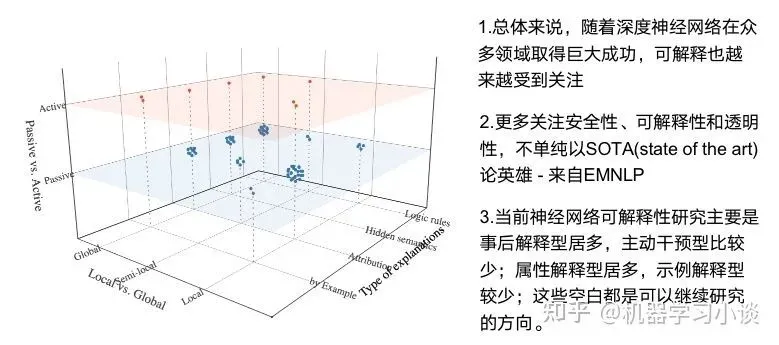
一、人工智能可解释性的背景意义
1.1 什么是可解释性
Interpretability (of a DNN) is the ability to provide explanations in understandable terms to a human. F Doshi-Velez & B Kim, 2017
- 解释(Explanations),是指需要用某种语言来描述和注解
理想情况下,严谨的数学符号-逻辑规则是最好的解释(D Pedreschi et al., 2019)。实际上人们往往不强求“完整的解释”,只需要关键信息和一些先验知识
- 可解释的边界(Explainable Boundary),是指可解释性能够提供解释的程度
来自XAI的:对于不同的听众,解释的深度也有所不同,应该是需求而定。例如:为什么你这么聪明?因为我喜欢吃鱼。为什么吃鱼会聪明?因为鱼类富含DHA。为什么DHA聪明?… 因为根据不同的人群,我们的可解释的工作也不一样。例如给大众解释吃鱼能够聪明就行了,因为吃鱼能够聪明我们很多人已经从小到大耳熟能详了。如果我们给专业人士解释DHA为什么会是大脑聪明,我们身边很多人也答不出来,这已经远超出我们计算机这个领域了。当然,可解释的这种边界越深,这个模型的能力也越强。
- 可理解的术语(Understandable Terms),是指构成解释的基本单元
不同领域的模型解释需要建立在不同的领域术语之上,不可能或者目前难以用数学逻辑符号来解释。例如计算机视觉中的image patches,NLP中的单词等。而可理解的术语可以理解为计算机跟我们人类能够沟通的语言。以前我们很多研究关于人类跟计算机表达的语言例如计算机指令,现在是反过来计算机根据现有的模型给我们解释
1.2 为什么需要可解释性
- 高可靠性的要求
a)神经网络在实践中经常有难以预测的错误(进一步的研究是对抗样本攻击与防御),这对于要求可靠性较高的系统很危险
b)可解释性有助于发现潜在的错误;也可以通过debug而改进模型
- 伦理/法规的要求
AI医疗:目前一般只作为辅助性的工具,是因为一个合格的医疗系统必须是透明的、可理解的、可解释的,可以获得医生和病人的信任。
司法决策:面对纷繁复杂的事实类型,除了法律条文,还需要融入社会常识、人文因素等。因此,AI在司法决策的事后,必须要给出法律依据和推理过程。
- 作为其他科学研究的工具
科学研究可以发现新知识,可解释性正是用以揭示背后原理。
二、神经网络可解释性的分类

2.1 按照逻辑规则解释(Rule as Explanation)
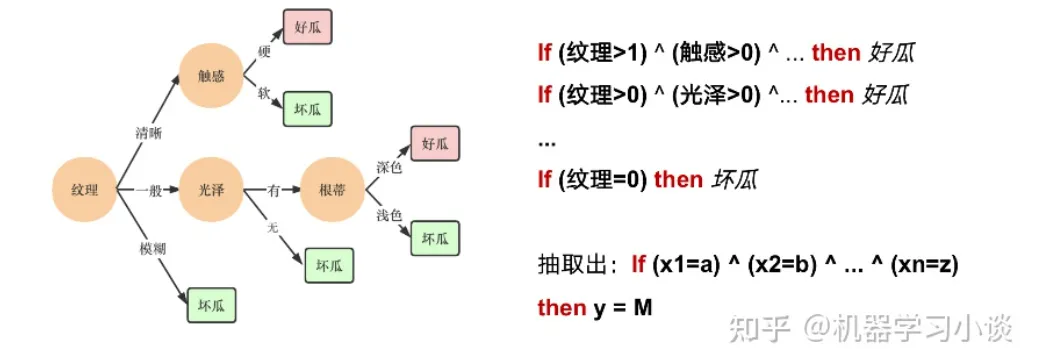
图左是一颗关于判断西瓜好坏的决策树,经过DFS后,我们可以抽取出右图的规则。而对于神经网络,我们是否也可以类似决策树这样做呢?
