




介绍
问答一直是自然语言处理 (NLP) 中最具影响力的可落地产品之一。在本文中,我们重点关注文献中研究的两大类问答:开放式检索问答 (ORQA) 和阅读理解 (RC)。
开放式检索 QA 与阅读理解
开放式检索 QA 侧重于最一般的设置,在这种情况下,给定一个问题,我们首先需要从百科知识等大型语料库中检索相关文档。然后我们处理这些文档以确定相关答案,如下所示。我们避免使用术语开放域 QA,因为“开放域”也可以指涵盖许多域的设置。

阅读理解可以看作是开放式检索 QA 的一个子问题,因为它假设我们可以访问包含答案的重要段落(见下文)。那么我们只需要在这段中找到相应的答案即可。在这两种设置中,答案通常表示为最小跨度。

阅读理解的标准方法建立在 BERT 等预训练模型之上。该模型以问题和候选段落作为输入,并经过训练以预测问题是否可回答(通常使用与其 [CLS] 标记关联的表示)以及每个标记是答案跨度的开始还是结束,这可以在下面看到。相同的方法可以用于 ORQA,并进行一些修改。

使用 BERT 进行阅读理解涉及对其进行微调以预测:
-
问题是否可以回答以及
-
每个标记是否是答案范围的开始和结束。
信息检索 (IR) 方法用于检索相关段落。经典的稀疏方法,如 BM25不需要任何训练,因为它们使用tf-idf度量根据频率来权衡术语和文档。最近的密集神经方法,如 DPR 训练模型以最大化问题和段落之间的相似性,然后通过最大内积搜索检索最相关的段落。
什么是域?
域可以看作是高维多样性空间中的维度,该空间由社会人口统计学、语言、流派、句子类型等多个维度组成。域在粒度方面有所不同,大型域(例如 Twitter)可以包含几个更窄的域,我们可能希望调整我们的模型。这个多样性空间的两个主要方面是流派(我们将这个术语与“领域”互换使用)和语言,这将是本文的重点。

