




01
API设计的重要性
API设计是AI开源软件设计中的重要环节,本章将从三个方面来解释为何API设计至关重要。
1. 降低用户学习成本
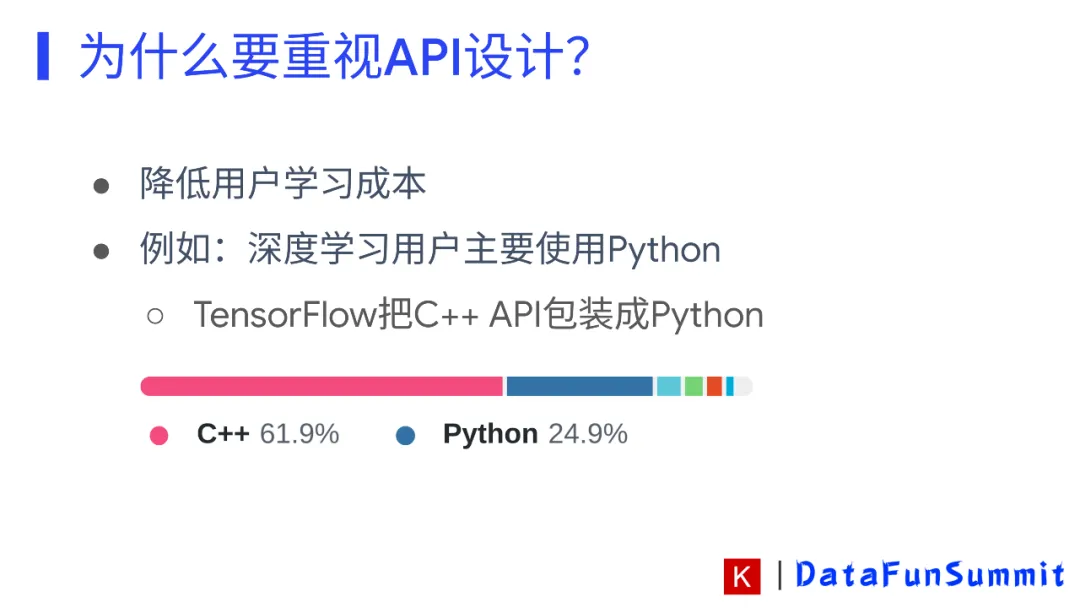
举一个例子,虽然TensorFlow大部分代码是c写的,但是多数工程师和数据科学家更喜欢使用python。Python的简洁易用性给他们带来了很大的方便,所以TensorFlow和Keras团队将原先C的代码封装成python的API供大众使用。现在,在github上,基于TensorFlow的软件库有16k+。TensorFlow有如此大的受众,与它的python API设计的简洁优雅,降低了用户学习成本,增加了其受众是分不开的。
2. 形成软件产业链,稳固生态
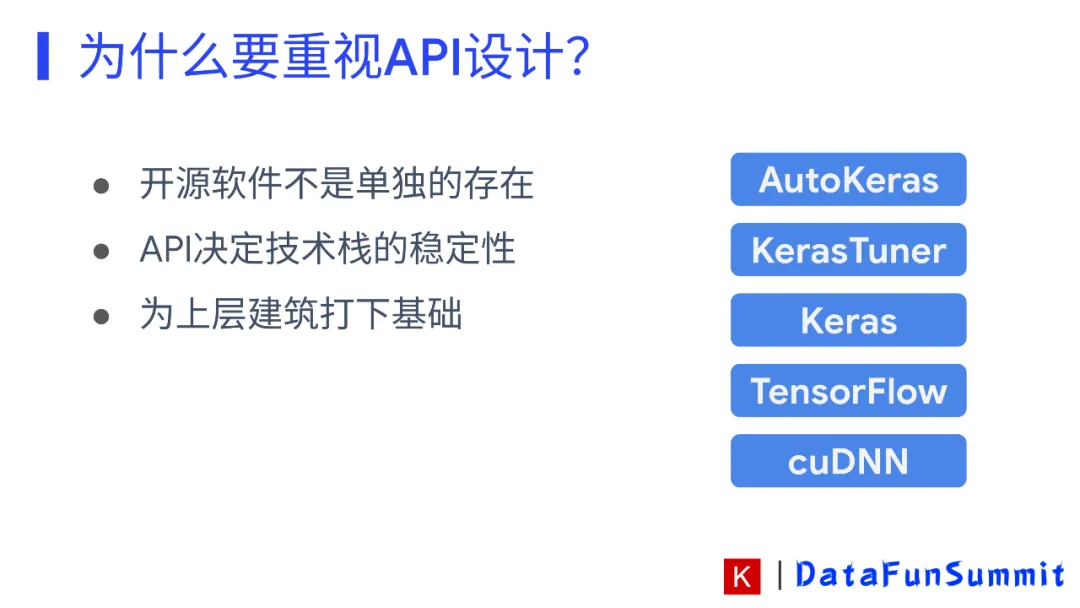
如果我们想要建立一个关于我们开发的开源软件的生态,想要让基于我们软件服务的开发者越来越多,我们就需要为这个生态提供稳定的、易用的API。
如上图所示,cuDNN的API使用稳定性决定了TensorFlow的稳定性以及易用性,以此类推。软件API的稳定性决定了基于它开发的其他软件的稳定性。一旦我们的软件能够做到”但凡有公司想要做这类服务的上层软件都绕不开我们的软件”,形成了产业链上的控制点,那么生态就会越做越大。
3. 简洁易用的API投资回报率很高
底层技术是需要实打实的请工程师一个一个去实现的,他的每一个实现的工作都需要点对点的投入,这是无法避免的。
