




在现有市场上,使用检索增强生成(Retrieval-Augmented Generation,简称RAG)的应用中,我们发现未经处理的“幻觉”问题仍然非常严重。为了解决这个问题,我在实际操作中对四个公开的RAG数据集进行了详细评估,使用了流行的幻觉检测工具进行测试。在这里,我主要用到了AUROC(即接收者操作特征曲线下的面积)和精确度/召回率这两种指标来衡量检测效果。
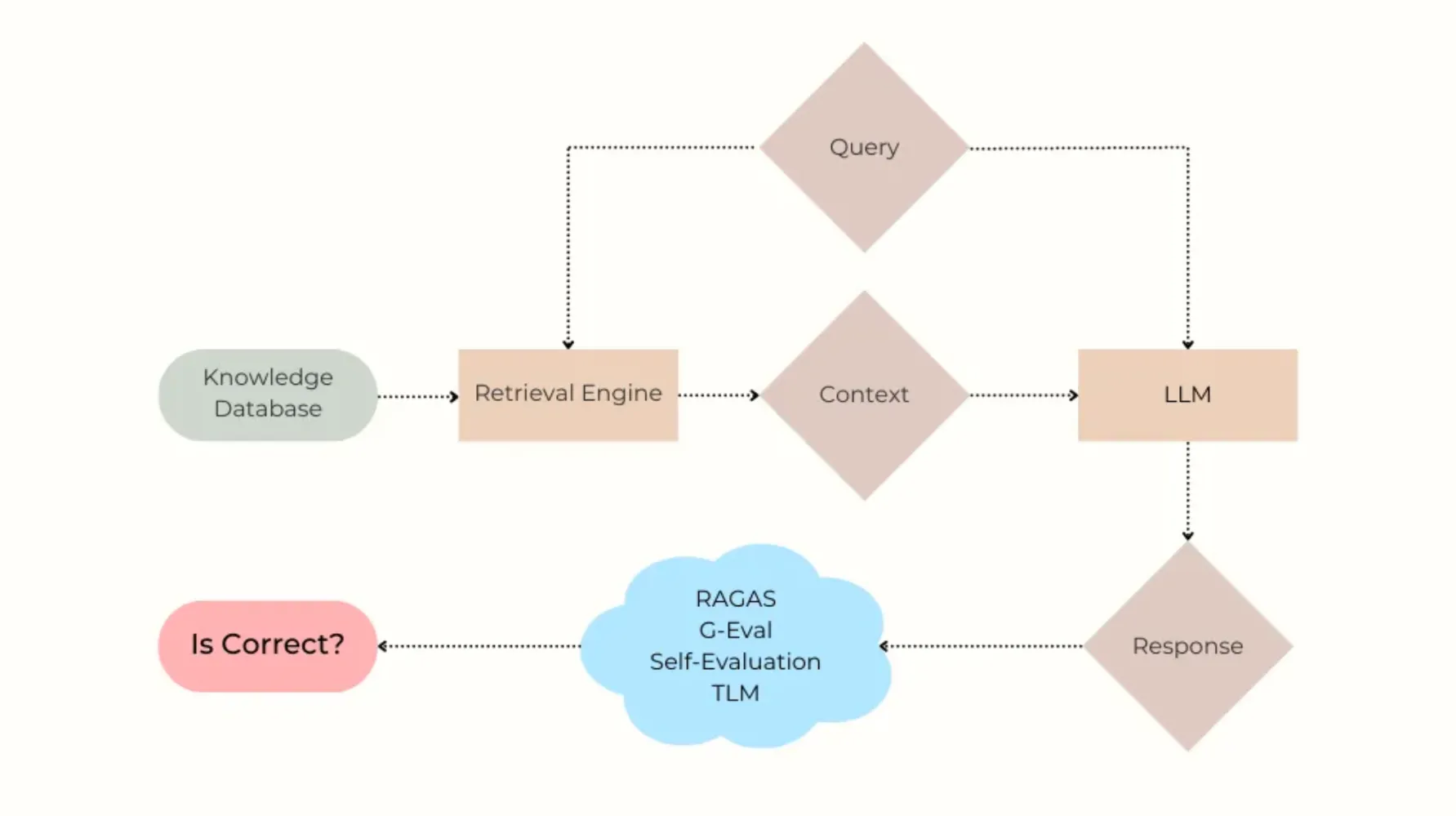
具体来说,我测试了几种幻觉检测方法,比如G-eval、Ragas和信任语言模型(Trustworthy Language Model)。这些方法的主要任务是自动识别和标记大型语言模型(LLM)中的错误响应。在本文中,我将详细介绍这些方法的表现如何,以及它们在实际应用中的效果和局限。通过这些分享,希望能为大家在使用RAG技术时提供一些参考和帮助。
1、背景:检索增强生成系统中的幻觉和错误
大模型(LLM)处理训练数据未涵盖的问题时,可能会给出错误答案。为了缓解这个问题,检索增强生成(RAG)系统应运而生,它赋予了大模型从特定知识库中检索内容和信息的能力。虽然许多企业正在快速采用这项技术,希望将大模型的强大功能与其专有数据结合起来,但幻觉和逻辑错误仍然是一个不容忽视的难题。
例如,在前端时间国外的一个案例中,加拿大航空公司的RAG聊天机器人就曾错误地处理了退款政策的重要细节,最终导致该公司在一场法律诉讼中败诉。
要理解这个问题,我们得明白检索增强生成(RAG)系统是如何工作的。当用户提出一个问题,比如说:“这是否符合退款资格?”时,系统的检索部分会在知识数据库中搜索必要的信息来回答这个问题。系统会挑选出最相关的信息,将其整理成一个上下文,然后这个上下文连同用户的问题一起输入到大型语言模型(LLM)中。由LLM生成的回答最终呈现给用户。但是,因为企业级的RAG系统通常比较复杂,最终的回答可能由于多种原因而出现错误,具体包括:
