




一、介绍
我们在数据处理的时候,经常遇到一些无法归类的数据,但又想用到这些数据,我们需要一种方法,帮我们快速归类整理这些数据,这时候我们需要用到聚类。
在没有可用的标记数据时,聚类是一种灵丹妙药。聚类是一种分组方法,它可以将一组数据划分为若干个类似的组(也称作簇)。这些组通常代表了原始数据集中不同的类别或群组,每个组内的数据项具有相似的特征。与描述未知样本的概率分布不同,聚类的目的是将数据划分为几个有意义的结构,而不是描述原始数据的精确方法。我们看下面这张表。
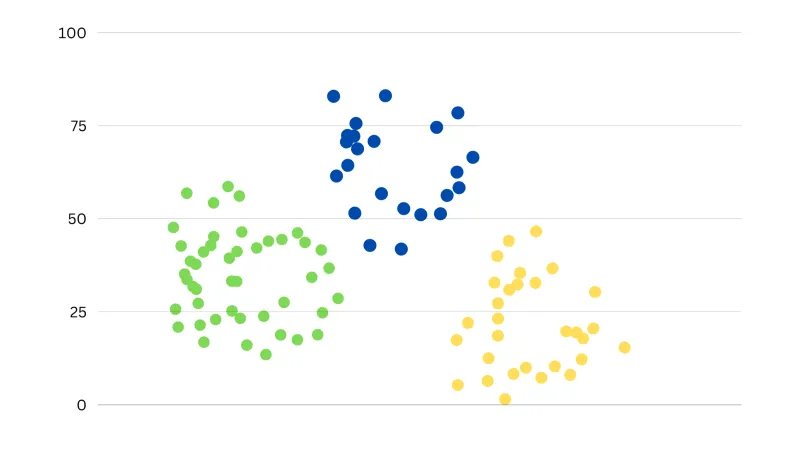
我们可以看到 3 个集群。这就是对数据进行聚类时数据的样子。但是如果有很多特征,那么像这样将它形象化就更难了。
聚类是一种无监督学习方法,它通过将数据分成几组,使每组内部的数据尽可能相似,而每组之间的数据尽可能不同,来帮助我们理解数据并发现隐藏在数据中的潜在规律和群体。聚类算法不需要我们提供任何标记数据,它会根据数据本身的特征来进行分组。
聚类能帮助我们发现数据中的相似性和差异。举个例子,假设你有一个数据集,其中包含若干人的年龄、身高和体重。如果你使用聚类算法对这些人进行分组,可能会发现年轻人和年长人分别成为一组,身高高的人和身高矮的人分别成为一组,体重轻的人和体重重的人分别成为一组。这就是聚类的一个例子,它能够帮助你发现数据中的相似性和差异。
二、算法实现
聚类是一种无监督的机器学习模型,它的目的是将数据集分成若干个簇,其中每个簇都包含相似的数据项。常用的聚类有三种实现方法
- 主成分分析(Principal Component Analysis,PCA)是一种用来简化数据集的技术,通过找到数据集中最重要的特征,并将数据投影到这些特征上来减少数据集的维度。主成分分析可以帮助我们更好地理解数据,并且可以用来降低数据集中的噪声。
- K-means :通过不断迭代来将数据集分成 K 个不同的类别。K-means算法通过计算每个数据点与聚类中心(称为“质心”)的距离来将数据点分配到距离它最近的聚类中心所属的类别中。K-means算法重复这个过程直到最终的类别不再发生变化。
- 层次聚类(hierarchical clustering):通过不断合并与拆分聚类来建立数据点之间的层次关系,实现将数据集分成不同的类别。层次聚类算法的主要优点是可以清晰地展示数据点之间的层次关系,它的主要缺点是很难确定最优的类别数量,而且当数据集较大时,计算代价会很高。
三、算法的优缺点
优点
- 主成分分析能有效地减少数据的维度,提高算法的计算效率。
- K-means收敛快,易于实现
- 层次聚类可以很好地展示数据之间的层次关系,在可视化方面很强
缺点
- 主成分分析无法对类别变量进行处理,且容易丢失一些有用信息。
- K-means对初始值敏感,难以处理具有非凸形簇的数据。
- 层次聚类计算量大,难以处理大数据集。
四、使用场景
以下是我整理的5个聚类算法的使用场景
- 协作过滤(collaborative filtering):协作过滤是一种推荐系统,它利用用户之间的兴趣相似度来为用户提供推荐。协作过滤可以将具有相似兴趣的用户归为一类,这有助于提高协作过滤的准确性。例如,Netflix 和 Spotify 都使用了聚类技术来提供用户推荐。举个例子。假设你和你的朋友都喜欢看电影,并且你们都在一个电影评分网站上提供了自己看过的电影的评分。那么,这个网站就可以使用协作过滤技术来为你提供电影推荐。它会将你和你的朋友归为一类,因为你们在电影方面有相似的兴趣。