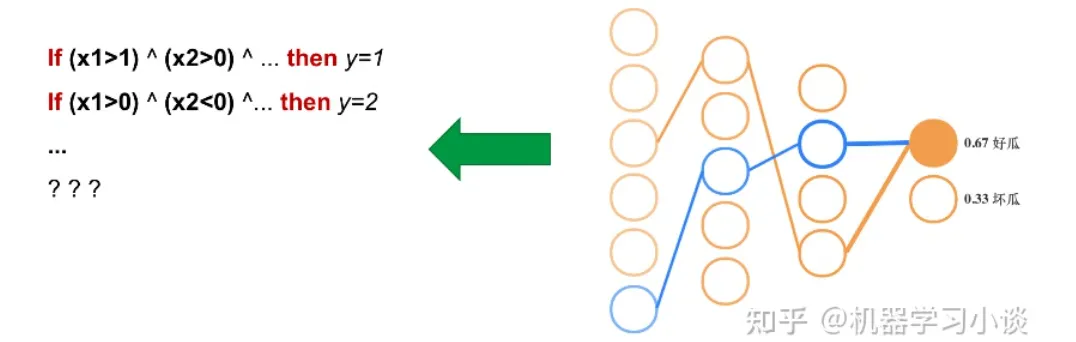
答案是肯定的。
第一种方法是分解法,遍历所有特征的排列组合
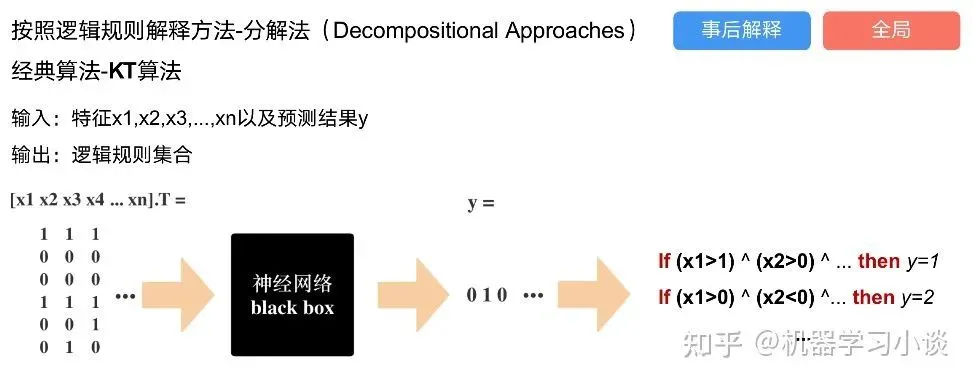
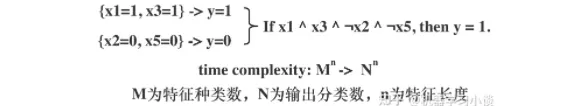
分解法最简单,但是缺点也是显而易见的,就是时间复杂度太高,虽然KT算法有所优化,但是指数形式的复杂度还是难以投入实际使用。于是我们引入第二种方法:教育法[1]
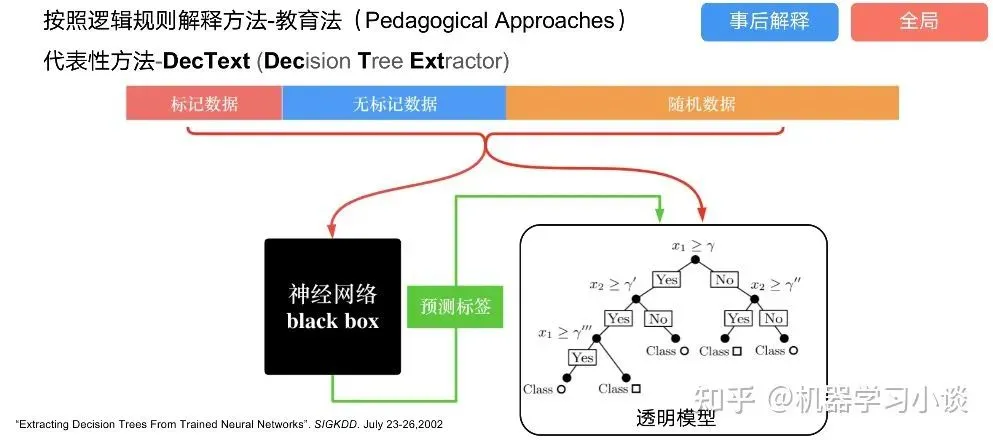
DecText-决策树抽取器,主要采用经过黑箱子的数据来抽取黑箱子的规则,并且与其他决策树不同的是,该方法除了使用标记数据还可以使用未标记数据以及随机数据,只要经过神经网络黑箱子都可以获得标签。对比仅用训练集,由于传统决策树进行生成叶子比生成其根的可信度还要低(因为能用于划分界限的数据越来越少)。所以DecText有一个优势就是可以利用更多的无标记数据甚至随机数据进行补充。