大模型(LLM)本身脆弱并容易产生所谓的“幻觉”。即便检索到的上下文包含了正确的答案,LLM在生成回应时也可能不准确,特别是当需要在上下文中的不同事实之间进行推理时。
有时检索到的上下文可能并不包含足够的信息来准确回答问题,这可能是因为搜索的质量不高、文档的分块或格式处理不当,或是知识库本身就缺少相关信息。在这种情况下,LLM仍可能尝试回答问题,但很可能会生成错误的幻觉答案。
虽然有些人认为“幻觉”这个词只适用于描述大模型(LLM)的某些特定错误,但在这里,我们把它当作错误响应的同义词来使用。对于使用检索增强生成(RAG)系统的用户来说,他们最关心的是答案的准确性和可信度。不像那些评估RAG系统多个属性的基准测试,本文主要集中在检测器识别错误答案的有效性上。
RAG系统提供的答案出错,可能是因为检索或生成过程中的问题。我更专注于后者,也就是大模型本身的根本不可靠性问题。这种焦点可以让我们更加深入地理解和改进系统,以提高其整体的准确性和可靠性。
2、解决方案:幻觉检测方法
假定我们的检索系统已经找到了与用户问题最相关的上下文,接下来我们需要关注的是如何判断基于这些上下文由大模型(LLM)生成的回答是否可靠。特别是在医疗、法律或金融等高风险领域,这种幻觉检测方法显得非常重要。这些方法不仅可以帮助我们标记出那些不可信的回答,便于进行更细致的人工审核,还可以帮助我们决定是否需要采取更高成本的检索措施,比如搜索额外的数据源或重写查询等。
在我们的实际项目中,我们考虑了以下几种基于大模型(LLM)的幻觉检测方法,用以评估生成的回答:
2.1、自我评估(“Self-eval”)