顾名思义,application program interface (API) 是工程师和AI开源软件进行编程交互的地方。清晰简洁的API设计会减小用户学习成本和使用成本,上层的API设计会直接影响到用户的使用体验。如果API设计的不够简洁、完善,就容易被使用者诟病,特别是一些在网络上有影响力的数据科学家对于软件的评论会放大影响,使得很多用户在第一时间不会使用我们的软件。所以好的API设计能够防止底层工程师的努力付之东流。同时也能放大自身软件的优点。
02
API设计的新挑战
以下是两个开源AI软件API设计所面临的挑战。
1. 用户需求未知
如果在toB的环境下,在软件开发过程中,我们易于获得很多企业内部的需求,可以安排人员在会议上敲定接口的设计。但是对于开源软件,我们无法知道开源软件的目标用户的真正需求是什么。只有当我们真正投入时间资源将开源软件发行的时候,并吸引来用户使用的时候,才能获得反馈,但是那时候去修改API的设计是一件非常困难的事。
2. 用户群体割裂
科学家和工程师对于API的需求是不一致的,如何把需求缝合进同一套API是一项艰巨的任务。
03
API设计的基本原则
接下来介绍AI开源软件设计的三条基本原则,并用实例展示其重要性。
1. 代码未动,设计先行
① 设计倒推代码结构
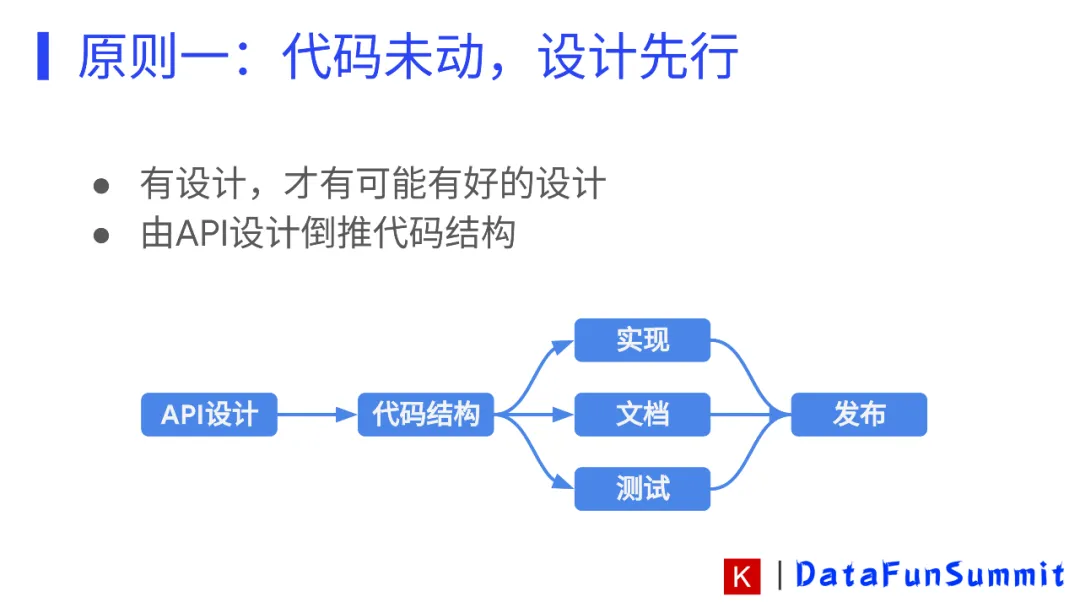
“代码未动,设计先行”,换一句话说,就是“用API的设计倒推代码结构”。在写软件的过程中,有很多代码是很难改动的,如cuDNN。如果底层代码不能够轻易改动,我们就需要设计中间层代码,而中间层代码的设计就是从API设计中倒推出来的。“倒推”的意思就是根据需求来归类代码,使有相同功能的代码具备较高的复用性,使API的结构能简洁易懂,既不冗余,也不缺少功能。
写AI开源软件的时候,我们的工作流需要遵守下图中的规范,先进行API设计,再实现代码。
② 反例
如果没有遵守原则一,会怎么样?该怎么办?