但是一般论文也不会提及到自身设计的大多数缺点。例如,这里我认为有两大缺点。一、无标记数据或者随机数据其实有很多是超过解释的意义,例如人脸识别,如果我们倒入一些不及格的人脸甚至随机的图像,决策树也会对这些图像进行开枝散叶,降低了真正解释人脸的枝叶的占比。二、决策树不能表达太深的网络,决策树越深,性能会急剧下降,可解释性也越差。
Tree Regulartion[2]提出了树正则的方法,来抑制了树的深度。
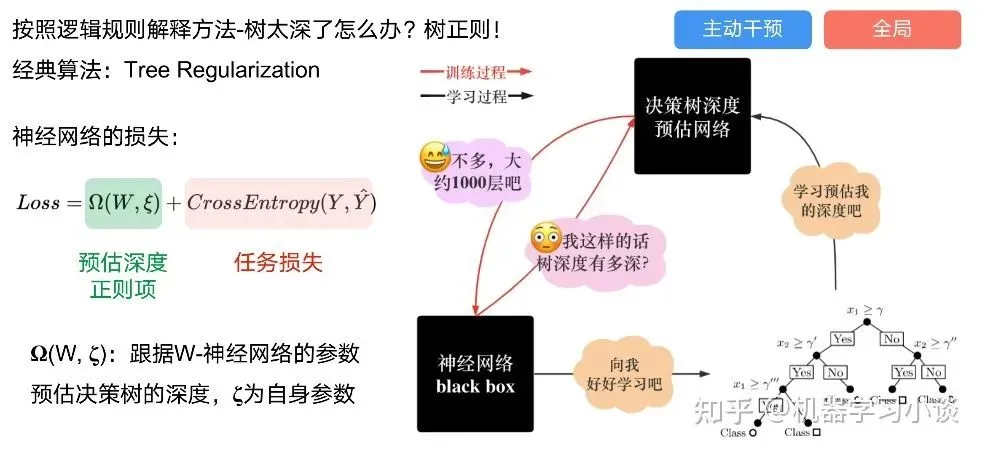
树正则通过引入深度损失正则项,在优化时候会抑制树的深度。而树的深度则是通过一个简单的预估网络进行预估,需要的参数就是主网络的参数。
2.2 按照语义进行解释
类比人类开始对细胞解释的时候,无法一下子直接从细胞本身理解这个细胞的类别或者功能,但是可以从细胞群或者组织(例如表皮细胞组织)来从宏观角度了解细胞的作用。神经网络亦是如此。例如卷积神经网络,浅层的卷积网络往往关注更基础的图像信息例如纹理、颜色等,而越往上层则越能抽象出更丰富的语义,例如人脸识别的眼睛、鼻子等。其中经典代表就是计算机视觉中的经典方法-可视化[3]