自我评估(“Self-eval”)是一个看似简单却实用的技术。通过这项技术,我们让大型语言模型(LLM)自我评估它生成的答案,并在1到5的利克特量表上给出置信度评分。为了提高评估的准确性,我们采用了“思维链”(Chain of Thought, CoT)的提示方式,这要求LLM在给出最终的评分前,先详细解释它对置信度的看法。具体的提示模板如下:
问题:{question}
回答:{response}
请评估你对给定答案作为对问题的良好和准确回应的置信度。使用以下5点量表来分配一个分数:
1:你对答案根本不解决问题没有信心,答案可能完全偏题或与问题无关。
2:你对答案解决问题的信心较低,对答案的准确性存在疑问和不确定性。
3:你对答案解决问题有适度的信心,答案看起来相当准确且切题,但仍有改进空间。
4:你对答案解决问题有较高的信心,答案提供了解决问题大部分的准确信息。
5:你对答案解决问题极为自信,答案非常准确、相关,并有效地完整解决了问题。
输出应严格使用以下模板:解释:[简要说明推导评分的理由],在最后一行写上‘得分:<评分>’。
2.2、G-Eval
G-Eval(源自DeepEval包)是一种采用思维链(CoT)自动发展多步骤标准来评估响应质量的方法。在G-Eval的研究论文(由Liu等人撰写)中,这种技术被证实与人类的判断在多个基准数据集上有所相关。这里的质量评估可以通过多种方式进行,我们特别指出,应基于响应的事实正确性来进行评估。以下是实施G-Eval评估时使用的标准:
判断输出在给定上下文中的事实是否正确。
2.3、幻觉度量(Hallucination Metric
幻觉度量(Hallucination Metric)(源自DeepEval包)用于估计幻觉的可能性,即LLM生成的回应与上下文的矛盾或不一致程度。这一度量是由另一个LLM来进行评估的。
2.4、RAGAS
RAGAS是一个针对检索增强生成(RAG)系统的、由LLM驱动的评估套件,它提供了多种可以用来检测幻觉的分数。我们关注以下几种由LLM估计并生成的RAGAS分数:
忠实度(Faithfulness) —— 答案中的声明有多大比例是由提供的上下文所支持的。
答案相关性(Answer Relevancy) —— 原始问题的向量表示与答案中由三个不同LLM生成的问题的向量表示之间的平均余弦相似度。这里的向量表示是使用BAAI/bge-base-en encoder的嵌入来完成的。
上下文利用率(Context Utilization) —— 衡量LLM生成的回应在多大程度上依赖于提供的上下文。
2.5、可信语言模型(Trustworthy Language Model, TLM)
可信语言模型(Trustworthy Language Model, TLM)是一种用来评估大型语言模型(LLM)回应可信度的模型不确定性评估技术。这种技术结合了自我反思、从多个样本回应中寻找一致性,以及利用概率测量来识别错误、矛盾和幻觉。以下是用来引导TLM的模板:
请仅使用以下上下文中的信息来回答问题:
上下文:{context}
问题:{question}
3、评估方法
我们计划在四个不同的公共上下文-问题-答案数据集上测试上述的幻觉检测方法,这些数据集代表了多种检索增强生成(RAG)的应用场景。
在我们的基准测试中,针对每个用户问题,现有的检索系统都会返回一些相关上下文。这些用户查询和上下文将被输入到一个生成型大型语言模型(LLM)中(通常还会加上特定应用系统的提示),以生成对用户的回应。每一种检测方法都会接收到{用户查询,检索到的上下文,LLM生成的响应}这三项数据,并基于这些信息返回一个介于0到1之间的分数,用以表示产生幻觉的可能性。
为了评估这些幻觉检测器的效果,我们特别关注这些分数在大模型(LLM)的响应正确与错误时的区分能力。在我们进行的每一个基准测试中,都有关于每个LLM响应正确性的真实评注,这些评注仅用于评估目的。我们采用AUROC(接收者操作特征曲线下的面积)来评估幻觉检测器的性能,这个指标反映了检测器将LLM的错误响应分数定低于正确响应分数的概率。AUROC值越高的检测器,在实际应用中捕捉RAG错误的能力越强,从而能更精确地提高准确率和召回率。