在这里先讲一个反例,很多开发者都会在刚开始写开源软件的时候先实现代码,后封装API。很容易让我们陷入功能之间不明确、耦合度高等陷阱。如果已经发生以上的错误,我们需要在封装代码前,先写API设计的文档,走一遍用API倒推代码结构的流程,再进行API的封装。
另外,当我们已经发布软件以后,可能会按照提出的issue以及后来发现需要新加入的功能对软件进行修改,在这里,我们需要谨慎修改API,重走设计流程。同时,我们需要谨慎增加API,因为对开发人员,增加API会增加维护难度。对使用者来说,增加API会使得使用者的学习成本变高。
③ 如何撰写API设计文档
很多开发人员在开发项目时都是先设计文档,在开源软件的设计文档撰写过程中,我们需要把设计文档当作教程来写。在撰写文档的过程中,应该首先思考代码的应用场景,而不是首先定义函数。如果首先思考函数定义,函数定义非常明晰,也都实现了相应的接口,但可能当他们聚合起来,用户想要实现具体场景的功能时,会遇到各种各样的问题。所以,以考虑周全的实际场景为例来设计API是AI开源软件设计API的非常好用的方法。
④ 从需求端出发进行设计
举一个例子,如果我们定义一个模型,需要进行中间层的输入,那么下面的第一段代码就会变得十分臃肿低效,在第二段代码中,只需要进行一个循环就能够搞定每一层神经网络的输出。
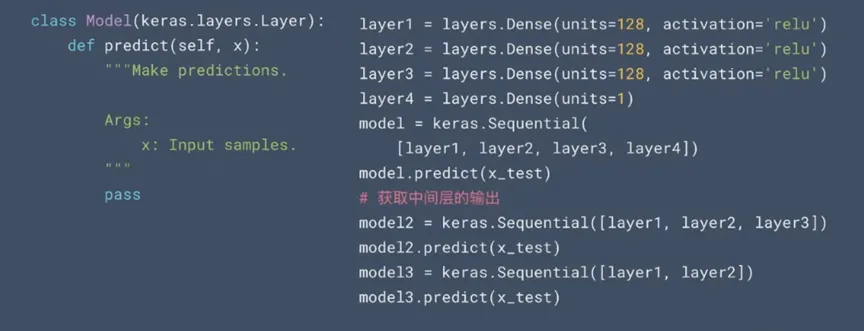

上面的例子也是想要说明,在做API设计的时候需要考虑全部的应用场景,因为往往基于单个场景的API设计容易给用户的使用带来非常多的麻烦。
⑤ 优秀API设计参考
