




随着ChatGPT的迅速出圈,加速了大模型时代的变革。对于以Transformer、MOE结构为代表的大模型来说,传统的单机单卡训练模式肯定不能满足上千(万)亿级参数的模型训练,这时候我们就需要解决内存墙和通信墙等一系列问题,在单机多卡或者多机多卡进行模型训练。
最近一段时间,我也在探索大模型相关的一些技术,下面做一个简单的总结。
GPU集群
由于目前只有3台A800 GPU服务器(共24卡)。基于目前现有的一些AI框架和大模型,无法充分利用3台服务器。比如:OPT-66B一共有64层Transformer,当使用Alpa进行流水线并行时,通过流水线并行对模型进行切分,要么使用16卡,要么使用8卡,没法直接使用24卡,因此,GPU服务器最好是购买偶数台(如:2台、4台、8台)。
具体的硬件配置如下:
- CPUs: 每个节点具有 1TB 内存的 Intel CPU,物理CPU个数为64,每颗CPU核数为16。
- GPUs: 24 卡 A800 80GB GPUs ,每个节点 8 个 GPU(3 个节点)。
目前使用Huggingface Transformers和DeepSpeed进行通过数据并行进行训练(pretrain),单卡可以跑三百亿参数(启用ZeRO-2或ZeRO-3),如OPT-30B,具体训练教程参考官方样例。
使用Alpa进行流水线并行和数据并行进行训练(fine tuning)时,使用了3台共24卡(PP:12,DP:2)进行训练OPT-30B,具体训练教程参考官方样例。但是进行模型训练之前需要先进行模型格式转换,将HF格式转换为Alpa格式的模型文件,具体请参考官方代码。如果不想转换,官网也提供了转换好的模型格式,具体请参考文档:Serving OPT-175B, BLOOM-176B and CodeGen-16B using Alpa。

大模型算法
模型结构:
目前主流的大模型都是Transformer、MOE结构为基础进行构建,如果说Transformer结构使得模型突破到上亿参数量,MoE 稀疏混合专家结构使模型参数量产生进一步突破,达到数万亿规模。
大模型算法:
下图详细展示了AI大模型的发展历程:
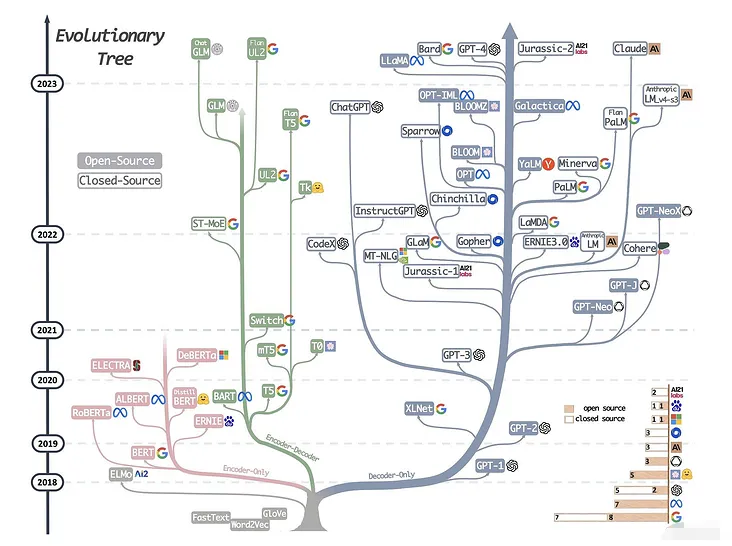
可以说,Transformer 开创了继 MLP 、CNN和 RNN之后的第四大类模型。而基于Transformer结构的模型又可以分为Encoder-only、Decoder-only、Encoder-Decoder这三类。
- 仅编码器架构(Encoder-only):自编码模型(破坏一个句子,然后让模型去预测或填补),更擅长理解类的任务,例如:文本分类、实体识别、关键信息抽取等。典型代表有:Bert、RoBERTa等。
- 仅解码器架构(Decoder-only):自回归模型(将解码器自己当前步的输出加入下一步的输入,解码器融合所有已经输入的向量来输出下一个向量,所以越往后的输出考虑了更多输入),更擅长生成类的任务,例如:文本生成。典型代表有:GPT系列、LLaMA、OPT、Bloom等。
- 编码器-解码器架构(Encoder-Decoder):序列到序列模型(编码器的输出作为解码器的输入),主要用于基于条件的生成任务,例如:翻译,概要等。典型代表有:T5、BART、GLM等。
大语言模型
目前业界可以下载到的一些大语言模型:
-
ChatGLM-6B :中英双语的对话语言模型。
-
GLM-10B/130B :双语(中文和英文)双向稠密模型。
-
OPT-2.7B/13B/30B/66B :Meta开源的预训练语言模型。
-
LLaMA-7B/13B/30B/65B :Meta开源的基础大语言模型。
-