考虑到所有的幻觉检测方法都是由LLM驱动的,为了保证比较的公平性,我们将所有方法使用的LLM模型统一定为gpt-4o-mini。这样可以确保不同方法之间的比较是在相同的技术基础上进行的。
4、基准测试结果
我们在下面描述了每个基准数据集及其对应的结果。这些数据集源自广受欢迎的HaluBench基准测试套件(我们没有包括此套件中的其他两个数据集,因为我们发现它们的真实注释中存在重大错误)。
4.1、PubMedQA
PubMedQA 是一个围绕 PubMed 摘要构建的生物医学问答数据集。每个数据集实例都包含一个来自 PubMed(医学出版物)的段落,一个从该段落衍生的问题,比如:“9个月的治疗对结核性小肠炎足够吗?”以及一个相应的生成答案。

在这个基准测试中,TLM(可信语言模型)是识别幻觉最有效的方法,其次是幻觉度量、自我评估和 RAGAS 忠实度。在这后三者中,RAGAS 忠实度和幻觉度量在捕捉不正确答案方面的准确性更高(RAGAS 忠实度的平均准确率为 0.762,幻觉度量的平均准确率为 0.761,自我评估的平均准确率为 0.702)。这些结果指出,在这类生物医学问题上,不同的幻觉检测方法有着各自的优势和局限。
4.2、DROP
DROP,全称为“段落上的离散推理”,是一个围绕维基百科文章建立的高级问答数据集。这个数据集的难度在于,它要求用户不仅仅是从文章中提取事实,而是需要进行更深层次的推理。例如,考虑一个描述NFL海鹰队与49人队比赛中触地得分情况的维基百科段落,可能会有这样一个问题:“总共有多少次触地得分的跑动不超过5码?”这就需要LLM阅读并理解每一次触地得分的距离,并将其与5码的标准进行比较。
