效果。国外谷歌、亚马逊和Spotify等大企业都在使用NDCG。
NDCG主要用来评估一个排名列表的顺序与列表中各项目实际相关性的一致性。它强调最相关的项目应该排在列表的最前面,同时也注意到列表越往后,项目的相关性可能逐渐降低。NDCG通过将实际得到的排序效果(DCG)与理想状态下的排序效果(IDCG)进行比较并标准化,从而提供了一种不受项目数量和评分标准影响的衡量方式。这样,无论在何种情况下,NDCG都能为不同的搜索或推荐系统提供一个公平的性能评估。
2、核心框架
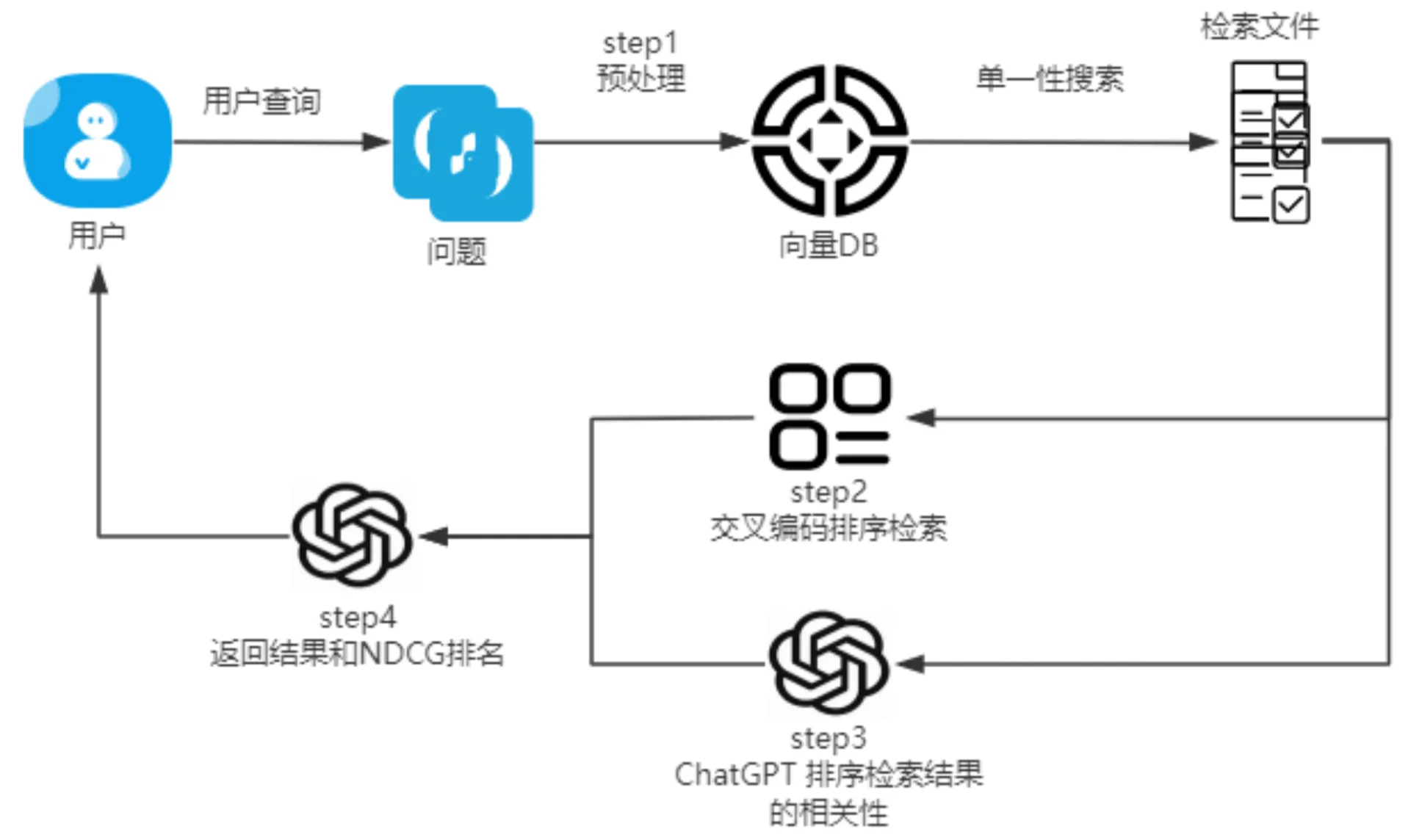
今天我们将介绍一种名为prompt工程的技术,这种技术可以通过GPT-4 API自动对查询和回答的相关性进行排名,而不需要手动检索结果。
在生产环境中,我们常用一种叫做交叉编码的方法来对相同的查询和检索结果进行重新排序。接着,我们会用两个排名分数来计算NDCG(归一化折损累计增益)分数,这个分数越高,表示我们检索到的内容与查询的相关性越强。这样的方法不仅效率高,而且能够提供更精确的结果。
在模型评估过程中,我们通常会计算训练集和验证集中NDCG分数的平均值。这个平均分可以帮助我们评估模型在开发阶段和生产阶段的表现。
可能有小伙伴会好奇,为什么不直接使用GPT-4 API来对检索结果进行排序,而是选择使用交叉编码(基于BERT的模型)。这主要是因为成本考虑:目前GPT-4的使用费用是GPT-3.5 Turbo的60倍,而且GPT-3.5的效果并不总是满意的。此外,GPT-4 API的调用过程是串行的,这意味着在处理大量数据时可能会有较高的延迟。相比之下,交叉编码模型是开源的,支持并行处理,因此在实际应用中可以达到更低的延迟。
3、示例案例
示例 1. 提出相关问题
#query = "What was total revenue of 2023?"