多域质量保证
在这篇文章的两个主要部分中,我们将首先讨论常见的数据集,然后是建模方法。
多领域 QA 数据集
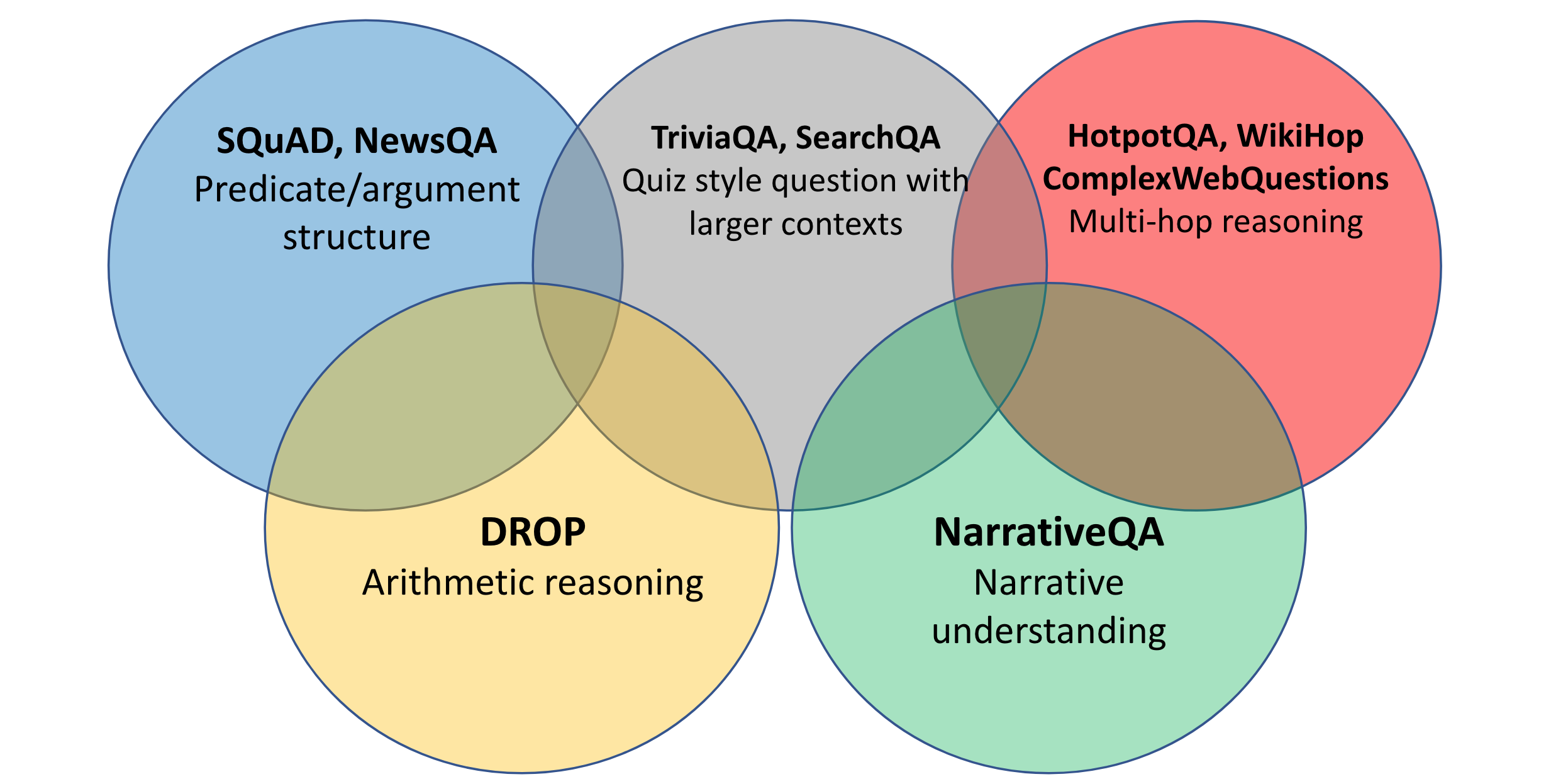
问答系统的研究已经跨越了许多领域,如下所示。最常见的领域是Encyclopedia,它涵盖了许多基于百科的数据集,例如 SQuAD(Rajpurkar 等人,2016 年)、Natural Questions(NQ;Kwiatkowski 等人,2019 年)、DROP(Dua 等人,2019 年)和WikiReading(Hewlett 等人,2016 年)等。此域中的数据集通常称为“开放域”QA。

RC Olympics:阅读理解的多个领域
小说领域的数据集通常需要处理书籍中的叙述,例如 NarrativeQA(Kočiský 等人,2018 年)、儿童图书测试(Hill 等人,2016 年)和 BookTest(Bajgar 等人,2016 年)或人群撰写的叙述workers,例如 MCTest、MCScript 和 ROCStories。
学术测试数据集针对美国学校测试中的科学问题,如 ARC、大学水平考试资源如 ReClor和学校水平考试资源如 RACE 。
新闻数据集包括 NewsQA、CNN/每日邮报和 NLQuAD。
此外,还有专注于专业专家材料的数据集,包括手册、报告、科学论文等。此类领域在行业中最为常见,因为公司越来越多地使用特定领域的聊天机器人来响应用户查询,但相关的数据集很少可用. 现有数据集集中在 TechQA和 AskUbuntu和 Qasper。此外,大流行见证了许多与 COVID-19 相关的数据集的创建,例如 COVID-QA-2019、COVID-QA-147和 COVID-QA-111。
除了这些专注于单个领域的数据集之外,还有一些跨越多个领域的数据集,例如 CoQA、QuAIL 和 MultiReQA 等. 最后,ORB评估服务器支持跨多个域的数据集评估系统。
多领域 QA 模型
在大多数情况下,当在多域环境中学习时,目标域中可用的标记数据可能有限或没有。我们讨论了如何仅使用未标记的数据来适应目标领域,在 QA 中使用预训练语言模型进行领域适应的最有效方法,以及如何跨领域进行泛化。
QA 的无监督领域适应
QA 的无监督域自适应假定访问源域中的标记数据和未标记的目标域数据。在目标域中没有标记的黄金数据的情况下,大多数方法依赖于在目标域中生成“白银”<问题、段落、答案>数据。为此,这些方法在源域上基于预训练的 LM 训练问题生成模型,然后将其应用于目标域以生成给定答案跨度的合成问题。然后,QA 模型在黄金源域和白银目标域数据上联合训练,如下所示。这通常与其他领域适应策略相结合,例如对抗性学习和自我训练。