Alpaca(LLaMA-7B):斯坦福提出的一个强大的可复现的指令跟随模型,种子任务都是英语,收集的数据也都是英文,因此训练出来的模型未对中文优化。
-
BELLE(BLOOMZ-7B/LLaMA-7B/LLaMA-13B):本项目基于 Stanford Alpaca,针对中文做了优化,模型调优仅使用由ChatGPT生产的数据(不包含任何其他数据)。
-
Bloom-7B/13B/176B:可以处理46 种语言,包括法语、汉语、越南语、印度尼西亚语、加泰罗尼亚语、13 种印度语言(如印地语)和 20 种非洲语言。其中,Bloomz系列模型是基于 xP3 数据集微调。 推荐用于英语的提示(prompting);Bloomz-mt系列模型是基于 xP3mt 数据集微调。推荐用于非英语的提示(prompting)。
-
Vicuna(7B/13B):由UC Berkeley、CMU、Stanford和 UC San Diego的研究人员创建的 Vicuna-13B,通过在 ShareGPT 收集的用户共享对话数据中微调 LLaMA 获得。其中,使用 GPT-4 进行评估,发现 Vicuna-13B 的性能在超过90%的情况下实现了与ChatGPT和Bard相匹敌的能力;同时,在 90% 情况下都优于 LLaMA 和 Alpaca 等其他模型。而训练 Vicuna-13B 的费用约为 300 美元。不仅如此,它还提供了一个用于训练、服务和评估基于大语言模型的聊天机器人的开放平台:FastChat。
-
Baize:白泽是在LLaMA上训练的。目前包括四种英语模型:白泽-7B、13B 、 30B(通用对话模型)以及一个垂直领域的白泽-医疗模型,供研究 / 非商业用途使用,并计划在未来发布中文的白泽模型。白泽的数据处理、训练模型、Demo 等全部代码已经开源。
-
LLMZoo:来自香港中文大学和深圳市大数据研究院团队推出的一系列大模型,如:Phoenix(凤凰) 和 Chimera等。
-MOSS:由复旦 NLP 团队推出的 MOSS 大语言模型。
20230325(当时官方还未开源训练代码,目前直接基于官方的训练代码即可):
前两天测试了BELLE,对中文的效果感觉还不错。具体的模型训练(预训练)方法可参考Hugingface Transformers的样例,SFT(指令精调)方法可参考Alpaca的训练代码。
从上面可以看到,开源的大语言模型主要有三大类:GLM衍生的大模型(wenda、ChatSQL等)、LLaMA衍生的大模型(Alpaca、Vicuna、BELLE、Phoenix、Chimera等)、Bloom衍生的大模型(Bloomz、BELLE、Phoenix等)。
| 模型 | 训练数据量 | 模型参数 | 训练数据范围 | 词表大小 |
|---|---|---|---|---|
| LLaMA | 1T~1.4T tokens(其中,7B/13B使用1T,33B/65B使用1.4T) | 7B~65B | 以英语为主要语言的拉丁语系 | 32000 |
| ChatGLM-6B | 约 1T tokens | 6B | 中文、英语 | 130528 |
| Bloom | 1.6TB预处理文本,转换为 350B 唯一 tokens | 300M~176B | 46种自然语言,13种编程语言 | 250680 |
从表格中可以看到,对于像ChatGLM-6B、LLaMA、Bloom这类大模型,要保证基座模型有比较好的效果,至少需要保证上千亿、万亿级的Token量。
目前来看,LLaMA无疑是其中最闪亮的星。但是国内关于LLaMA比较大的一个争论就是LLaMA是以英语为主要语言的拉丁语系上进行训练的,LLaMA词表中的中文token比较少(只有几百个),需不需要扩充词表?如果不扩充词表,中文效果会不会比较差?