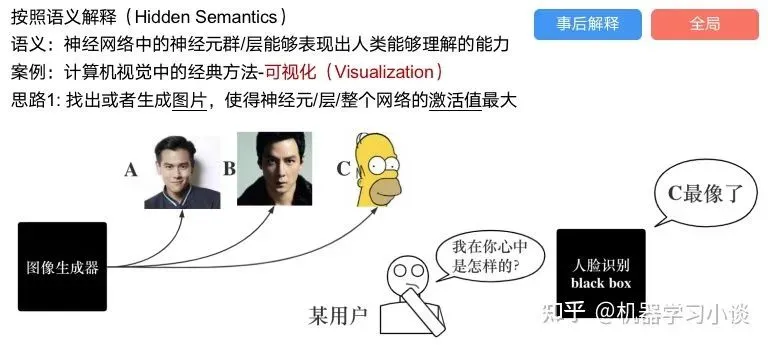

可视化的方法非常多,比如说有一个华人的博士就可视化了CNN,把每一层都展示得非常清楚,只需要在网页上点击对于的神经元,就可以看到工作流程。右边是一位维也纳的小哥,本来搞unity3D特效开发的,他把整个CNN网络用3d的形式可视化了出来。
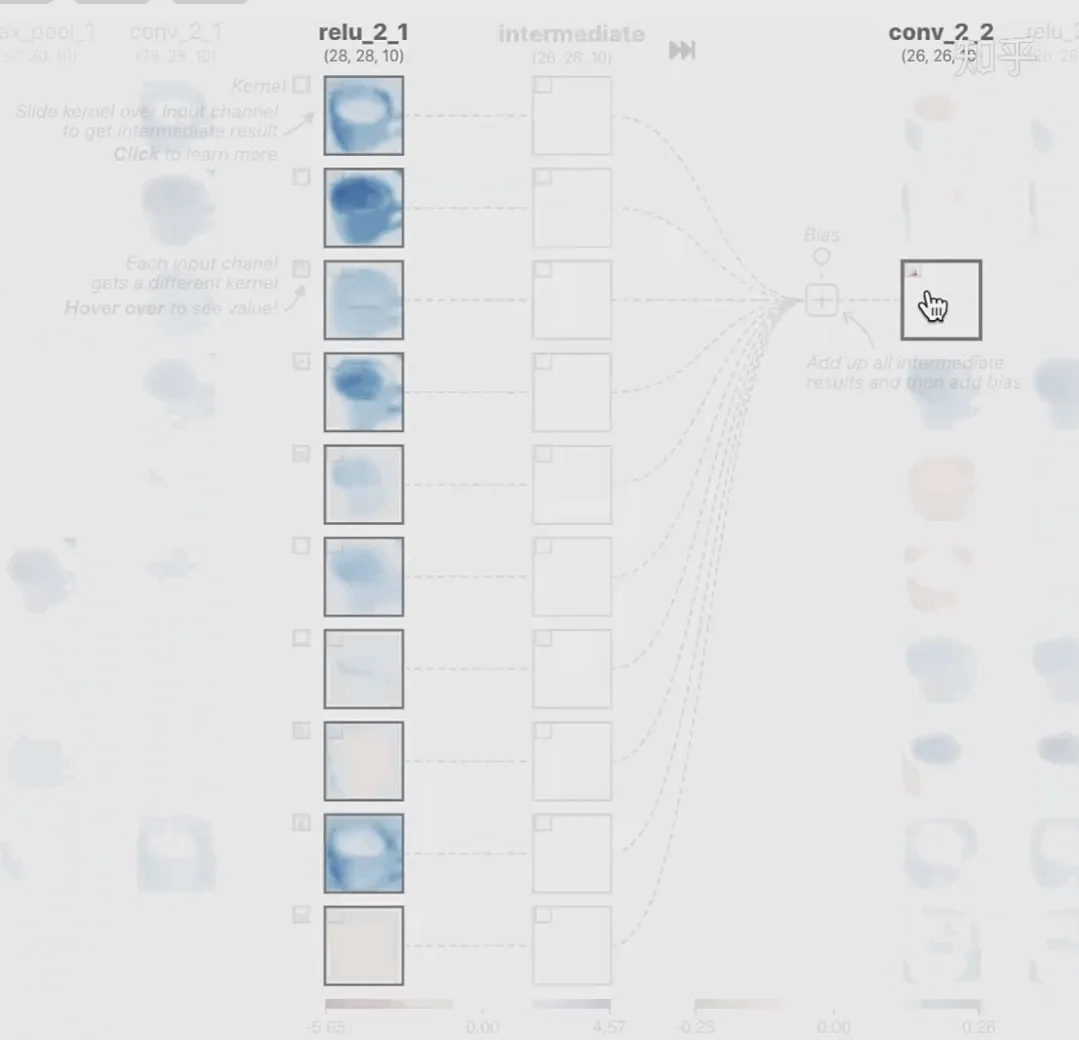
cnn_visual

featuremap_layout
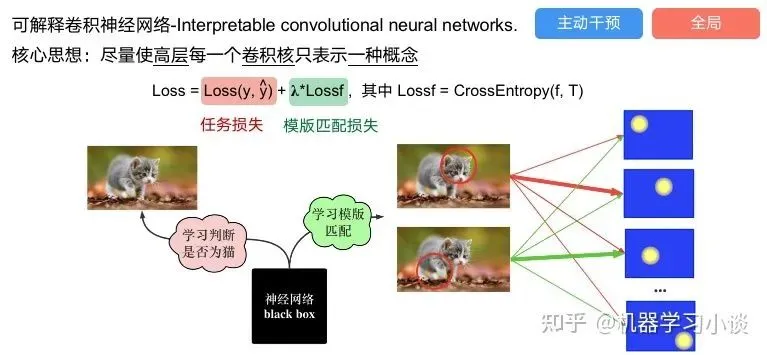
另外一种主动的按照语义进行解释的代表作:可解释卷积神经网络[4](Interpretable convolutional neural networks.)与传统的卷积神经网络不同的是,ICNN的每一个卷积核尽量只代表一种概念,例如,传统的卷积核对猫的头或者脚都有较大的激活值,而ICNN只能选择最大的一种。
2.3 通过示例解释