使用 BART 或 T5 生成的金源和银目标域数据的联合训练
使用预训练的 LM 进行域适应
在许多具有专门领域的场景中,像 BERT 这样的通用预训练语言模型可能不够用。相反,在目标域数据上预训练的 LM 的域自适应微调通常表现更好。最近的例子,例如 BioBERT和 SciBERT分别对生物医学和科学领域有效。
当源域和目标域中的标记数据可用时,一般方法是首先在标记的源域数据上微调模型,然后在目标域中的标记数据上微调模型。然而,简单的微调通常会导致源域中的性能下降,这可能是不希望的。相反,来自持续学习的策略,如 L2 正则化 可确保在目标域上微调的模型参数不会与源域模型出现显着差异,从而减少灾难性遗忘,如图所示以下。

L2 正则化等策略在对目标域 (BioASQ) 进行微调后在源域 (SQuAD) 上产生了合理的性能
对于资源极少的领域,另一种策略是明确地使模型适应目标领域的特征。如果目标域包含专业术语,则可以使用这些术语扩充模型的词汇表以学习更好的表示。此外,对于许多领域,未标记数据的结构可以包含可能对最终任务有用的信息。可以利用诸如摘要、错误描述、相关原因等结构来生成可以微调模型的合成数据。
在开放检索设置中,在源域上训练的密集检索方法可能不会以零样本的方式泛化到低资源目标域。相反,我们可以利用上一节中讨论的相同问题生成方法来创建用于在目标域上训练检索模型的银数据。在 BM25 和经过调整的 DPR 模型上进行集成可产生最佳结果。
域泛化
在实践中,在单个域上微调的预训练模型通常泛化能力很差。在多源分布上进行训练减少了选择单一源数据集的需要。即使在使用预训练模型时,对相关任务的额外微调也有帮助。
然而,不同的数据集通常具有不同的格式,这使得在没有特定任务工程的情况下很难为它们训练联合模型。最近经过预训练的 LM(例如 T5)促进了这种跨数据集学习,因为每个数据集都可以转换为统一的文本到文本格式。使用这种文本到文本格式跨多个 QA 数据集联合训练模型可以更好地泛化到不可见的域。
多语言质量保证
语言可以被视为领域流形的另一个方面。正如我们将看到的,上一节中讨论的许多方法也可以成功应用于多语言设置。同时,多语言 QA 提出了自己独特的挑战。
多语言 QA 数据集
许多早期的多语言 IR 和 QA 数据集已作为社区评估的一部分被收集。许多测试集使用新闻专线文章,例如 TREC1994-2004 的 CLIR、CLEF 2003-2005 的 QA或维基百科,例如 CLEF 2006-2008 的 QA。这些数据集主要集中在印欧语系,尽管最近的数据集也涵盖了其他语言,例如 FIRE 2012 上的印地语和孟加拉语。
单语阅读理解 数据集种类繁多,其中许多是 SQuAD 的变体。其中大部分有中文、俄文和法文版本,它们通常包含每种语言的自然数据。
单语开放检索 QA 数据集本质上更加多样化。它们根据提供的背景类型和数量而有所不同,并且通常侧重于专业领域,从中国历史考试到中国孕妇论坛和波兰语“你知道吗?” 问题。

MLQA 对齐和注释过程
多语言阅读理解 数据集通常是使用翻译创建的。MLQA(Lewis 等人,2020 年),如上图所示,是通过跨多种语言自动对齐维基百科段落并在对齐的段落上注释问题和答案而创建的。然而,这种自动对齐可能会导致某些语言出现严重的质量问题,并可能导致过度拟合对齐模型的偏差。另一个数据集 XQuAD是通过专业地将 SQuAD 的一个子集翻译成其他 10 种语言而创建的。最后,MLQA-R 和 XQuAD-R是以前的数据集到答案句子检索设置的转换。
多语言开放检索 QA 数据集通常由自然数据组成。XQA涵盖了“你知道吗?” 维基百科问题转换为完形填空格式对于每个问题,都会提供 BM25 排名前 10 位的维基百科文档作为上下文。TyDi QA 要求注释者根据简短的维基百科提示以不同类型的语言编写“信息搜索”问题。与 MLQA 和 XQuAD 等 RC 数据集相比,此类信息搜索问题导致较少的词汇重叠,从而导致更具挑战性的 QA 设置。然而,由于语言维基百科用于查找上下文段落(通过谷歌搜索),并且由于许多代表性不足的语言的维基百科非常小,TyDi QA 中的许多问题无法回答。

