




通常,软件工程师在处理系统设计任务时遇到困难的主要原因有三个:
- 系统设计任务往往没有固定的结构,工程师需要处理一个开放性的设计问题,这些问题并没有标准的解决方案。例如,在开发一个新的电商平台时,可能需要从零开始设计整个后台架构,而这个问题没有唯一正确的答案。
- 工程师在开发复杂和大规模系统方面的经验不足。例如,他们可能曾经在小型项目中充当过主要的开发者,但在处理一个全球分布式的大型数据系统时,他们可能会感到力不从心。
- 工程师没有花足够的时间来研究和准备如何解决系统设计的问题。例如,他们可能会对编码技术有深入的了解,但却没有投入足够的时间来学习和理解大规模系统设计的原则和模式。
在阿里、腾讯、百度和字节这样的知名公司,如果一个工程师在系统设计上的表现不超过平均水平,他可能会发现自己在项目中的影响力有限。相反,表现良好的工程师总会得到更多的机会和认可,因为他们展示出了处理复杂系统的能力。
在这个课程中,我们将通过实际例子,按步骤解决多个设计问题。首先,让我们来看看这些步骤:
步骤1:明确需求
我们在试图解决问题时,首先要做的是询问有关问题准确范围的问题。设计问题通常是开放性的,并且没有唯一正确的答案。这就是为什么在项目初期澄清模糊性至关重要。花足够时间定义系统终极目标的参与者,总是更有可能在项目中取得成功。此外,由于我们只有35-40分钟的时间来设计一个(可能)大型的系统,我们应该明确我们将关注系统的哪些部分。
让我们用设计一个类似微博的服务的实际例子来扩展这一点。在进行下一步之前,设计微博应该回答的一些问题包括:
- 我们的服务用户能够发布微博并关注其他人吗?
- 我们是否也需要设计创建和展示用户的时间线?
- 微博中是否会包含照片和视频?
- 我们是否只关注后端,还是也要开发前端?
- 用户能否搜索微博?
- 我们需要展示热门趋势话题吗?
- 是否会有新的(或重要的)微博的推送通知?
所有这些问题都将决定我们的最终设计会是什么样子。
步骤2:规模预估
对我们即将设计的系统规模进行预估总是一个好的做法。这将有助于我们后续关注系统的扩展性、数据分区、负载均衡以及缓存策略。
系统预期的规模是什么(例如,新的微博数量,微博的阅读数量,每秒生成时间线的次数等)? 我们需要多少存储空间?如果用户可以在他们的微博中上传照片和视频,我们的存储需求将有所不同。 我们预计将使用多少网络带宽?这将对我们如何管理流量、在服务器之间实现负载均衡至关重要。
步骤3:定义系统接口
需要明确系统所需的API。这将明确系统预期的具体协议,并确保我们对需求的理解没有出错。对于微博服务,API示例将会是:
postTweet(user_id, tweet_data, tweet_location, user_location, timestamp, …)
generateTimeline(user_id, current_time, user_location, …)
markTweetFavorite(user_id, tweet_id, timestamp, …)
步骤4:定义数据模型
在项目初期确定数据模型能够明确数据如何在各个系统组件之间流动。随后,它将成为数据分区和管理的指导。参与者需要确定各种系统实体,它们如何相互交互,以及数据管理的各个方面,例如存储、传输、加密等。对于微博系统的设计,以下是一些实体:
用户:UserID, Name, Email, DoB, CreationDate, LastLogin等。
微博:TweetID, Content, TweetLocation, NumberOfLikes, TimeStamp等。
用户关注:UserID1, UserID2。
喜欢的微博:UserID, TweetID, TimeStamp。
我们应该选择哪种数据库系统?我们是否应该选择类似Cassandra这样的NoSQL来满足我们的需求,或者我们应该使用像MySQL这样的解决方案?存储照片和视频应该使用哪种类型的块存储?
步骤5:高级设计
绘制一个包含5-6个表示我们系统核心组件的方框图。我们需要确定足够的组件,以便端到端地解决实际问题。
对于微博,从高层次来看,我们需要多个应用服务器来处理所有读写请求,同时在它们前面使用负载均衡器进行流量分配。如果我们预测读取流量(相比写入)会较大,我们可以决定使用单独的服务器来处理这些情况。在后端,我们需要一个能够存储所有微博并支持大量读取的高效数据库。我们还需要一个分布式文件存储系统来存储照片和视频。
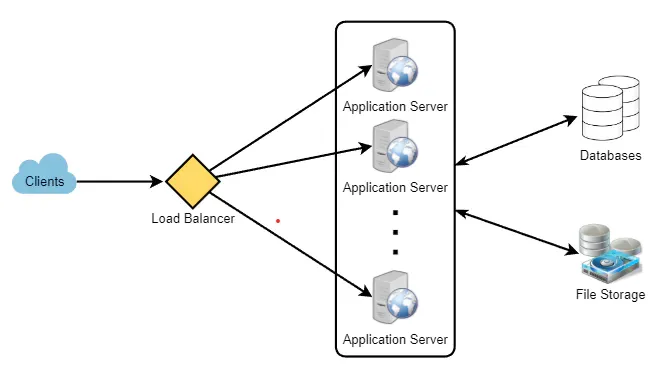
步骤6:详细设计
深入研究两到三个主要组件;团队成员的反馈应始终指导我们,系统的哪些部分需要进一步讨论。我们应该提出不同的方法,它们的优点和缺点,并解释我们为何会偏好一种方法而非另一种。记住,没有唯一的答案;最重要的是在保持系统约束的同时,权衡不同选项之间的利弊。
由于我们将存储大量的数据,我们应该如何对我们的数据进行分区,以将其分布到多个数据库?我们是否应该尝试将用户的所有数据存储在同一个数据库中?这会引起什么问题? 我们将如何处理那些频繁发微博或者关注很多人的活跃用户? 由于用户的时间线将包含最新的(和相关的)微博,我们是否应尝试以优化扫描最新微博的方式来存储我们的数据? 我们在哪个层次以及何时引入缓存以提速? 哪些组件需要更好的负载均衡?
步骤7:识别和解决瓶颈
尝试讨论尽可能多的瓶颈,以及缓解这些瓶颈的不同方法。
我们的系统中有没有任何单点故障?我们正在采取什么措施来减轻它? 我们是否拥有足够的数据副本,以便在失去一部分服务器的情况下,仍然能够为用户提供服务? 同样,我们是否有足够的不同服务的副本在运行,以便几个失败不会导致系统完全停机? 我们如何监控我们服务的性能?当关键组件失效或性能下降时,我们是否会得到警报?
总结
简而言之,在项目设计阶段的准备和组织是系统设计成功的关键。上述步骤应该指导你在设计系统时保持正确的方向,并覆盖所有不同的方面。