




引言
推荐系统本身很成熟,但是在落地过程当中,仍然会有很多困难。通过经历几个大型推荐系统项目,总结一些经验,帮助大家避坑。

01推荐系统的技术架构
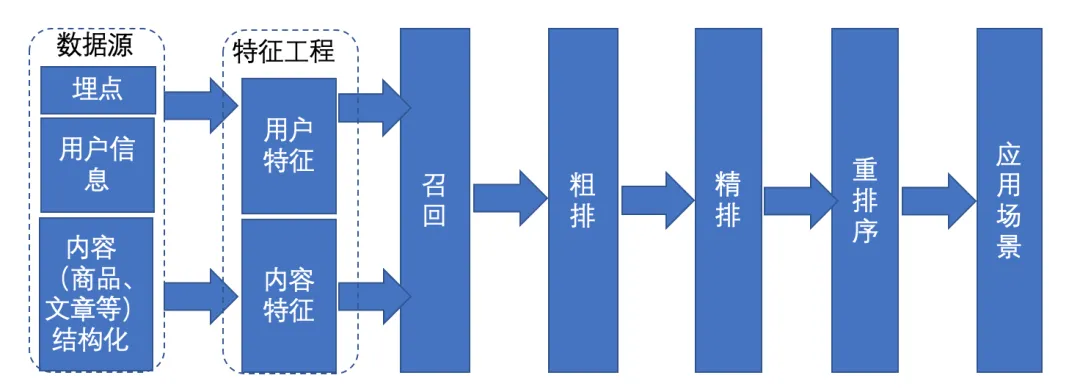
推荐系统模块一般如上图所示,先通过召回模块,将候选集召回,然后经过粗排、精排、重排等排序方式,将排序靠前的候选集推送给用户。
02 数据源
1. 埋点
💬 个人观点:
埋点不难,用埋点的数据构造样本比较难,特别是实时社交比如直播。
理想的样本:
- 用用户id把用户所有行为串起来;
- 可以回溯用户过去看直播间的行为,比如评论、打赏等。
实际上面临的困难:
- 埋点的数据不准确,是脏数据;
- 埋点数据排查困难:前端代码工程复杂,很容易出问题。但是前端的同学的主要工作也不是数据上报,所以数据出了问题,也不会实时排查,非常容易导致数据脏;
- 回溯模型也很复杂;
- 非常耗资源。
综上,将用户对应的行为,拼成样本,需要花费很多精力。
2. 用户画像
包括用户的基础画像和兴趣画像。兴趣画像来源于两个部分:用户的离线画像、用户的实时画像。其中,离线画像又分为长期离线画像、中期离线画像、短期离线画像。
3. 内容结构化
根据内容信息的不同,内容结构化方式不同,比如电商领域,内容为商品,商品的结构化信息包括分类、品牌、价格、规格等。
💬 个人观点:
多模态要是应用到推荐系统来,是个难点。
- 耗费资源:图片转化为向量,信息量太大,计算起来太耗资源。
- 现有的电商算法大多基于行为做描述,而多模态从内容上对商品做描述,怎么结合到一起,需要考虑。
所以目前多模态性价比不高,讨论较多,但是用的较少。
03 特征
特征工程,将结构化的信息转换成模型支持的数据格式。
特征选取的优劣,会最终影响到用户体验。所以特征工程及特征组合的自动化,一直是推动实用化推荐系统技术演进最主要的方向之一。
1. 特征内容
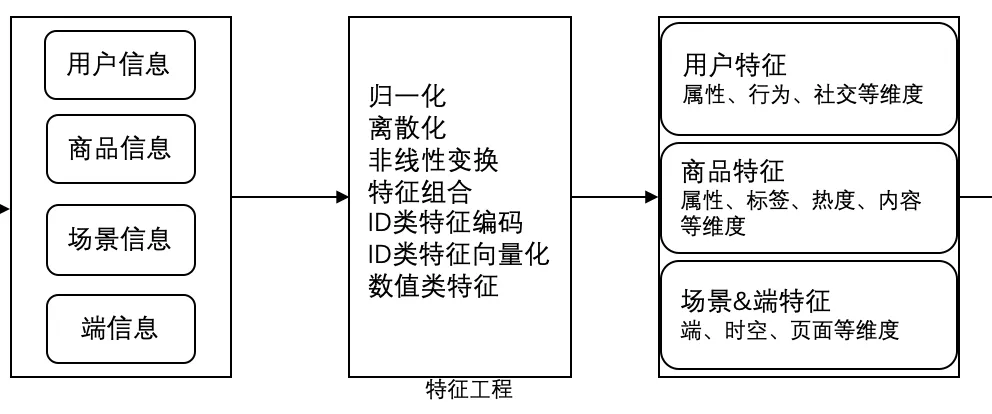
2. 特征生成
💬 个人观点:
(1)特征生成过程有什么难点?