XOR-TyDi QA 注释过程
XOR-TyDi QA(Asai 等人,2021 年)通过上述过程解决了这个问题,该过程将无法回答的 TyDi QA 问题翻译成英文,并从英文维基百科中检索上下文段落。这种策略显着减少了无法回答的问题的比例。XOR-TyDi QA 侧重于跨语言检索,而 Mr. TyDi使用语言内文档增强 TyDi QA 以评估单语言检索模型。由于 TyDi QA 中的答案是一个句子中的跨度,Gen-TyDi QA 使用人工生成的答案扩展了数据集,以实现对生成 QA 模型的评估。最后,MKQA将来自 Natural Questions(Kwiatkowski 等人,2019 年)的 10k 个查询翻译成其他 25 种语言。此外,它还使用直接链接到维基数据实体的注释来扩充数据集,从而实现跨度提取之外的评估。
多语言 QA 数据集的一个新兴类别是多语言常识推理。此类数据集由翻译成其他语言的多项选择断言组成(Ponti 等人,2020 年;Lin 等人,2021 年)。
多语言 QA 数据集的问题
现有的单语言和多语言 QA 数据集有一些应该注意的问题。
语言分布 现有的数据集主要集中在有大量数据可用的“高资源”语言上。在此类数据集上评估 QA 模型提供了对该领域进展的扭曲看法。例如,可以通过字符串匹配解决的问题在英语中很容易,但在词法丰富的语言中就难得多 ( Clark et al., 2020)。在当前 NLP 的关键应用中,QA 具有最低的语言全局效用,即跨世界语言的平均性能(Blasi et al., 2021),如下所示。虽然 QA 数据集涵盖了很多人使用的语言,但要公平地覆盖世界上的所有语言,还有很长的路要走。

不同 NLP 应用程序的语言和人口统计学效用(Blasi 等人,2021 年)
同质性 为了使集合具有可扩展性,多语言数据集通常会收集跨语言涵盖相同问题或相似主题的数据,从而遗漏特定语言的细微差别。此外,对每种语言都进行深入的错误分析通常是不可行的。最常见的同质性来源是翻译,它有自己的偏见。
翻译的局限性 “Translationese”在很多方面都不同于自然语言(Volanksy et al., 2015)。翻译后的问题通常在目标语言维基百科中没有答案(Valentim 等人,2021 年)。此外,通过翻译创建的数据集会继承人为因素,例如 NQ 中大量的训练-测试答案重叠(Lewis 等人,2020 年),翻译也会导致新的人为因素,例如在 NLI 中,当前提和假设分别翻译时(Artetxe 等人)等人,2020 年)。最后,翻译后的问题与不同语言的人“自然”提出的问题类型不同,导致以英语和西方为中心的偏见。
以英语和西方为中心的偏见 许多 QA 数据集中的示例都偏向于英语使用者提出的问题。不同文化通常会问什么类型的问题,例如,美国以外的演讲者可能不会问著名的美式足球或棒球运动员。在 COPA ( Roemmele et al., 2011 ) 中,许多参考对象在某些语言中没有特定语言的术语,例如保龄球、汉堡包、彩票 ( Ponti et al., 2020 )。常识性知识、社会规范、禁忌话题、社会距离评估等也与文化有关(Thomas,1983). 最后,英语数据训练的共同设置导致高估类似于英语的语言的迁移性能,而低估更远语言的迁移性能。
对检索的依赖性在检索 到的文档中识别开放域 QA 的最小跨度的标准设置有利于提取系统。它假设只有一个黄金段落提供了正确答案,并且不考虑来自其他段落或页面的信息。对于无法回答的问题,通常可以在未检索到的其他页面中找到答案(Asai & Choi,2021)。
信息稀缺 典型的知识资源,如特定语言的维基百科,通常不包含相关信息,特别是对于代表性不足的语言。对于此类语言,数据集必须是跨语言的。此外,有些信息只能从其他来源获得,例如 IMDb、新闻文章等。
多语言比较 的困难 由于问题难度的不同级别、单语数据的数量和质量、翻译的影响等一系列因素,比较不同语言的模型性能很困难。相反,最好是执行系统-跨语言的水平比较。
单语言与多语言 QA 数据集 创建多语言 QA 数据集非常昂贵,因此通常不符合学术预算。相比之下,单语 QA 数据集的工作通常被认为是“利基”。然而,这样的工作可以说比会议上普遍接受的增量建模进步更重要和更有影响力(Rogers 等人,2021 年)。为了促进 NLP 的包容性和多样性,关键是要启用和奖励此类工作,特别是对于代表性不足的语言。特定语言的 QA 数据集可以超越英语工作的“复制”,例如,对特定语言的现象进行分析并扩展或改进 QA 设置。
创建 QA 数据集
大规模高效多语言 QA 评估 多语言 QA 的 一个主要挑战是缺乏多种语言的数据。我们可以创建有针对性的测试来探测特定功能,例如使用 CheckList( Ribeiro 等人,2020 年),而不是用每种语言标记大量数据以覆盖整个分布。这样,少量的模板就可以涵盖许多不同的模型功能。迄今为止,此类基于模板的测试已用于评估多语言阅读理解(Ruder 等人,2021 年)和闭卷 QA(Jiang 等人,2020 年;Kassner 等人,2021 年)) ,它们支持跨语言的细粒度评估,如下所示。然而,为了跨语言扩展此类测试,仍然需要母语人士的专业知识或翻译。