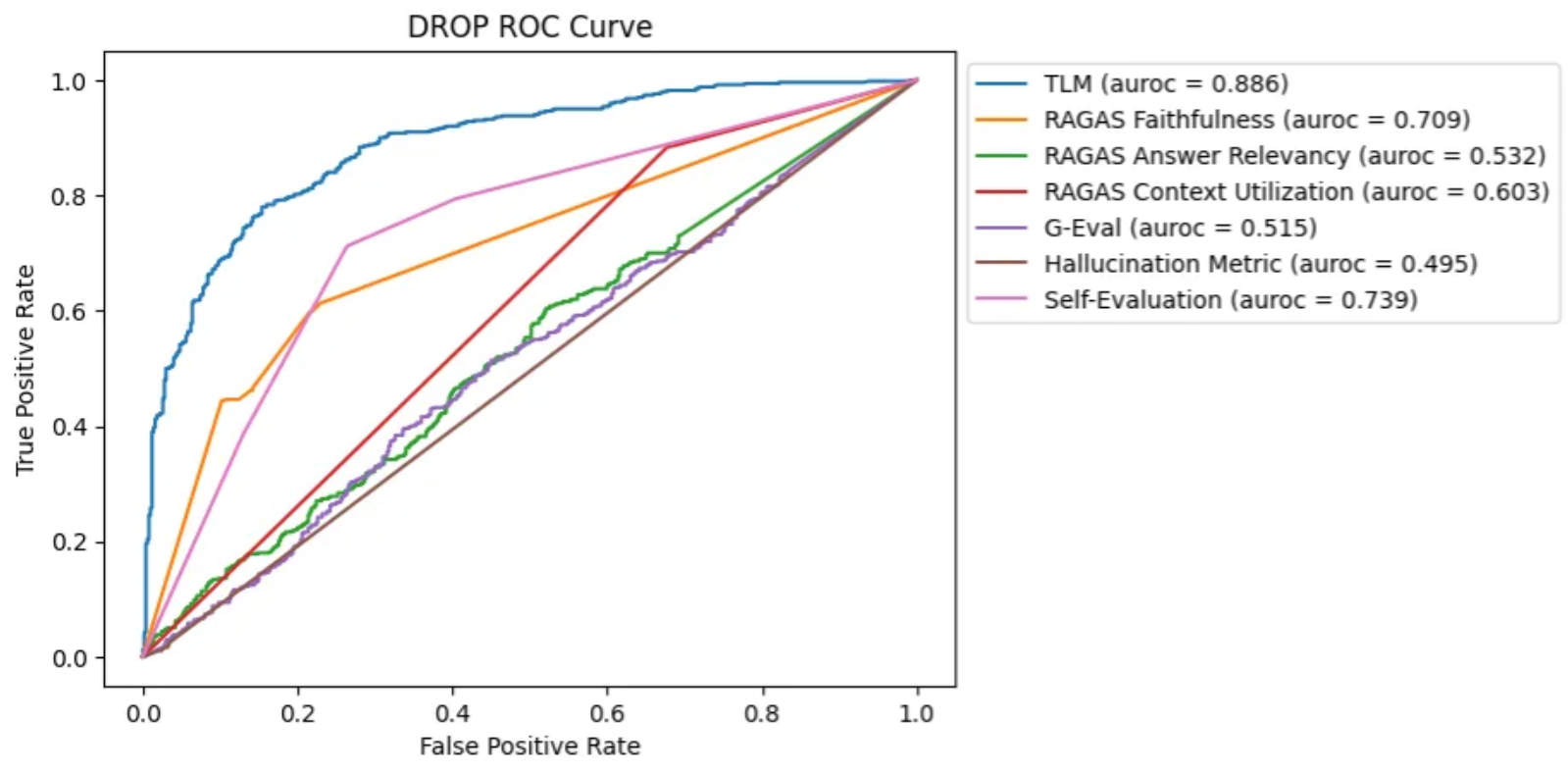
在DROP数据集中,由于推理的复杂性,大多数方法在检测幻觉时都显得力不从心。在这个基准测试中,TLM(可信语言模型)表现为最有效的检测方法,紧随其后的是自我评估和RAGAS忠实度。这些结果展示了不同技术在处理复杂推理任务时的优势和局限。
4.3、COVID-QA
COVID-QA 是一个围绕 COVID-19 相关科学文章建立的问答数据集。在这个数据集中,每一个实例都包含一个与 COVID-19 相关的科学段落,以及一个由该段落衍生的问题,例如:“SARS-COV-2 的基因序列与 SARS-COV 有多少相似性?”
相较于DROP这类需要深度推理的数据集,COVID-QA相对简单一些,因为它主要是基于段落中的信息直接回答问题。
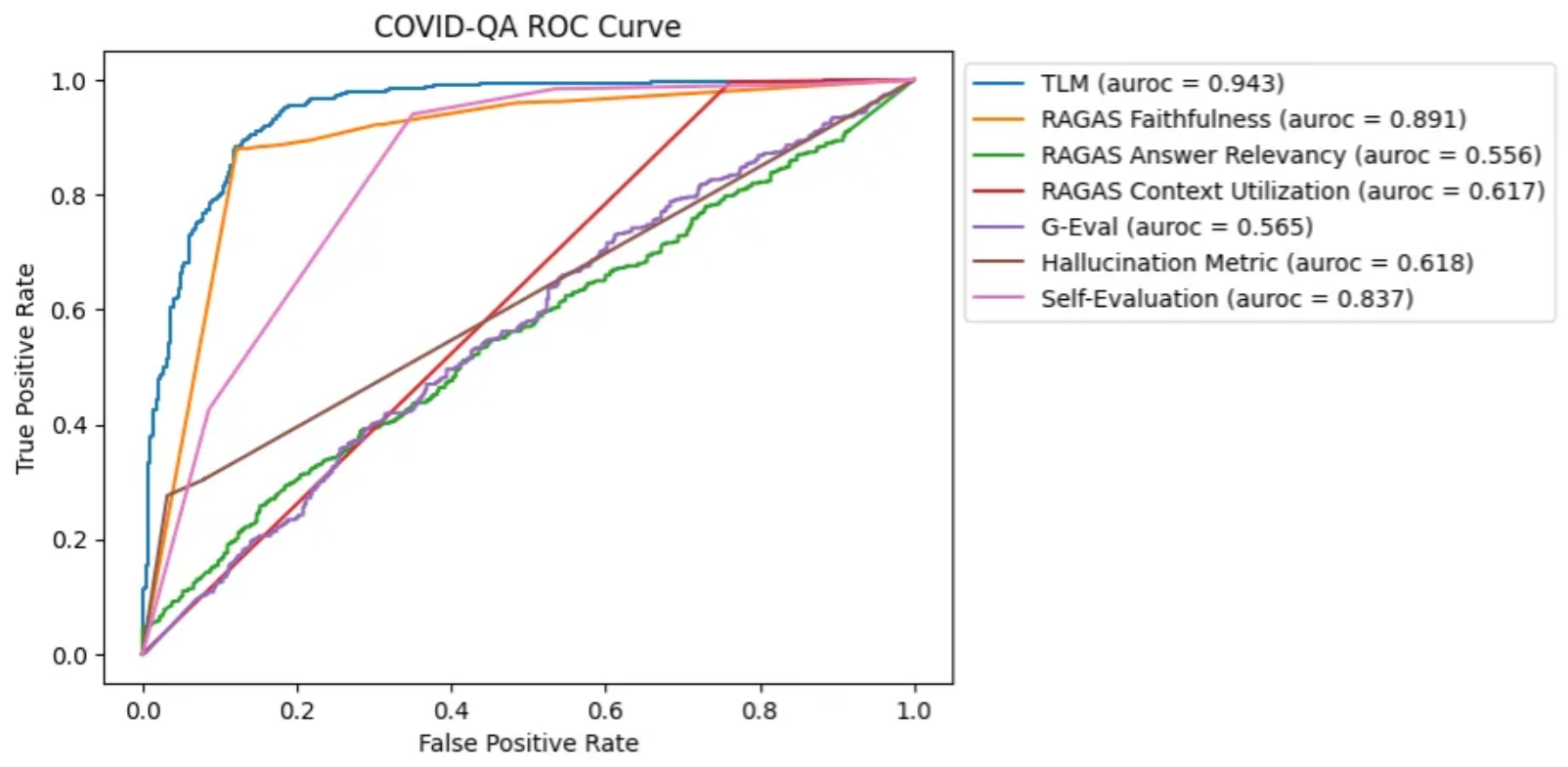
在COVID-QA数据集中,TLM(可信语言模型)和RAGAS忠实度在检测幻觉方面表现出了很强的性能。自我评估方法也表现不俗。然而,其他一些方法,如RAGAS答案相关性、G-Eval和幻觉度量的表现则较为不稳定,结果好坏参半。这一现象突显了在处理直接信息提取任务时,不同技术的适应性和效果差异。
4.4、FinanceBench
FinanceBench 是一个囊括了公共财务报表和上市公司信息的数据集。每个实例都包括了大量检索到的纯文本财务信息,以及一个关于该信息的问题,比如:“卡夫亨氏2015财年的净营运资本是多少?”答案通常是具体的数值,如“$2850.00”。
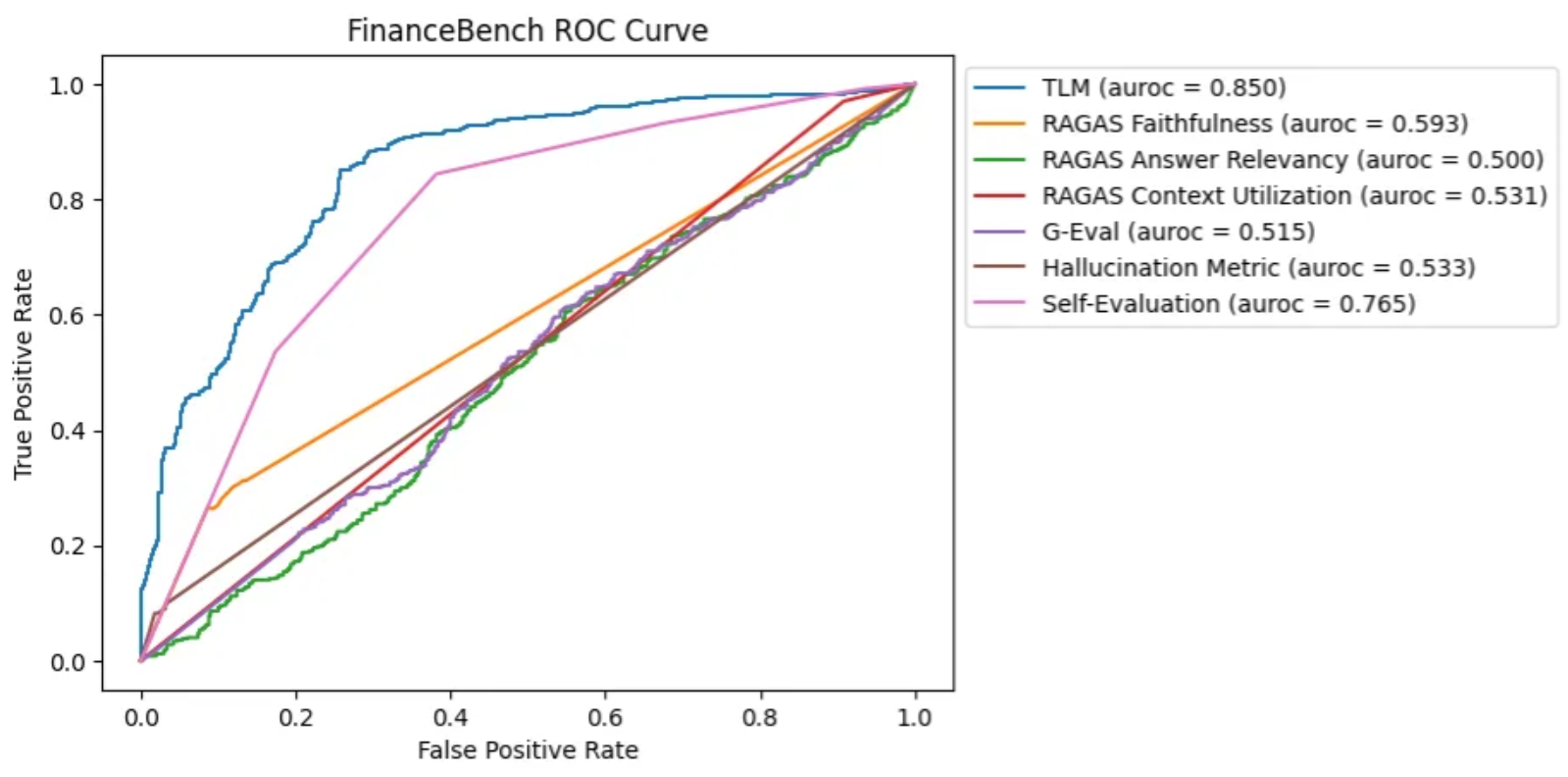