- 样本拼接:在特征生成过程中,样本拼接也比较难。
- 一些脏数据的识别。如2.1埋点所说,埋点的数据很容易出问题,数据清洗和处理非常耗精力。
(2)有什么热门的特征提取方式?
用Embedding(可以理解为稠密向量)进行特征交叉。
(3)特征工程的趋势:
- 序列特征:用户历史的行为、浏览行为、点击行为,过去看的直播间、视频,前提就是比较基础的特征做好了
- 上下文特征
- Embedding
(4)用在召回的特征提取,和用在排序的特征提取,有什么不同?
① 特征有差别:
- 召回模型大多是双塔模型,用户、商品用双塔模型召回,没有交叉特征
- 精排需要交叉特征,比如用户和物品的交叉、属性的交叉等
② 样本有差异:
- 召回面向全量
- 精排面对的是召回后的候选集
③ 做召回的时候,要考虑精准性和效率,精排要用到所有考虑到的特征。所以召回特征是精排特征的子集。
(5)特征抽取:
- 特征需要结合业务场景去抽取特征,每个场景涉及的都不一样。要涉及到对推荐场景有一个很深的认知,才能抽到好的特征。因为每个场景输入的维度不同。
- 推荐涉及人货场三个方面的特征。有了基础特征之后,就做特征交叉,人货场中任意两三者去做交叉。
- 目前专家所在的大厂某业务,是一个大模型,所有的行业的输入都是同源的。专家认为这是不合理的,所以他认为趋势是,分行业去挖掘特征,每个行业做小的特征,而不是所有行业用一套特征。
04 召回
从全量信息集合中触发尽可能多的正确结果,并将结果返回给排序模块。
💬 个人观点:
数据决定模型的上限。召回决定了推荐的上限,因为精排的候选集是召回出来的。
1. 召回的要点
- 处理数据量大
- 速度要够快
- 模型不能太复杂
- 使用较少特征
2. 召回的难点
- 召回怎么样和后链路做一个耦合的学习。会有一种情况,排序很适合之前召回算法的商品,排序的非常好,换了召回算法,出一批新的商品,排序算法就不一定排的很好。
- 评估离线指标和线上指标的一致性:这是基础工作,因为离线评估指标涨了,线上不一定也涨了。指标主要看Hit rate。
注:Hit rate,在top-K推荐中,HR是一种常用的衡量召回率的指标.分母是所有的测试集合,分子是每个用户top-K推荐列表中属于测试集合的个数的总和。
举例:三个用户在测试集中的商品个数分别是10,12,8,模型得到的top-10推荐列表中,分别有6个,5个,4个在测试集中,那么此时HR的值是 (6+5+4)/(10+12+8) = 0.5。
3. 哪一种召回方式用的多?
- 召回的方式特别多,而且每种类型不一样,差异特别大,不同的召回方式数据集差异也比较大。
- 双塔用的最多,双塔包含很多种双塔模型,是成熟期了。
- 图神经网络不能用双塔模型。
- 一般有几十种召回算法同时在用,多路一起召回,包括双塔、ebadding、专家策略、知识图谱召回(用的少,其他厂用的多)、图上的传统召回、知识召回、表示召回、匹配召回几种都用。
- 专家策略效果也可以,只是可能没有那么多,而且每一步都有策略,不像双塔训练好就行。
4. 召回的趋势和新算法有哪些?
- 图神经网络召回;很有前景的值得探索的方向,信息在图中的传播性,所以对于推荐的冷启动以及数据稀疏场景应该特别有用。
- 知识图谱召回:知识图谱有一个独有的优势和价值,那就是对于推荐结果的可解释性。
- 因果推断。
5. 因果推断算不算召回的新算法?召回是怎么用因果推断的。
- 因果推断实现方式:在深度学习加一些embedding,对因果关系做一些建模。
- 因果推断是一个理念,在召回中容易给热门内容打高分,形成马太效应,因果推断的理念指排除掉因为马太效应出现,而是因为相关性被召回。这是一个比较大的领域,最近研究的人比较多,是一个热点。
- 在精排里试效果一般。
6. 在做召回时,主要考虑的因素和性能指标有哪些?