- 如果不扩充词表,对于中文效果怎么样?根据Vicuna官方的报告,经过Instruction Turing的Vicuna-13B已经有非常好的中文能力。
- LLaMA需不需要扩充词表?根据Chinese-LLaMA-Alpaca和BELLE的报告,扩充中文词表,可以提升中文编解码效率以及模型的性能。但是扩词表,相当于从头初始化开始训练这些参数。如果想达到比较好的性能,需要比较大的算力和数据量。同时,Chinese-LLaMA-Alpaca也指出在进行第一阶段预训练(冻结transformer参数,仅训练embedding,在尽量不干扰原模型的情况下适配新增的中文词向量)时,模型收敛速度较慢。如果不是有特别充裕的时间和计算资源,建议跳过该阶段。因此,虽然扩词表看起来很诱人,但是实际操作起来,还是很有难度的。
下面是BELLE针对是否扩充词表,数据质量、数据语言分布、数据规模对于模型性能的对比:
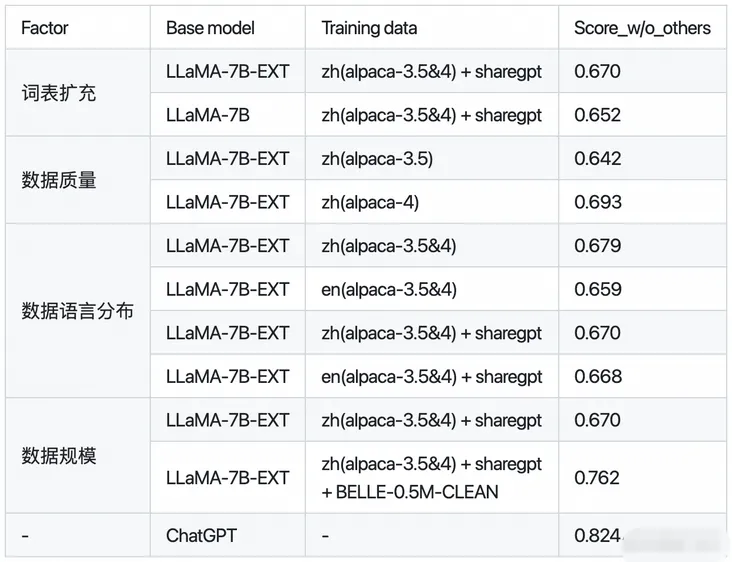
其中,BELLE-0.5M-CLEAN是从230万指令数据中清洗得到0.5M数据(包含单轮和多轮对话数据)。LLaMA-7B-EXT是针对LLaMA做了中文词表扩充的预训练模型。
下面是Chinese-LLaMA-Alpaca针对中文Alpaca-13B、中文Alpaca-Plus-7B、中文Alpaca-Plus-13B的效果对比:
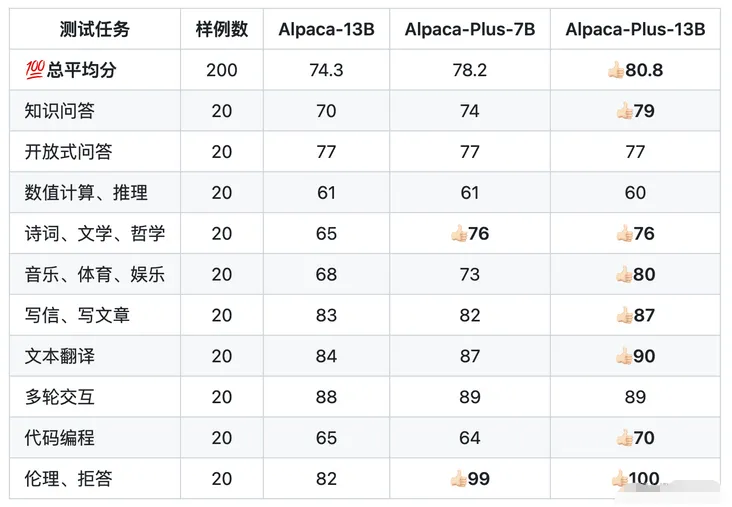
其中,Plus系列Alpaca是在原版LLaMA的基础上扩充了中文词表,使用了120G中文通用纯文本数据进行二次预训练。
因此,如果既想要中文词表,又没有很大的算力,那建议直接使用ChatGLM-6B或者使用BELLE和Chinese-LLaMA-Alpaca进行中文词表扩充后训练好的模型作为Base模型。
多模态大模型
目前业界可以下载到的一些多模态大模型:
- MiniGPT-4:沙特阿拉伯阿卜杜拉国王科技大学的研究团队开源。
- LLaVA:由威斯康星大学麦迪逊分校,微软研究院和哥伦比亚大学共同出品。
- VisualGLM-6B:开源的,支持图像、中文和英文的多模态对话语言模型,语言模型基于 ChatGLM-6B,具有 62 亿参数;图像部分通过训练 BLIP2-Qformer 构建起视觉模型与语言模型的桥梁,整体模型共78亿参数。
分布式并行及显存优化技术
并行技术:
- 数据并行(如:PyTorch DDP)
- 模型/张量并行(如:Megatron-LM(1D)、Colossal-AI(2D、2.5D、3D))
- 流水线并行(如:GPipe、PipeDream、PipeDream-2BW、PipeDream Flush(1F1B))
- 多维混合并行(如:3D并行(数据并行、模型并行、流水线并行))
- 自动并行(如:Alpa(自动算子内/算子间并行))
- 优化器相关的并行(如:ZeRO(零冗余优化器,在执行的逻辑上是数据并行,但可以达到模型并行的显存优化效果)、PyTorch FSDP)
显存优化技术:
- 重计算(Recomputation):Activation checkpointing(Gradient checkpointing),本质上是一种用时间换空间的策略。
- 卸载(Offload)技术:一种用通信换显存的方法,简单来说就是让模型参数、激活值等在CPU内存和GPU显存之间左右横跳。如:ZeRO-Offload、ZeRO-Infinity等。
- 混合精度(BF16/FP16):降低训练显存的消耗,还能将训练速度提升2-4倍。
- BF16 计算时可避免计算溢出,出现Inf case。
- FP16 在输入数据超过65506 时,计算结果溢出,出现Inf case。
分布式训练框架
如何选择一款分布式训练框架?
- 训练成本:不同的训练工具,训练同样的大模型,成本是不一样的。对于大模型,训练一次动辄上百万/千万美元的费用。合适的成本始终是正确的选择。
- 训练类型:是否支持数据并行、张量并行、流水线并行、多维混合并行、自动并行等