如果大家想要参考比较好的AI开源API设计文档,可以参考以下两个repository:

2. 所想即所得
① 好的API设计契合用户的心理表征
以深度学习框架为例,很多算法工程师以及科学家在脑海中已经有了深度学习的模型(用户的心理表征),他们想要使用深度学习框架来实现模型。
那么最好API设计就是将API接口设计成为使用者脑海中抽象成的算法接口,如下图的Keras模型,Keras框架对模型、损失、优化、训练还有推断模块进行了恰到好处的设计,用户可以在构建深度学习模型的过程中对相应的模块进行修改。

② 差的API设计灌输不必要的概念,迷惑用户的原有正确认知
举一个反例,像TensorFlow 1 中那样,完成网络训练的步骤掌握编译原理中的概念强加(如tf.Session),会增加用户的学习负担。在代码的表示上迷惑用户,让有模型基础但是不熟悉TensorFlow原理的人迷惑于表达式有没有真正被执行。

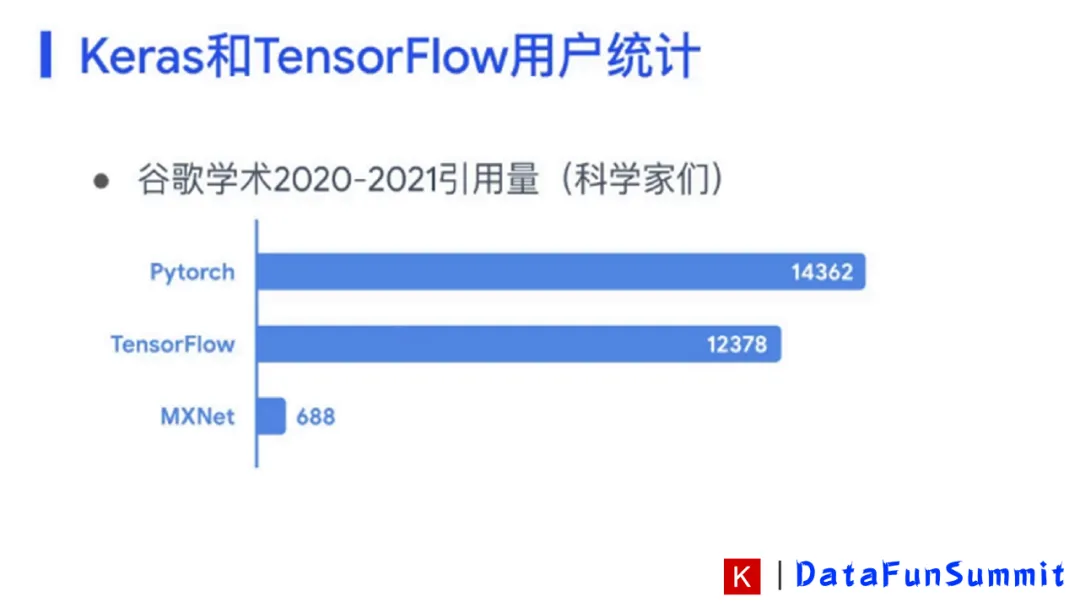
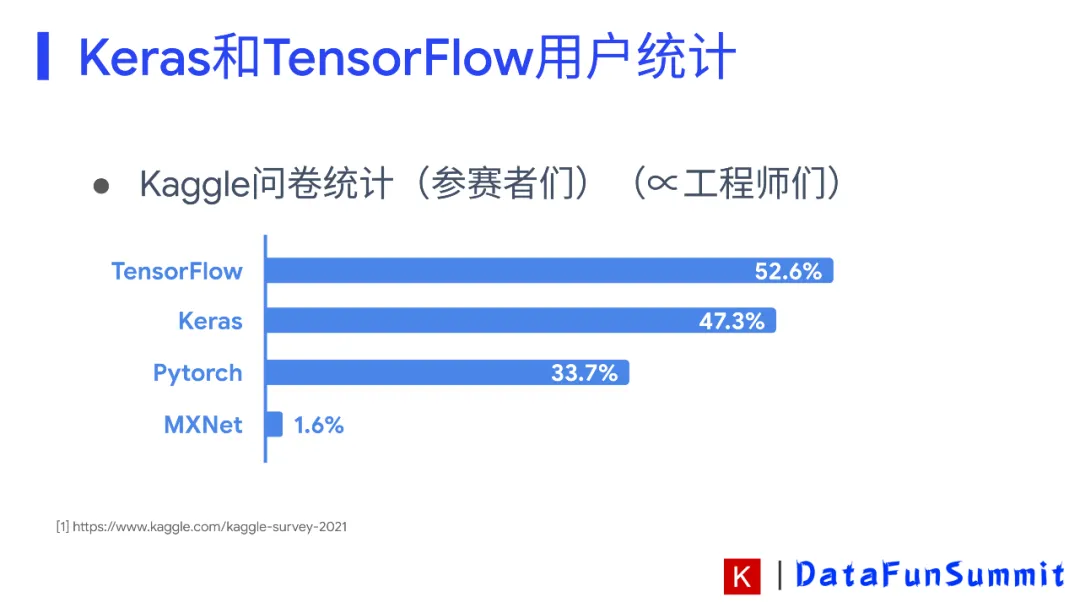
③ TensorFlow和Keras为何成为最受欢迎的AI框架之一
曾经有团队做过这样的调研,在谷歌学术应用的论文中,Keras&TensorFlow框架使用人数是第二名,在kaggle比赛领域,Keras&TensorFlow框架使用人数是第一名。这说明了Keras&TensorFlow框架在学术领域和工程领域收到了科学家和工程师们的一致认可。不同的用户群体对AI框架有不同的需求,那么Keras是如何同时去满足科学家和工程师的需求呢?