mBERT(左)和 XLM-R(右)在 MultiCheckList 中跨不同语言的英语 SQuAD v1.1 上微调的错误率(Ruder 等人,2021 年)
最佳实践 创建新的 QA 数据集时,重要的是要关注您要用数据集回答的研究问题。尽量避免创建混淆变量(翻译、词法、语法等)来混淆这些问题的回答。考虑使用类型多样的语言集收集数据,并考虑数据集的用例以及基于数据的系统如何帮助人类。选择合适的数据集格式:如果您想帮助世界各地的人们回答问题,请专注于信息搜索问题并避免文化偏见。如果你想帮助用户提出有关简短文档的问题,请专注于阅读理解。最后,为了创建具有包容性和多样性的 QA 数据集,与演讲者社区合作并进行参与式研究非常重要(∀等人,2020)。
多语言质量保证评估
多语言 QA 中的常见评估设置范围从所有数据都使用相同语言的单语言 QA 到问题、上下文和答案可以使用不同语言的****跨语言场景,以及训练数据的零样本跨语言 传输设置使用高资源语言,测试数据使用另一种语言。
评估指标基于使用精确匹配 (EM) 或平均标记 F1 的词汇重叠,并可选择对预测和答案进行预处理(Lewis 等人,2020 年)。然而,这种基于标记的指标不适用于没有空格分隔的语言,并且需要特定于语言的分割方法,这会引入对评估设置的依赖。此外,基于字符串匹配的指标会惩罚形态丰富的语言,因为提取的跨度可能包含不相关的语素,有利于提取系统而不是生成系统,并且偏向于简短的答案。
或者,可以在字符或字节级别执行评估。由于用于自然语言生成 (NLG) 的标准指标(例如 BLEU 或 ROUGE)与人类对某些语言的判断几乎没有相关性(Muller 等人,2021 年),因此基于强大的预训练模型(例如 BERTScore)学习指标(Zhang 等人., 2020)或 SAS(Risch 等人,2021)可能是首选,特别是对于评估生成模型。
多语言质量保证模型
QA 的多语言模型通常基于预训练的多语言 Transformer,例如 mBERT(Devlin 等人,2019 年)、XLM-R(Conneau 等人,2020 年)或 mT5(Xue 等人,2021 年)。
多语言阅读理解模型
对于阅读理解,多语言模型通常对英语数据进行微调,然后通过零样本迁移应用于目标语言的测试数据。最近的模型通常在标准 QA 数据集中存在的高资源语言上表现良好,而在具有不同脚本的语言上表现略低(Ruder 等人,2021),如下所示。在针对特定任务的数据进行训练之前,使用掩码语言建模 (MLM) 对目标语言的数据模型进行微调通常会提高性能(Pfeiffer 等人,2020 年)。