这种方法容易理解,是一种直观方法:寻找和待解释的样本最“相似”的一个训练样本,典型的代表作 Understanding black-box predictions via inflfluence functions,[5]

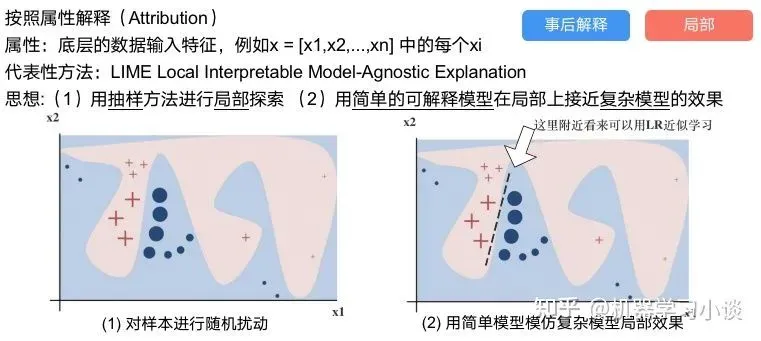
2.4 按照属性解释
按照属性解释目前内容上最。如前面提及到,决策树等透明模型难以模仿复杂的神经网络,那怎么解决呢?针对此问题研究的代表作有:Why should i trust you?: Explaining the predictions of any classififier[6]
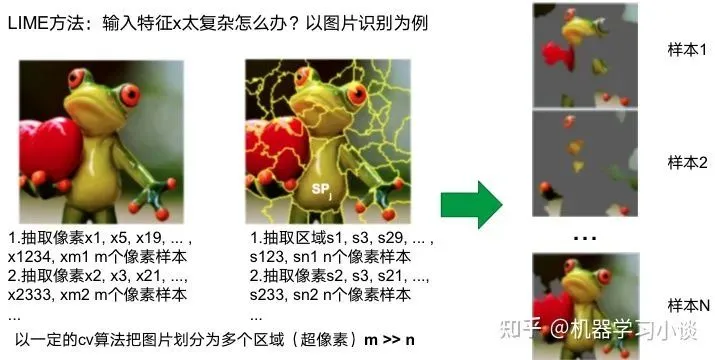
由于LIME不介入模型的内部,需要不断的扰动样本特征,这里所谓的样本特征就是指图片中一个一个的像素了。但如果LIME采样的特征空间太大的话,效率会非常低,而一张普通图片的像素少说也有上万个。若直接把每个像素视为一个特征,采样的空间过于庞大,严重影响效率;如果少采样一些,最终效果又会比较差。