pairs= create_query_retrival_pairs(query)
output = rag(query=query, retrieved_documents=retrieved_documents)
print(word_wrap(output))
在这里,它展示了所有相关文档的结果
Total revenue for 2023 was $96,773 million.
还报告了各个文档的相关性排名和得分。两个交叉编码器都预测认为第三个文档最相关。而GPT-4则认为最后一个文档是第二相关的,交叉编码器则把第一个文档排在了第二位。整体来看,NDCG得分为0.76,这是一个相当不错的表现!

示例 2:不相关的问题。
query = "What was linonel messi contribution?"
pairs= create_query_retrival_pairs(query)
output = rag(query=query, retrieved_documents=retrieved_documents)
print(word_wrap(output))
返回答案
The information provided does not specify Lionel Messi's contribution.
It seems to be related to revenue recognition, specifically in the
automotive sales and leasing segments of the company. If you have a
specific question related to revenue recognition or financial
information, feel free to ask, and I will assist you further.
交叉编码器必须返回相关性分数;然而,GPT-4非常确定查询中没有任何内容是相关的,因此将所有分数都返回为0。实际上,GPT-4的判断是正确的——NDCG分数也为0。这表明GPT-4对于判断内容相关性的准确性非常高。

示例 3:棘手的问题。
我们来问一个棘手的问题。虽然答案很有道理,但……(好像答非所问)
query = "Is Elon Musk genius or not?"
pairs= create_query_retrival_pairs(query)
output = rag(query=query, retrieved_documents=retrieved_documents)
print(word_wrap(output))
Based on the information provided from the annual report, there is no
specific mention or indication regarding whether Elon Musk is a genius
or not. The information in the annual report mainly focuses on the
company's financial data, revenue sources, revenue recognition
practices, and other related financial details. It does not contain any
assessment or opinion on Elon Musk's personal achievements,
intelligence, or character.
然而,由于两个模型的排名结果非常接近,NDCG得分高达0.95。但我们不能仅仅因为这个高分就认为结果完全可靠。

我们还需要进一步改善方法,以便能够从GPT-4中更可靠地获取排名分数。另一种可能更有效的方式是使用人工标记或者已经建立好的标记数据集来进行评估。
代码演示
步骤 1:预处理,包括从PDF文件中拆分和标记内容,创建嵌入,并建立ChromaDB向量数据库集合。
# Load the 2023 Tesla 10K report
NeedRefreshVDB=False
if NeedRefreshVDB:
reader = PdfReader("../data/tesla10K.pdf")
pdf_texts = [p.extract_text().strip() for p in reader.pages if p.extract_text()]
# Split text by sentences
character_splitter = RecursiveCharacterTextSplitter(separators=["\n\n", "\n", ". ", " ", ""], chunk_size=1000, chunk_overlap=0)
character_split_texts = character_splitter.split_text('\n\n'.join(pdf_texts))
# Tokenize the sentence chunks
token_splitter = SentenceTransformersTokenTextSplitter(chunk_overlap=0, tokens_per_chunk=256)
token_split_texts = [token_split_text for text in character_split_texts for token_split_text in token_splitter.split_text(text)]
# Create embeddings
embedding_function = SentenceTransformerEmbeddingFunction()
# Create vector database using ChromaDB collection
chroma_client = chromadb.Client()
chroma_collection = chroma_client.create_collection("tesla202310k", embedding_function=embedding_function)
ids = [str(i) for i in range(len(token_split_texts))]
chroma_collection.add(ids=ids, documents=token_split_texts)
else:
# Load existing vector database # improvement 1
embedding_function = SentenceTransformerEmbeddingFunction()
chroma_client = chromadb.Client()
vectordb = chroma_client.get_collection("tesla202310k",
embedding_function=embedding_function)
步骤 2:创建查询-答案对并使用交叉编码器进行排序
将检索到的文档与查询配对形成对,然后使用交叉编码器对这些对进行排名。在这个过程中,我们采用了开源模型“ms-marco-MiniLM-L-6-v2”。这个排名分数会被转换成相关性分数;排名越高,表示相关性越强。
from sentence_transformers import CrossEncoder
def rank_relevancy_pairs ( pairs ):
topN= 5
# 使用特定的预训练模型初始化 CrossEncoder
cross_encoder = CrossEncoder( 'cross-encoder/ms-marco-MiniLM-L-6-v2' )