- 效率:将普通模型训练代码变为分布式训练所需编写代码的行数,我们希望越少越好。
- 灵活性:你选择的框架是否可以跨不同平台使用?
常见的分布式训练框架:
- 第一类:深度学习框架自带的分布式训练功能。如:TensorFlow、PyTorch、MindSpore、Oneflow、PaddlePaddle等。
- 第二类:基于现有的深度学习框架(如:PyTorch、Flax)进行扩展和优化,从而进行分布式训练。如:Megatron-LM(张量并行)、DeepSpeed(Zero-DP)、Colossal-AI(高维模型并行,如2D、2.5D、3D)、Alpa(自动并行)等
目前训练超大规模语言模型主要有两条技术路线:
- TPU + XLA + TensorFlow/JAX :由Google主导,由于TPU和自家云平台GCP深度绑定
- GPU + PyTorch + Megatron-LM + DeepSpeed :由NVIDIA、Meta、MicroSoft大厂加持,社区氛围活跃,也更受到大家欢迎。
参数高效微调(PEFT)技术
在面对特定的下游任务时,如果进行Full FineTuning(即对预训练模型中的所有参数都进行微调),太过低效;而如果采用固定预训练模型的某些层,只微调接近下游任务的那几层参数,又难以达到较好的效果。
PEFT技术旨在通过最小化微调参数的数量和计算复杂度,来提高预训练模型在新任务上的性能,从而缓解大型预训练模型的训练成本。这样一来,即使计算资源受限,也可以利用预训练模型的知识来迅速适应新任务,实现高效的迁移学习。因此,PEFT技术可以在提高模型效果的同时,大大缩短模型训练时间和计算成本,让更多人能够参与到深度学习研究中来。
-
Prefix Tuning:与full fine-tuning更新所有参数的方式不同,该方法是在输入token之前构造一段任务相关的virtual tokens作为Prefix,然后训练的时候只更新Prefix部分的参数,而Transformer中的其他部分参数固定。该方法其实和构造Prompt类似,只是Prompt是人为构造的“显式”的提示,并且无法更新参数,而Prefix则是可以学习的“隐式”的提示。
同时,为了防止直接更新Prefix的参数导致训练不稳定的情况,他们在Prefix层前面加了MLP结构(相当于将Prefix分解为更小维度的Input与MLP的组合后输出的结果),训练完成后,只保留Prefix的参数。
-
Prompt Tuning:该方法可以看作是Prefix Tuning的简化版本,只在输入层加入prompt tokens,并不需要加入MLP进行调整来解决难训练的问题。随着预训练模型参数量的增加,Prompt Tuning的方法会逼近fine-tuning的结果。
-
P-Tuning:该方法的提出主要是为了解决这样一个问题:大模型的Prompt构造方式严重影响下游任务的效果。P-Tuning将Prompt转换为可以学习的Embedding层,并用MLP+LSTM的方式来对prompt embedding进行一层处理。
-
P-Tuning v2:让Prompt Tuning能够在不同参数规模的预训练模型、针对不同下游任务的结果上都达到匹敌Fine-tuning的结果。相比Prompt Tuning和P-tuning的方法,P-Tuning v2方法在多层加入了Prompts tokens作为输入,带来两个方面的好处:
-
带来更多可学习的参数(从P-tuning和Prompt Tuning的0.1%增加到0.1%-3%),同时也足够参数高效。
-
加入到更深层结构中的Prompt能给模型预测带来更直接的影响。
-
Adapter Tuning:该方法设计了Adapter结构(首先是一个down-project层将高维度特征映射到低维特征,然后过一个非线形层之后,再用一个up-project结构将低维特征映射回原来的高维特征;同时也设计了skip-connection结构,确保了在最差的情况下能够退化为identity),并将其嵌入Transformer的结构里面,在训练时,固定住原来预训练模型的参数不变,只对新增的Adapter结构进行微调。同时为了保证训练的高效性(也就是尽可能少的引入更多参数)。