所以针对图像任务使用LIME时还需要一些特别的技巧,也就是考虑图像的空间相关和连续的特性。不考虑一些极小特例的情况下,图片中的物体一般都是由一个或几个连续的像素块构成,所谓像素块是指具有相似纹理、颜色、亮度等特征的相邻像素构成的有一定视觉意义的不规则像素块,我们称之为超像素。
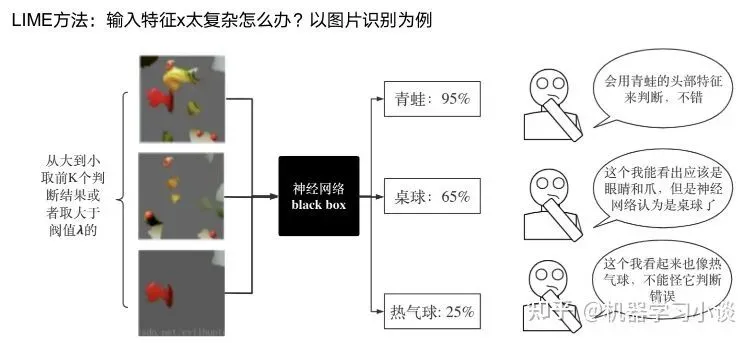
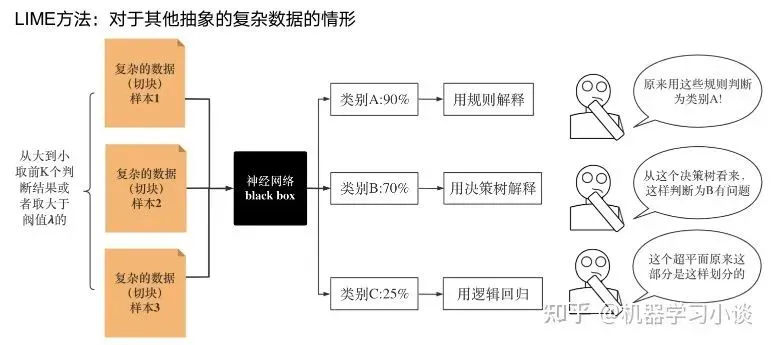
下面提供一些主动干预型的方法,如Dual-net[7]
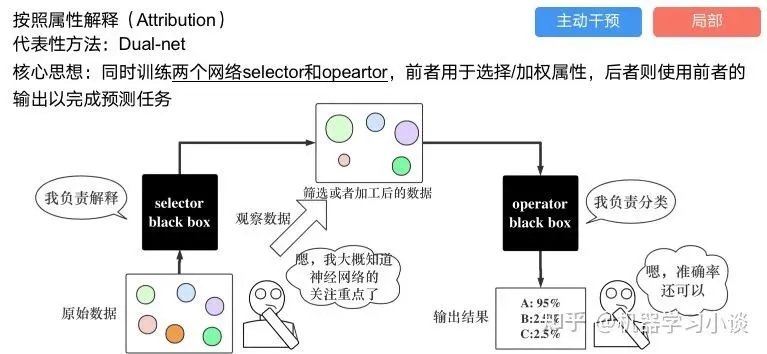
其他的还有:用意想空间的对话系统[8]
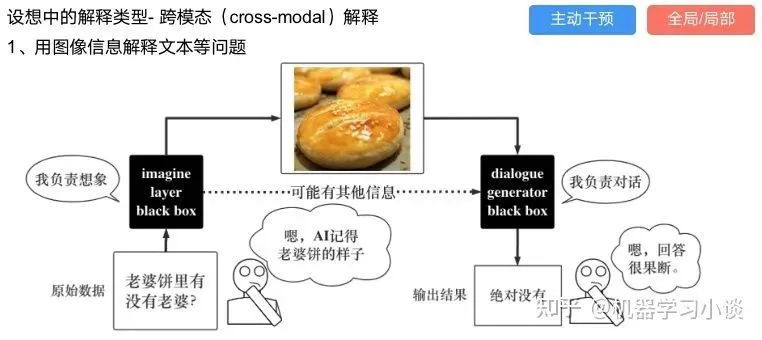
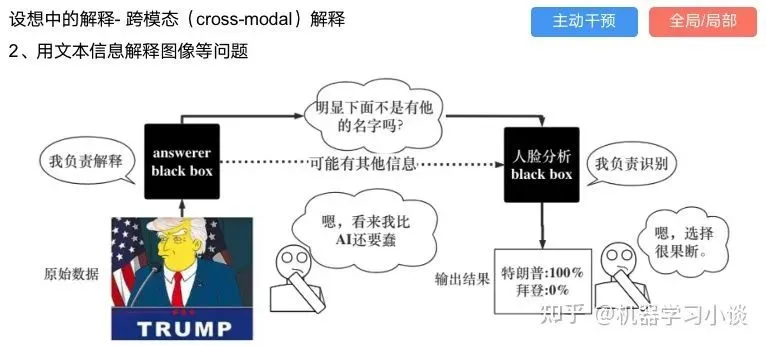
这种解释的类型是最有深度而且也是用户最容易理解的。但是对AI模型和训练难度也更高了。目前这方面的研究屈指可数。
三、可解释性总结