



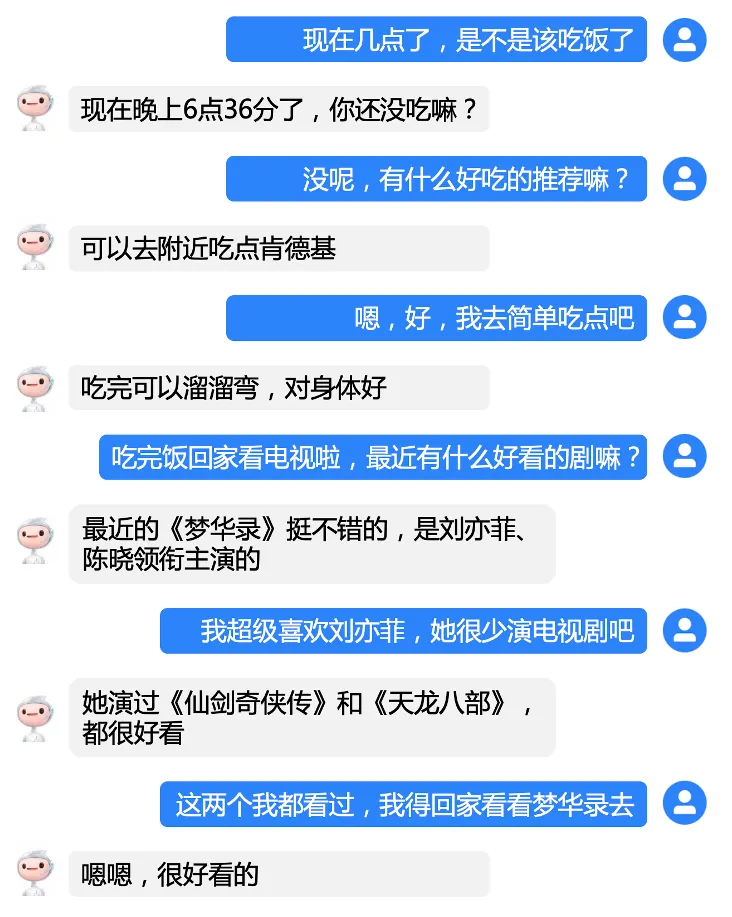
这是开放域闲聊系统?不会吧,它怎么可能真的懂这么多……
可这也不像是任务型对话,更不像是对话式问答系统啊……
这到底是什么?
百度近日发布了知识内化和外用全面增强的中文对话模型PLATO-K,极大提升了中文开放域对话效果。
PLATO-K全面知识增强对话模型
随着对话预训练技术的快速发展,对话模型在一些简单场景下可以产出很像人类的回复,在智能音箱、数字人、虚拟世界等产品上也逐渐有些探索性落地。然而,在对话模型朝着更大规模落地应用的路上,还存在很多挑战和阻碍,其中知识问题尤为突出。主要表现为两方面:
-
信息匮乏,对话模型倾向于生成普通的、缺乏信息量的回复,导致用户体验欠佳;
-
事实错误,对话模型经常混淆相似信息或胡编乱造事实,这会误导用户,甚至造成有害的后果。
其实,知识问题广泛的存在于预训练语言模型中,为了缓解这个问题,有两种策略被广泛使用。
-
通过扩大模型规模(比如PaLM)或者利用先验知识图谱信息(比如文心ERNIE)等方式,加强模型内部参数对知识的记忆;
-
从搜索引擎或数据库等外部资源中检索并利用相关知识(比如Atlas、WebGPT)。
虽然内部和外部知识生效方式不同,但是它们本质并不冲突,可以相互补充。
PLATO-K提出了同时结合知识内化和知识外用的全面知识增强策略:一方面,模型通过从大规模的网页文本和社交媒体对话语料,学习将大量的知识记忆到内部参数中;另一方面,模型进一步模仿人类对外部信息的查询和利用,学习在回复生成中融合外部知识。
PLATO-K两阶段的对话式学习