代表性模型在 XQuAD(左)和 MLQA(右)上的零样本跨语言迁移性能 (F1)(Ruder 等人,2021 年)
在实践中,与零样本迁移相比,对一些标记的目标语言示例进行微调可以显着提高迁移性能(Hu 等人,2020 年;Lauscher 等人,2020 年)。然而,对于更具挑战性的开放式检索 QA,情况并非如此(Kirstain 等人,2021 年)。对多种语言的数据进行多任务训练可进一步提高性能(Debnath 等人,2021 年)。
大多数关于多语言 QA 的先前工作都使用翻译测试设置,它将所有数据翻译成英语——通常使用在线 MT 系统作为黑匣子——然后将经过英语训练的 QA 模型应用于它(Hartrumpf 等人,2008 年;Lin 和 Kuo,2010 年;Shima 和 Mitamura,2010 年)。为了将预测的英语答案映射到目标语言,答案跨度的反向翻译效果不佳,因为它与段落上下文无关。相反,最近的方法利用神经 MT 系统的注意力权重将英语答案跨度与原始文档中的跨度对齐(Asai 等人,2018 年;Lewis 等人,2020 年)。
或者,在翻译训练设置中,英语训练数据被翻译成目标语言,目标语言 QA 模型在数据上进行训练。在这种情况下,至关重要的是确保答案跨度在翻译后可以通过用标签括起来或使用模糊搜索来恢复(Hsu 等人,2019 年;Hu 等人,2020 年)。我们可以更进一步,将英语数据翻译成我们训练多语言 QA 模型的所有目标语言。这种translate-train-all设置通常对阅读理解表现最好(Conneau 等人,2020 年;Hu 等人,2020 年;Ruder 等人,2021 年)) 并在高资源语言上实现接近英语的性能,但在其他语言上性能较低。下面的流程图显示了根据可用数据哪种方法可以获得最佳性能。

多语言阅读理解流程图
多语言开放检索 QA 模型
翻译测试是开放式检索 QA 的标准方法,因为它只需要访问英文资源。除了在英语数据上训练文档阅读器模型外,开放式检索设置还需要训练英语检索模型。在推理过程中,我们将模型应用于翻译后的数据,并将答案回译为目标语言,如下所示。然而,低质量的 MT 可能会导致错误传播,并且某些问题的答案可能无法在英文维基百科中找到。另一方面,翻译训练在开放式检索设置中通常是不可行的,因为它需要将所有可能的上下文(例如整个维基百科)翻译成目标语言。作为替代方案,只能翻译问题,这可能优于翻译测试(Longpre 等人,2020)。
![]()
在开放式检索 QA 设置中使用翻译测试进行推理(注意:标志用作简洁的视觉表示,并不意味着反映特定的语言多样性)
在不使用翻译的情况下,我们需要训练跨语言检索和文档阅读器模型,这些模型可以评估问题和上下文段落之间的相似性以及跨语言的答案跨度。为此,我们需要使用目标语言问题和英语上下文来微调预训练的多语言模型。然而,限制对英文文档的检索限制了我们可支配的观点和知识来源。因此,我们希望将检索扩展到多种语言的文档。
微调预训练的多语言模型以仅检索英语数据的段落并不能很好地泛化到其他语言,类似于多域设置。为了训练更好地泛化到其他语言的检索模型,我们可以在多语言数据上微调模型(Asai 等人,2021 年)。或者,我们可以使用数据扩充。与多领域设置类似,我们可以通过生成合成目标语言问题来获得目标语言的银数据,在这种情况下使用翻译训练模型(Shi et al., 2021)。此外,我们可以使用维基百科中的语言链接获得弱监督示例,如下所示(Shi 等人,2021 年;浅井等人,2021 年)。具体来说,我们检索与原始答案和其他语言的答案段落对应的文章,并将它们用作新的训练示例。最后,BM25 + 密集检索的组合在此设置中也表现最佳 ( Zhang et al., 2021 )。