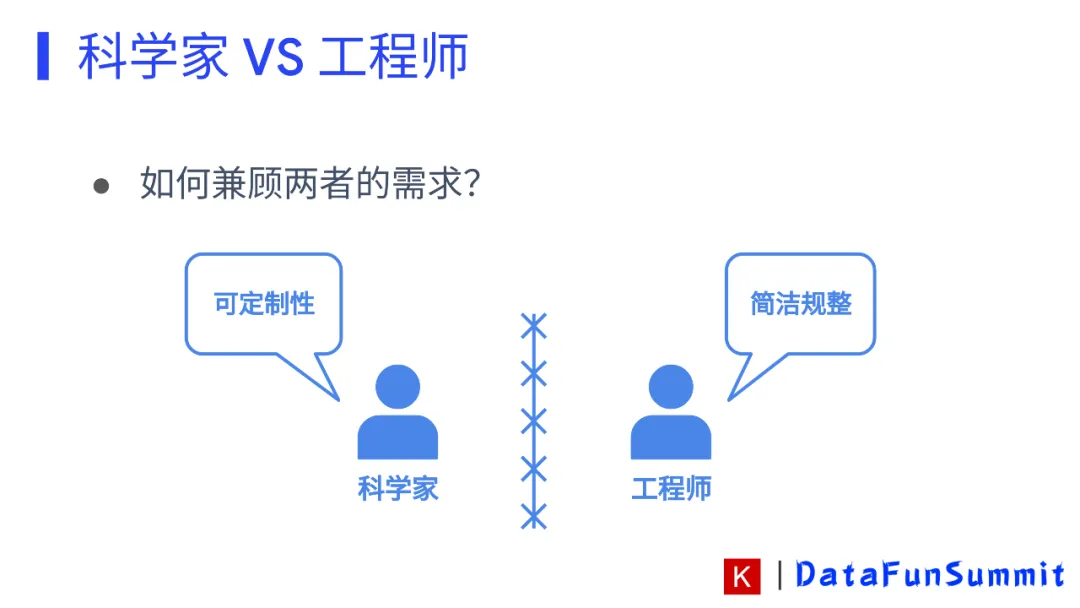
科学家的需求是需要能够通过数学公式的推导,对模型进行最小量级的优化,如修改loss function、optimization方法以及模型结构等,换句话说就是要模型的可定制性强。但工程师希望代码简洁规整,用最少的代码来实现他所希望实现的功能。
将两种需求融合到同一种API的方法叫做:“让用户只学习必要的知识。”
对于工程师,使用默认的loss function 以及优化算法就可以解决问题,只需要图中少量的代码就可以完成训练。

而对于科学家,如果需要修改优化算法的细节,可以通过以下代码来重新定义优化算法,满足科学家们的探索需求。

在上面的代码中,工程师只需要学习如何训练模型,而科学家则可以修改optimizer中的细节,这样的API设计同时满足了两类需求不同的人群。
3. 让用户在交互中学习
由于代码是会随着时间变化的。用户很难一次性把代码写对。用户会通过报错信息来一步步修正自己的代码,在试错中前进。那么如何设计框架使得用户有一个好的反馈呢?