-
LoRA:在涉及到矩阵相乘的模块,引入A、B这样两个低秩矩阵模块去模拟full fine-tuning的过程,相当于只对语言模型中起关键作用的低秩本质维度进行更新。
典型应用:
- ChatGLM-Tuning :一种平价的chatgpt实现方案,基于清华的 ChatGLM-6B + LoRA 进行finetune。
- Alpaca-Lora:使用低秩自适应(LoRA)复现斯坦福羊驼的结果。Stanford Alpaca 是在 LLaMA 整个模型上微调,而 Alpaca-Lora 则是利用 Lora 技术,在冻结原模型 LLaMA 参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,这样不仅微调的成本显著下降,还能获得和全模型微调类似的效果。
- BLOOM-LORA:由于LLaMA的限制,我们尝试使用Alpaca-Lora重新实现BLOOM-LoRA。
PEFT实现:
- PEFT:Huggingface推出的PEFT库。
- unify-parameter-efficient-tuning:一个参数高效迁移学习的统一框架。
高效微调技术目前存在的两个问题:
相比全参数微调,高效微调技术目前存在的两个问题:
- 推理速度会变慢
- 模型精度会变差
影响大模型性能的主要因素
OpenAI的论文Scaling Laws for Neural Language Models中列举了影响模型性能最大的三个因素:计算量、数据集大小、模型参数量。也就是说,当其他因素不成为瓶颈时,计算量、数据集大小、模型参数量这3个因素中的单个因素指数增加时,loss会线性的下降。
除了以上的因素之外,还有一个比较大的影响因素就是数据质量。在微软的论文Instruction Tuning with GPT-4中指出,同样基于LLaMA模型,使用GPT3和GPT4产生的数据,对模型进行Instruction Turing,可以看到GPT4的数据微调过的模型效果远远好于GPT3数据微调的模型,可见数据质量带来的影响。同样的,Vicuna(7B/13B)的Instruction Turing中,也对shareGPT的数据做了很细致的清洗工作。
衡量大模型水平
要评估一个大型语言模型的水平,可以从以下几个维度提出具有代表性的问题。
- 理解能力:提出一些需要深入理解文本的问题,看模型是否能准确回答。
- 语言生成能力:让模型生成一段有关特定主题的文章或故事,评估其生成的文本在结构、逻辑和语法等方面的质量。
- 知识面广度:请模型回答关于不同主题的问题,以测试其对不同领域的知识掌握程度。这可以是关于科学、历史、文学、体育或其他领域的问题。一个优秀的大语言模型应该可以回答各种领域的问题,并且准确性和深度都很高。
- 适应性:让模型处理各种不同类型的任务,例如:写作、翻译、编程等,看它是否能灵活应对。
- 长文本理解:提出一些需要处理长文本的问题,例如:提供一篇文章,让模型总结出文章的要点,或者请模型创作一个故事或一篇文章,让其有一个完整的情节,并且不要出现明显的逻辑矛盾或故事结构上的错误。一个好的大语言模型应该能够以一个连贯的方式讲述一个故事,让读者沉浸其中。
- 长文本生成:请模型创作一个故事或一篇文章,让其有一个完整的情节,并且不要出现明显的逻辑矛盾或故事结构上的错误。一个好的大语言模型应该能够以一个连贯的方式讲述一个故事,让读者沉浸其中。
- 多样性:提出一个问题,让模型给出多个不同的答案或解决方案,测试模型的创造力和多样性。
- 情感分析和推断:提供一段对话或文本,让模型分析其中的情感和态度,或者推断角色间的关系。
- 情感表达:请模型生成带有情感色彩的文本,如描述某个场景或事件的情感、描述一个人物的情感状态等。一个优秀的大语言模型应该能够准确地捕捉情感,将其表达出来。
- 逻辑推理能力:请模型回答需要进行推理或逻辑分析的问题,如概率或逻辑推理等。这可以帮助判断模型对推理和逻辑思考的能力,以及其在处理逻辑问题方面的准确性。例如:“所有的动物都会呼吸。狗是一种动物。那么狗会呼吸吗?”