PLATO-K基于对话式学习机制,进行知识内化和知识外用的两阶段训练。(所谓对话式学习,是指从对话中学习,历史可以追溯至孔子论语或苏格拉底对话。PLATO-K设计以对话为中心,从始至终所有的训练样本都被组织成对话形式,进行学习。)
PLATO-K之所以采用对话式学习机制,原因主要有两方面:一方面,PLATO-K目标应用场景是对话,训练与推理保持一致的对话式机制是有益的;另一方面,近期一些教育研究表明,对话式学习机制在知识掌握上也有更卓越表现。
阶段1:知识内化
PLATO-K知识内化学习,包括了基于大规模对话语料的预训练和基于人工标注对话的微调训练。
预训练的样本是从社交媒体评论和网页文本转换的对话,作为人人对话的近似。下图中展示了两个对话样本。多角色对话来自社交媒体评论(包括微博、贴吧、知乎等),反映出了对话流的演变和发散。单角色对话来自网页文本(包括新闻、图书、百科等),包含了特定事物的深入观点或分析。通过在这些大规模对话样本上的预训练,PLATO-K 学习了基础的对话技能,并把大量的知识记忆到了参数中。

微调训练的样本是来自公开数据集的人工标注对话。由于社交媒体上会包含一些低质对话,比如歧视、有害言论等,导致预训练模型产生的回复有时与人类的价值观不太一致,吸引度不高。通过在高质量人人对话上的微调训练, PLATO-K进一步学习了高级的对话技能,并形成了更符合人类的价值偏好。
阶段2:知识外用
仅仅依赖模型参数内化的知识,在很多对话场景下还是不足的,举例如下:
-
由于参数规模有限,模型只能记住常见的重要知识,对于一些低频知识或具体细节,经常会记不清楚,发生混淆。
-
模型存储的静态知识,难以处理涉及动态信息的场景,比如时事新闻的讨论、天气预报的询问等等。