① 如何给予用户准确又适当的错误信息
我们用例子来进行说明: 当我们设计API报错的时候,我们总希望能够得到更接近于API表层的错误信息,因为这样更加容易知道我们错在哪里,同时我们希望报错能够越详细越好,最好能够有一些代码修改的指引。我们希望能够获得最明确的信息来快速的改正自己代码中的错误。
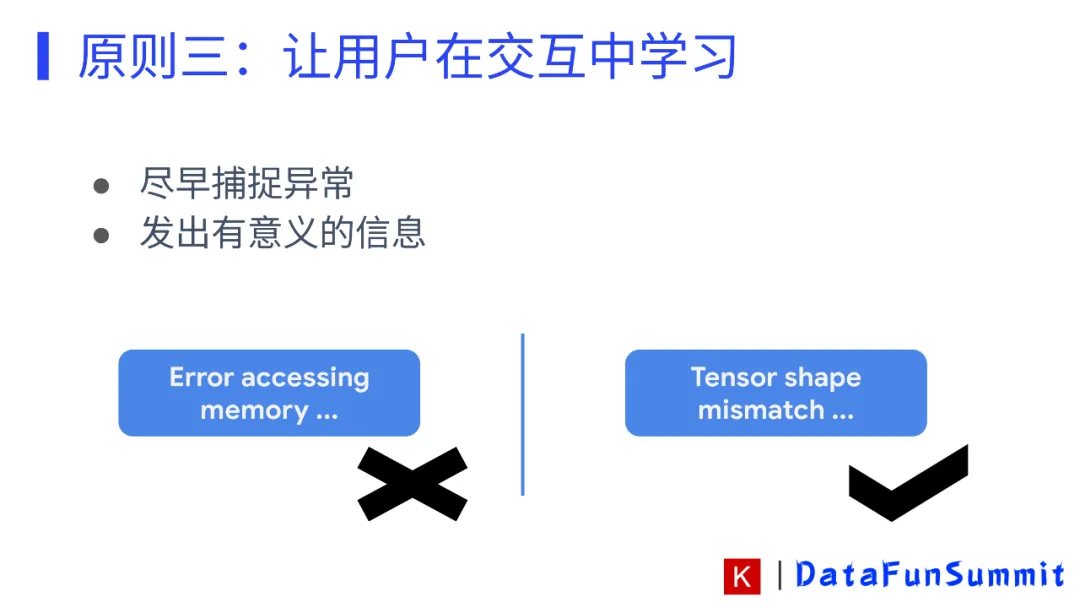
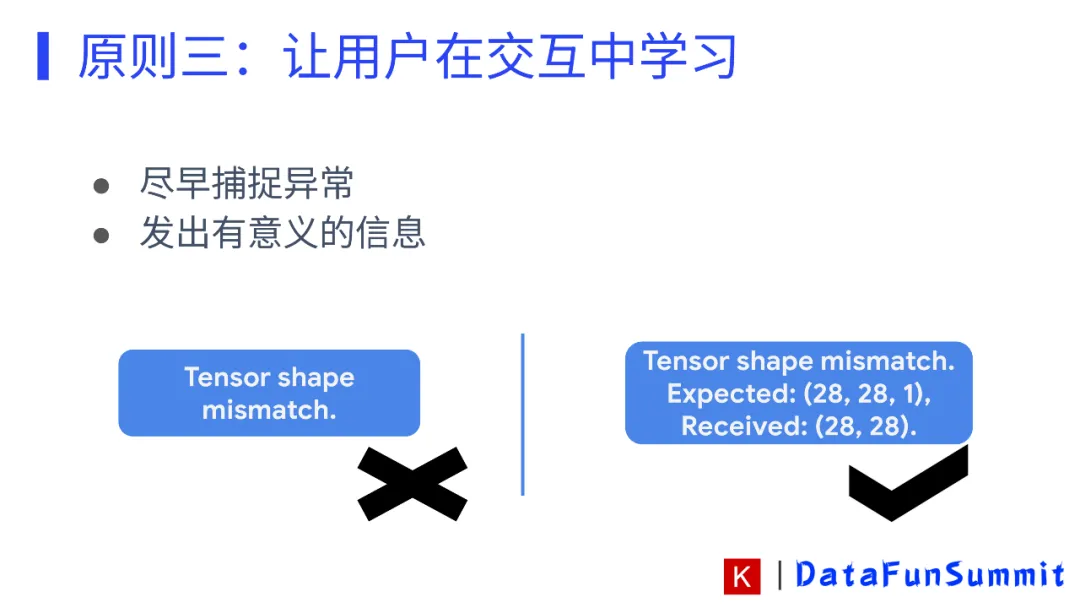
上面两张图就展示了层层递进的报错方式。
② 报错信息的优秀实践
当然,最好的报错信息不仅非常准确详细的记录了错在哪里,而且会指引你如何去修改,下面就是Keras报错的一个最佳示范。

③ 一个好用的API的朴素评价标准
“用户能轻易掌握API的使用逻辑,并在根据这种逻辑构建自己的应用时,很少查阅文档。" 这是金博士团队总结出的一条朴素的评价API好用的标准。用户能够通过tutorial进行学习,并能够很快将代码转移到自己的应用中是展现API好用的非常直观的评价标准。
04
总结
最后对全文进行总结如下:
