




随着人工智能的迅猛发展,高质量数据的重要性已愈发明显。以大型语言模型为例,近年来的飞跃式进展在很大程度上依赖于高质量和丰富的训练数据集。相比于GPT-2,GPT-3在模型架构上的改变微乎其微,更大的精力是投入到了收集更大、更高质量的数据集来进行训练。例如,ChatGPT与GPT-3的模型架构类似,但使用了RLHF(来自人工反馈过程的强化学习)来生成用于微调的高质量标注数据。
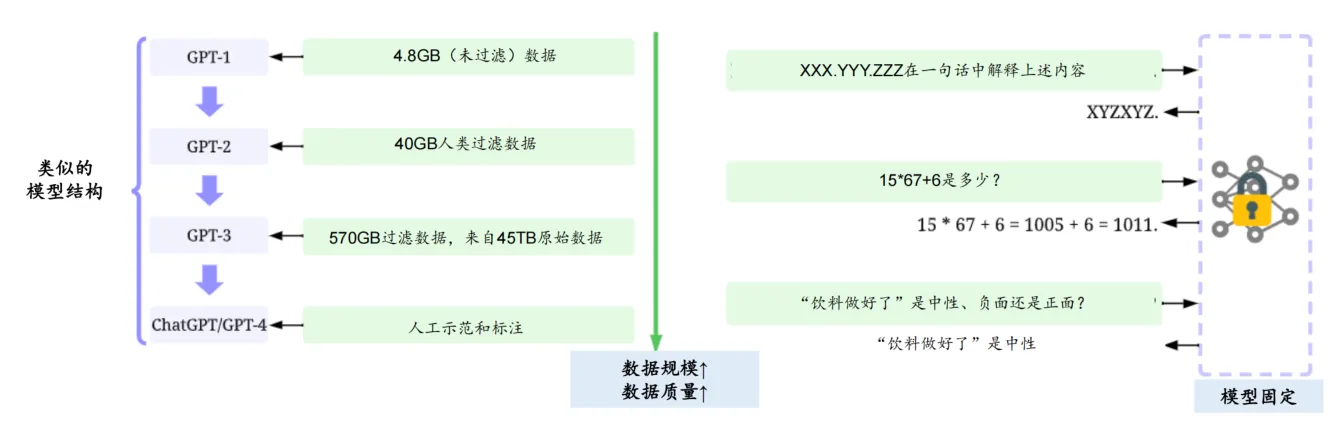
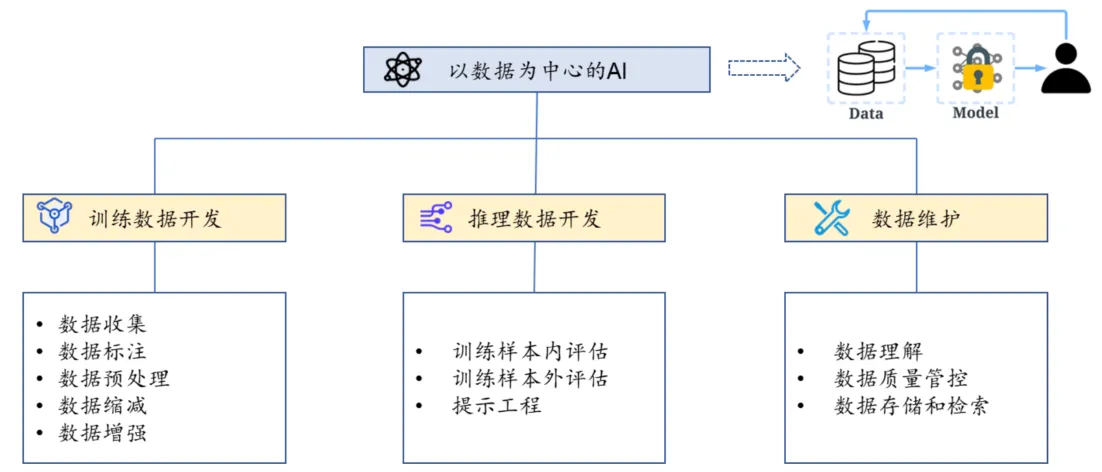
认识到这一现象,人工智能领域的权威学者吴承恩发起了“以数据为中心的 AI”运动,这是一种新的理念,它主张在模型架构相对固定的前提下,通过提升数据的质量和数量来提升整个模型的训练效果。这其中包括添加数据标记、清洗和转换数据、数据缩减、增加数据多样性、持续监测和维护数据等。因此,未来在大模型开发中,数据成本(包括数据采集、清洗、标注等成本)所占的比例可能会逐步提高。
AI大模型需要的数据集应具备以下特性:
1)高质量:高质量的数据集可以提高模型的精度和可解释性,同时缩短模型收敛到最优解的时间,也就是训练时长。
2)大规模:在《Scaling Laws for Neural Language Models》一文中,OpenAI提出了LLM模型的"伸缩法则",即独立增加训练数据量、模型参数规模或延长模型训练时间,预训练模型的效果会持续提升。
3)多样性:数据的多样性有助于提高模型的泛化能力,过于单一的数据可能会导致模型过度拟合训练数据。
数据集的生成与处理
数据集的建立流程主要包括以下步骤:
- 数据采集:数据采集的对象可能包括各种类型和格式的视频、图片、音频和文本等。数据采集常用的方式有系统日志采集方法、网络数据采集方法以及ETL。
- 数据清洗:因为采集到的数据可能存在缺失值、噪声数据、重复数据等质量问题,数据清洗就显得尤为重要。数据清洗作为数据预处理中至关重要的环节,清洗后的数据质量在很大程度上决定了AI算法的有效性。
- 数据标注:这是流程中最重要的一个环节。管理员会根据不同的标注需求,将待标注的数据划分为不同的标注任务。每一个标注任务都有不同的规范和标注点要求,一个标注任务将会分配给多个标注员完成。
- 模型训练:模型训练人员会利用标注好的数据训练出需要的算法模型。
- 模型测试:测试人员进行模型测试并将测试结果反馈给模型训练人员,模型训练人员通过不断地调整参数,以便获得性能更好的算法模型。
- 产品评估:产品评估人员需要反复验证模型的标注效果,并对模型是否满足上线目标进行评估。只有经过产品评估环节的数据才算是真正过关。
然而,尽管中国的数据资源丰富,但由于数据挖掘不足,数据无法在市场上自由流通等因素,导致优质的中文数据集仍然稀缺。据统计,ChatGPT的训练数据中,中文资料的比重不足千分之一,而英文资料占比超过92.6%。此外,加利福尼亚大学和Google研究机构的研究发现,目前机器学习和自然语言处理模型使用的数据集有50%是由12家顶级机构提供,其中10家为美国机构,1家为德国机构,只有1家机构来自中国,即香港中文大学。
我们认为,国内缺乏高质量数据集的原因主要有以下几点:
- 高质量数据集需要巨大的资金投入,但目前国内对数据挖掘和数据治理的投入不足。
- 国内相关公司往往缺乏开源意识,导致数据无法在市场上自由流通。
- 国内相关公司成立较晚,数据积累相对于国外公司要少。
- 在学术领域,中文数据集的重视程度低。
- 国产数据集的市场影响力和普及度相对较低。
目前,国内科技互联网头部企业主要通过公开数据和自身特有数据来训练大模型。例如,百度的“文心”大模型使用的特有数据主要包括万亿级的网页数据,数十亿的搜索数据和图片数据等。阿里的“通义”大模型的训练数据主要来自阿里达摩院。腾讯的“混元”大模型的特有训练数据主要来自微信公众号、微信搜索等优质数据。华为的“盘古”大模型的训练数据,除了公开数据,还有B端行业数据加持,包括气象、矿山、铁路等行业数据。商汤的“日日新”模型的训练数据中,包括了自行生成的Omni Objects 3D多模态数据集。
中国的数据环境和未来
尽管现状尚有不足,但中国的数据环境仍有巨大的潜力。首先,中国是全球最大的互联网用户群体,日产数据量巨大,为构建大规模高质量数据集提供了基础。其次,中国政府对于AI和数据治理的重视,无论是政策支持还是资金投入,都为数据环境的改善和发展提供了有利条件。
未来,中国需要在以下几个方面进行努力:
- 建立数据采集和清洗系统:建立一套完整的数据采集和清洗系统,确保数据的质量和有效性,为后续的模型训练提供可靠的数据基础。
- 提高公开数据的可获取性和使用性:鼓励公司、研究机构等公开数据,让数据在市场中自由流通,从而提高数据的可获取性和使用性。
- 加大数据标注投入:通过提高标注效率和质量,降低标注成本,从而获取更多、更高质量的标注数据。
- 培养更多的数据科学家和AI工程师:通过教育和培训,增加数据科学家和AI工程师的数量和素质,以推动中国的AI研究和应用。
- 加强国内外的数据合作:通过数据合作,借鉴国外的成功经验,改进数据的采集、处理、使用等方面的技术和方法,以提升中国数据的质量和价值。
数据是AI模型的"燃料",未来AI大模型的竞争,无疑将更加依赖高质量的数据。因此,对数据的投入和利用,将决定中国在全球AI竞赛中的地位和成绩。