人类在碰到这些情况时,通常会参考相关资料、使用搜索引擎或相关工具服务,来辅助产生回复。受此启发,PLATO-K在第一阶段训练微调完成的基础上,更进一步基于人工标注对话,学习这种外部知识查询和利用的能力。
DuSinc知识外用数据集,记录了对话中的查询和基于知识的回复;Diamante闲聊对话数据集(机器辅助专家标注的开放域对话数据集,基于内化知识直接生成回复),也被融合到第二阶段训练中,以平衡模型对内化和外部知识的利用。
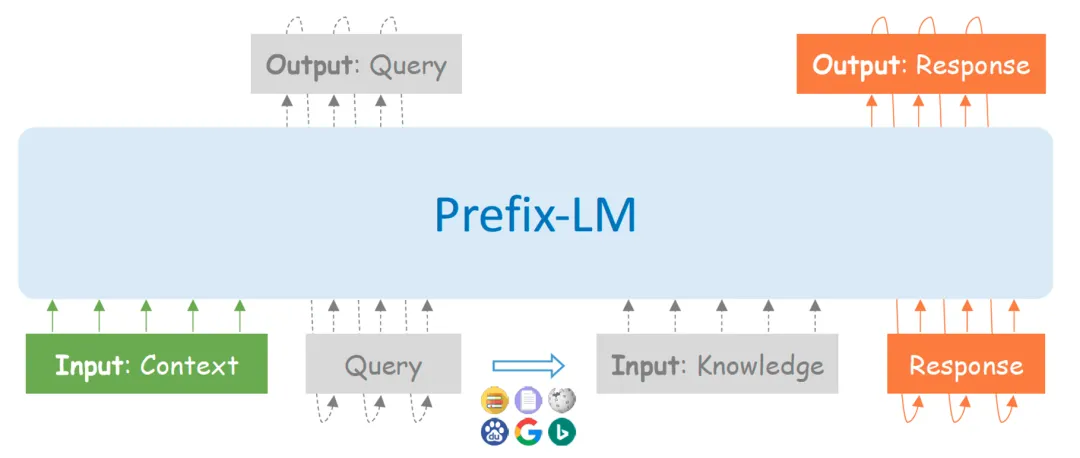
训练中PLATO-K学习:
-
给定对话上文Context,生成查询Query;
-
给定对话上文Context和返回的知识Knowledge,生成回复Response。
对于无需利用外部知识的对话轮次,相应的Query和Knowledge设为空。
PLATO-K对话效果评估
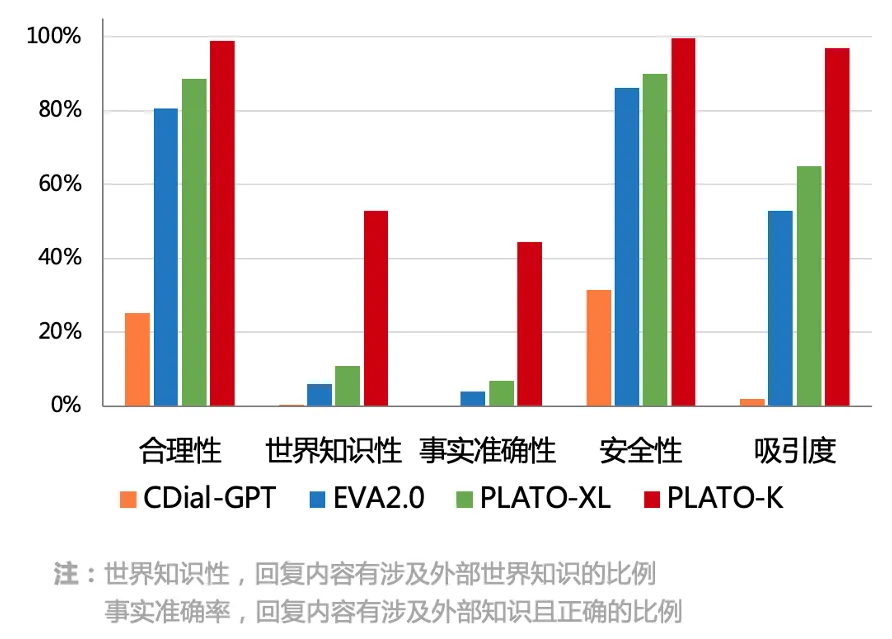
PLATO-K参数规模达到了220亿,是当前最大规模的中文对话模型。为了评估模型能力,PLATO-K与当前主流的中文对话模型进行了全面对比。
PLATO-K超越了所有基线模型,在知识相关指标(世界知识性&事实准确性)上,更是取得了突破性的进展。
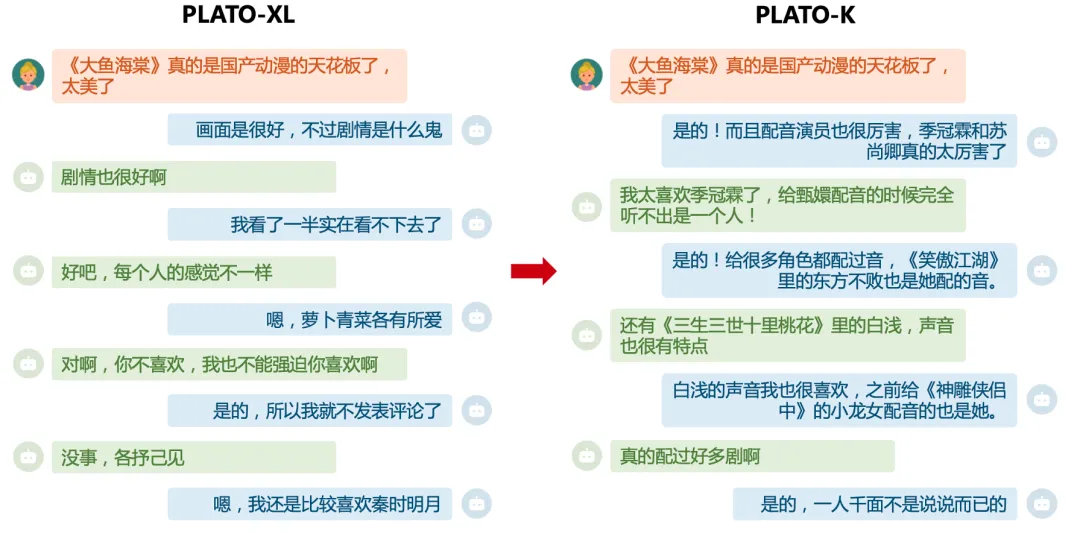
结语
人机对话逐渐成为新一代人工智能的重要交互方式,百度PLATO-K的发布,是开放域对话在大模型上的又一次深入探索。相信在不久的将来,更加强大的对话模型也会陆续发布。未来,对话模型会更加有用(Helpful)、真诚(Honest) & 和谐(Harmonious)。