在这个基准测试中,TLM(可信语言模型)在识别幻觉方面表现最佳,其次是自我评估方法。大部分其他方法在提供超出随机猜测显著改进的能力方面遇到了难题,这凸显了处理含有大量上下文和数值数据的数据集所带来的挑战。这种情况说明,在处理涉及复杂和具体财务数据的查询时,我们需要更加精准和可靠的方法来保证回答的准确性。
5、实践总结
我们在多种检索增强生成(RAG)基准测试中对幻觉检测方法的评估揭示了以下几个关键的见解:
可信语言模型(TLM)的表现一直很稳定,通过结合自我反思、一致性检验和概率测量,展现出了强大的识别幻觉的能力。
自我评估在检测幻觉方面表现出了一致的有效性,尤其是在上下文较为简单的情况下,能够准确地衡量LLM的自我评价能力。虽然其性能有时可能不及TLM,但它仍然是一种简洁且实用的技术,用于评估响应质量。
RAGAS 忠实度在那些答案正确性高度依赖检索到的上下文的数据集中表现出稳定的性能,比如在PubMedQA和COVID-QA中尤其如此。它特别擅长识别答案中的声明是否得到了提供的上下文的支持。然而,其有效性随着问题复杂性的增加而变化。尽管默认情况下RAGAS使用gpt-3.5-turbo-16k进行生成和gpt-4作为评估模型,但我们这里报告的使用gpt-4o-mini的RAGAS结果表现更佳。在基准测试中,由于其对句子解析的要求,RAGAS有时无法运行,我们通过在没有标点符号的答案末尾添加句号(.)来解决这一问题。
其他方法如G-Eval和幻觉度量的表现参差不齐,在不同的基准测试中效果也各有不同。这表明这些技术可能还需要进一步的改进和调整才能达到更高的可用性和准确性。
总体来看,可信语言模型(TLM)、RAGAS忠实度和自我评估在检测RAG应用中的幻觉方面表现出较高的可靠性,成为了突出的方法。对于那些高风险的应用场景,将这些方法结合起来使用可能会得到最佳的效果。未来的研究可以探索将这些方法混合使用,以及针对特定用例的改进,从而更有效地进行幻觉检测。通过这样的整合,RAG系统能够实现更高的可靠性,并确保提供更准确、更值得信赖的响应。