通过维基数据语言链接进行跨语言数据扩展;基于Asai 等人的示例。(2021)
为了聚合不同语言的检索到的段落,我们可以训练一个预训练的多语言文本到文本模型,例如 mT5,以在将段落作为输入提供时生成答案(Muller 等人,2021 年;Asai 等人,2021 年) ). 由多语言检索和答案生成模型组成的完整管道如下所示。由于该模型只会学习以现有数据集涵盖的语言生成答案,因此数据扩充再次成为关键。此外,可以使用新检索和新识别的答案作为后续迭代中的附加训练数据对模型进行迭代训练(Asai 等人,2021 年)。最好的模型在完全开放检索设置中实现了强大的性能,但仍有很大的空间。

多语言检索和多语言答案生成管道(Asai 等人,2021 年)
多语言开放式检索 QA 最具挑战性的两个方面是找到包含答案的段落(段落选择)和识别文档是否包含查询的答案(可回答性预测;Asai & Choi,2021)。一个相关的问题是答案句子选择,其中模型预测句子是否包含答案(Garg 等人,2020 年)。无法回答通常是由于文档检索错误或需要多个段落才能回答的无法回答的问题。为了解决这个问题,Asai 和 Choi (2021)建议 a) 超越使用维基百科进行检索;b) 提高现有和未来数据集中带注释问题的质量;c) 从提取跨度到生成答案。
开放研究方向
多模态问答 对于许多语言变体和领域,以其他模态获取数据可能更容易。作为最近的一个例子,SD-QA(Faisal 等人,2021 年)通过与四种语言和多种方言的问题相匹配的口头话语来增强 TyDi QA。
其他领域:时间和地理 一个领域可以包括现有工作中未涵盖的许多方面。例如,答案通常取决于语言之外的上下文,例如提问的时间和地点。SituatedQA ( Zhang & Choi, 2021) 在 Natural Questions 中增加了依赖于时间和地理的上下文的上下文相关问题来研究这些问题。

SituatedQA 中的时间和地理问题上下文(Zhang & Choi,2021)
语码转换 语码转换是多语言社区中的普遍现象,但在 QA 研究中大多被忽视。孟加拉语、印地语、泰卢固语和泰米尔语的资源很少(Raghavi 等人,2015 年;Banerjee 等人,2016 年;Chandu 等人,2018 年;[Gupta 等人,2018 年)。如需更广泛地了解语码转换,请查看此调查(Doğruöz 等人,2021 年)。
多语言多领域泛化大多数开放式检索 QA 数据集仅涵盖维基百科,而许多在现实世界应用中很重要的领域(例如技术问题)只有英语 QA 数据集。其他没有太多数据的领域在非西方环境中特别相关,例如小企业的金融、法律和健康问题。此外,目前无法回答的问题需要从更广泛的领域中检索信息,例如 IMDb(Asai 等人,2021 年)。为了创建真正的开放域 QA 系统,我们因此需要训练开放检索 QA 系统来回答来自许多不同领域的问题。
数据增强 除了翻译和检索之外,很少探索合成多语言 QA 数据的生成(Shi 等人,2021 年)。生成有关非西方实体的数据可能特别有用。
生成式问答 在大多数现有的 QA 数据集中,简短的答案是上下文中的一个跨度。为了更有效地训练和评估模型,更多的数据集需要包含更长、更自然的答案。然而,生成长格式答案尤其具有挑战性(Krishna 等人,2021 年)。
聚合来自不同来源的证据 我们需要开发更好的聚合方法来覆盖推理路径,例如用于多希望推理(Asai 等人,2020 年)。模型还需要能够生成忠实于检索到的段落的答案,需要明确的答案归因。最后,我们需要能够有效结合来自不同领域甚至不同模式的证据的方法。
对话式问答 当前的开放式检索 QA 数据集通常是单轮的,不依赖于任何外部上下文。为了训练普遍有用的 QA 系统,模型还应该能够考虑 QuAC 等数据集所需的对话上下文(Choi 等人,2018 年)。特别是,他们应该能够处理共指,要求对模棱两可的问题进行澄清等。