- 客户细分(customer segmentation):客户细分与协作过滤非常相似的算法。客户细分为不同的部分或细分,以便进行营销和销售策略。是根据共同的需求、偏好或特征,例如年龄、收入、职业等来定义的。通过客户细分,公司可以为不同的客户群提供更有针对性的产品和服务,从而增强客户满意度和忠诚度。举个例子,假设你是一家电信公司的客户,并且使用了该公司的多种服务,例如宽带、手机、电视等。那么,这家电信公司可以使用客户细分技术来给你提供个性化的服务,它会根据你的属性(例如年龄、性别、收入水平等)将你归为一类,然后根据这一类的特点向你提供其他服务。例如,如果你和其他客户一样,属于年轻人群体,那么电信公司可能会向你推荐年轻人喜欢的电信套餐。
- 数据汇总(Data summarization):数据汇总是指对数据集中的数据进行汇总和统计,以便对数据集进行分组。例如,通过计算每个组中数据项的平均值,可以对数据集进行聚类并找出数据集中的潜在模式。数据汇总是聚类算法的一个重要组成部分,因为它允许我们更好地了解数据集并对数据进行有效分析。几个例子,假设你有一个数据集,其中包含不同年龄段的人的身高和体重信息。为了进行数据汇总,你可以按年龄段对这些数据进行分组,并计算每个年龄段中人的平均身高和体重。这样,你就可以对不同年龄段的人的身高和体重进行比较和分析,从而更好地了解这个数据集。
- 动态趋势检测(Dynamic trend detection):动态趋势检测是指在数据集中动态检测趋势的过程。在聚类算法中,动态趋势检测可以通过对数据集进行聚类,并对聚类结果进行实时监测,以捕捉数据集中的动态变化。可以帮助我们更好地了解数据集,并能够及时发现数据集中可能出现的潜在模式。举个例子,假设你想对一组消费数据进行分析,以了解消费者的购买行为。你可以使用聚类算法将消费数据分为不同的组,例如按消费者的年龄和收入水平来分组。然后,你可以使用动态趋势检测来实时监测每个组的购买行为,以捕捉到消费者的购买趋势可能发生的变化。通过这种方法,你可以更好地了解消费者的购买行为,并能够及时发现消费者的购买趋势可能出现的改变。
- 社交网络分析(Social network analysis):社交网络分析是一种研究人际关系的方法,它通过分析社交网络中的连接关系,来了解人们之间的关系和交流模式。社交网络分析可以通过计算社交网络中的网络指标来实现,例如度中心性、接近中心性和社区结构。通过这些指标,我们可以了解社交网络中人们之间的关系,并捕捉到社交网络中可能出现的模式和变化。社交网络分析在社会科学、市场营销和其他领域都有广泛的应用。举个例子,假设你想分析一组用户数据,以了解用户之间的社交关系。你可以构建一个用户之间的关系网络,其中,每个用户都是一个点,如果两个用户之间存在关系,就在两个用户之间连一条边。然后,你可以使用社交网络分析方法来分析这个网络,并计算网络指标,例如度中心性和接近中心性。通过这些指标,你就可以了解用户之间的社交关系,并捕捉到社交网络中可能出现的模式和变化。
注:度中心性是一种网络指标,它衡量一个点在网络中的重要性。一个点的度中心性越高,说明这个点与其他点的连接越多,在网络中的重要性就越高。度数指的是一个点与其他点的连接数。