- 每一路召回算法,在后面精排曝光的占比。
- 快、相应速度快,能在全量物品库找用户喜欢的东西。
- 每一路召回算法的点击率也是看的。毕竟所有的优化都是为了线上提效,所以一般看线上的指标。点击率是最明显指标的指标。
- 有时候也看用户转化(是否电话联系)。
- 算法是否上线,也要结合线上的指标看。
05 排序
根据提前设定的目标,对信息进行打分,使评分高的信息优先展示给用户。排序环节是推荐系统最关键,也是最具有技术含量的部分,目前大多数推荐技术其实都聚焦在这块。
1. 排序算法
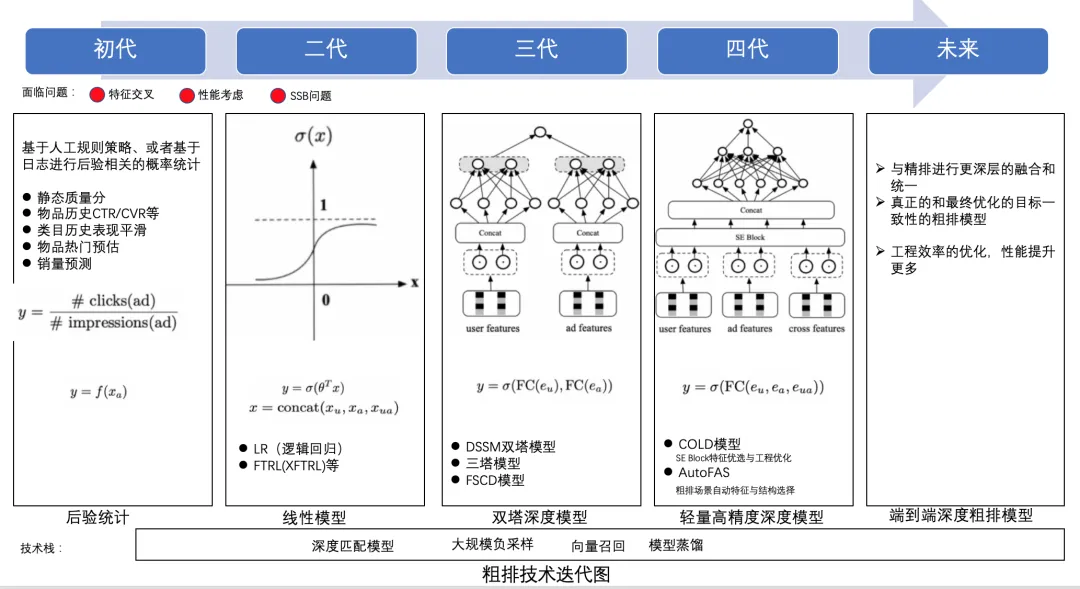
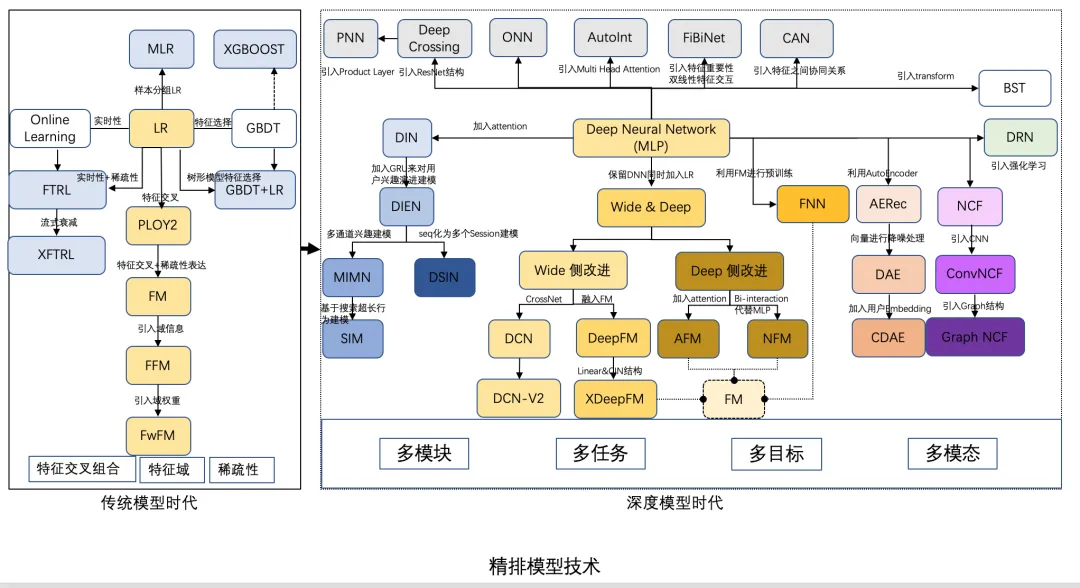
💬 个人观点:
(1)粗排
- 粗排输出的结果要给精排用,粗排的打分商品多,比如粗排打两万个,精排打top5k个,粗排打分空间更大。
- 粗排的样本选取和精排不能用同样的样本。粗排是所有商品,精排是在粗排的结果中选择样本。
- 粗排的要求是高效输出,一般也是双塔,因为要快,不能用太复杂的模型,都是基于一些简单的策略,截断topN,给到精排。
(2)精排
- 精排更集中于top商品,用有曝光的样本去训练。优中选优。
- 难点是在特征工程做的很好的情况下,设计模型结构,得到更好的结果。
- 大部分公司用的阿里巴巴提供的din,一个开源的算法包。
2. 多目标优化
多目标优化最关键的有两个问题。第一个问题是多个优化目标的模型结构问题;第二个问题是不同优化目标的重要性如何界定的问题。
如何设定不同目标权重,能够尽量减少相互之间的负面影响,就非常重要。这块貌似目前并没有特别简单实用的方案,很多实际做法做起来还是根据经验拍一些权重参数上线AB测试,费时费力。