- 问题解决能力:提出实际问题,例如:数学题、编程问题等,看模型是否能给出正确的解答。
- 道德和伦理:测试模型在处理有关道德和伦理问题时的表现,例如:“在什么情况下撒谎是可以接受的?”
- 对话和聊天:请模型进行对话,以测试其对自然语言处理的掌握程度和能力。一个优秀的大语言模型应该能够准确地回答问题,并且能够理解人类的语言表达方式。
大模型评估方法:
- 人工评估:LIMA、Phoenix
- 使用 GPT-4 的反馈进行自动评估:Vicuna、Phoenix、Chimera、BELLE
- 指标评估(BLEU-4、ROUGE分数):ChatGLM-6B;对于像ROUGE-L分数的指标评估,有些地方称其为非自然指令评估(Unnatural Instruction Evaluation)。
大模型评估工具:
- Open AI evals
大模型推理加速
模型推理作为模型投产的最后一公里,需要确保模型精度的同时追求极致的推理性能。相比传统模型来说,大模型面临着更多的挑战。
当前优化模型最主要技术手段概括来说有以下三个层面:
- 算法层面:蒸馏、量化
- 软件层面:计算图优化、模型编译
- 硬件层面:FP8(NVIDIA H系列GPU开始支持FP8,兼有fp16的稳定性和int8的速度)
推理加速框架:
- FasterTransformer:英伟达推出的FasterTransformer不修改模型架构而是在计算加速层面优化 Transformer 的 encoder 和 decoder 模块。具体包括如下:
- 尽可能多地融合除了 GEMM 以外的操作
- 支持 FP16、INT8、FP8
- 移除 encoder 输入中无用的 padding 来减少计算开销
- TurboTransformers:腾讯推出的 TurboTransformers 由 computation runtime 及 serving framework 组成。加速推理框架适用于 CPU 和 GPU,最重要的是,它可以无需预处理便可处理变长的输入序列。具体包括如下:
- 与 FasterTransformer 类似,它融合了除 GEMM 之外的操作以减少计算量
- smart batching,对于一个 batch 内不同长度的序列,它也最小化了 zero-padding 开销
- 对 LayerNorm 和 Softmax 进行批处理,使它们更适合并行计算
- 引入了模型感知分配器,以确保在可变长度请求服务期间内存占用较小
经验与教训
经验:
- 对于同一模型,选择不同的训练框架,对于资源的消耗情况可能存在显著差异(比如使用Huggingface Transformers和DeepSpeed训练OPT-30相对于使用Alpa对于资源的消耗会低不少)。
- 进行大模型模型训练时,先使用小规模模型(如:OPT-125m/2.7b)进行尝试,然后再进行大规模模型(如:OPT-13b/30b…)的尝试,便于出现问题时进行排查。目前来看,业界也是基于相对较小规模参数的模型(6B/7B/13B)进行的优化,同时,13B模型经过指令精调之后的模型效果已经能够到达GPT4的90%的效果。
教训:
- 针对已有的环境进行分布式训练环境搭建时,一定要注意之前环境的python、pip、virtualenv、setuptools的版本。不然创建的虚拟环境即使指定对了Python版本,也可能会遇到很多安装依赖库的问题(GPU服务器能够访问外网的情况下,建议使用Docker相对来说更方便)。
- 遇到需要升级GLIBC等底层库需要升级的提示时,一定要慎重,不要轻易升级,否则,可能会造成系统宕机或很多命令无法操作等情况。