# 使用 CrossEncoder 预测对的分数 scores
= cross_encoder.predict(pairs)
# 通过按降序对分数索引进行排序来选择排名前 5 位的答案
top_indices = np.argsort(scores)[::- 1 ][:topN] # 仅选择前 5 名
# 将相关性分数从 4 分配到 0(或根据列表长度更少)
predicted_relevance = [ 0 ] * topN
for rank, index in enumerate (top_indices):
predicted_relevance[index] = topN- 1 - rank # 根据分数数量进行调整
# 检索前 5 名根据这些索引生成 5 对
top_pairs = [pairs[index] for index in top_indices]
return top_indices, predictive_relevance, top_pairs
步骤 3:使用 GPT-4 进行相关性排序
通过设计的prompt,将相同的查询和答案对转换成相关性分数。
def true_relevancy(pairs, model="gpt-4"):
relevancy_scores = [0]*5
# for question, answer in pairs:
messages = [
{
"role": "system",
"content": (
"You are a helpful expert text processing expert.\n"
"- Return relevancy ranking for each of the provided pairs in a simple list format"
"- each value corresponds to the relevancy score between 0 and 4 for each pair in the order they were presented.\n"
"- Rate the relevancy of the answer to the question on a scale of 0 to 4, where 4 is highly relevant and 0 is not relevant at all.\n"
"- there is no duplicated relevancy score \n"
"- return answer into a list no explaination\n"
"Answer the user's question using only this information."
)
},
{"role": "user", "content": f"Question and answer pairs are {pairs}. \n "}
]
response = openai_client.chat.completions.create(
model=model,
messages=messages,
)
# Extract the relevancy score from the response
try:
# Assuming the response is a single digit or a simple number
relevancy_scores=response.choices[0].message.content
print(f'evaluated by chatGPT4: relevancy score is:{relevancy_scores}')
except Exception as e:
print(f"Error parsing response: {e}")
# Append a default score or handle error appropriately
relevancy_scores=[0,0,0,0,0]
return relevancy_scores
步骤4:计算NDCG分数
NDCG 通过使用 GPT-4 生成的交叉编码和相关性分数来评估相关性排名,并计算返回 NDCG 分数。在这里我们进行了五次检索来进行评估。
# 计算 NDCG 的函数
def ndcg ( scores, ideal_scores, k ):
dcg = lambda scores: sum (( 2 **score - 1 ) / np.log2(idx + 2 ) for idx, score in enumerate (scores[:k]))
actual_dcg = dcg(scores)
ideal_dcg = dcg( sorted (ideal_scores, reverse= True ))
return actual_dcg / ideal_dcg if ideal_dcg > 0 else 0
RAG 功能将查询和检索到的文档结合起来,然后发送给 GPT-3.5-Turbo 以生成答案。
# Use LLM (OpenAI API) to answer human query
# %%
def rag(query, retrieved_documents, model="gpt-3.5-turbo"):
information = "\n\n".join(retrieved_documents)
messages = [
{
"role": "system",
"content": "You are a helpful expert financial research assistant. Your users are asking questions about information contained in an annual 10K report."
"You will be shown the user's question, and the relevant information from the annual report. Answer the user's question using only this information."
},
{"role": "user", "content": f"Question: {query}. \n Information: {information}"}
]
response = openai_client.chat.completions.create(
model=model,
messages=messages,
)
content = response.choices[0].message.content
return content
output = rag(query=query, retrieved_documents=retrieved_documents)
print(word_wrap(output))
最后,有必要增加一个辅助函数来创建查询和答案对。这个函数的作用是构建查询和答案对,以便进行重新排序。
# -----------------create pairs -----------------------
def create_query_retrival_pairs(query):
results = chroma_collection.query(query_texts=[query], n_results=5)
retrieved_documents = results['documents'][0]
pairs = []
for doc in retrieved_documents:
pairs.append([query, doc])
return pairs