而如何用模型自动寻找最优权重参数组合就是一个非常有价值的方向,目前最常用的方式是采用帕累托最优的方案来进行权重组合寻优。
💬 个人观点:
(1)精排的多目标优化用的比较多,比如总的目标是成交gmv,就会分成点击率和转化率两个目标。
(2)多目标训练的好处:
- 点击率和转化率如果分开训练,打分就会有延时,消耗的计算资源也会更大。
- 还有一个好处,多个目标可以相互借鉴,特别是数据量稀疏的情况下。
(3)至于多目标优化,也有一些自动化的方式调权重,但是一般是人工拍。拍很多组权重,不同组权重的模型,在同一份测试集上出效果。
(4)多目标优化一般用PLE(Progressive Layered Extraction),腾讯CGC出的模型,一直没有被超越。新出的目标关系之间的建模,db-mtl,esmm等,都不如PLE。
(5)经典的还有Mmoe。
3. 多模态融合
在对专家的访谈中,发现业界对多模态的定义有两种:
- 推荐的内容同时有多种形式,比如文字、图片、视频等。
- 推荐的内容同时有多种业务线,比如新房、二手房、租房等。
💬 个人观点:
多模态,比较让人头疼。
比如首页推荐,内容包括帖子、视频,排序的时候怎么排,很难用统一的模型,因为帖子、视频分属于不同的业务线,很多特征在这条业务线上有,其他业务线上没有。所以没有好的统一的召回模型和统一的精排模型,只能偏人工策略。
某大厂采用的方法是,先算首页有多少个坑位,基于流量价值和用户喜欢哪条业务线,人工给权重,分给每个业务线多少个坑位,再将业务线中的商品按照推荐算出来的排序填充坑位。
4. 重排序
根据用户最终的使用体验及运营需求,进行排序结果的重新排序。
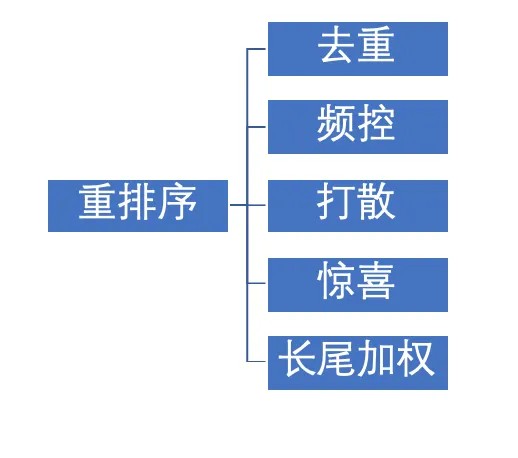
💬 个人观点:
(1)难点
① 如何保证用户满意度最高的同时,也保证创造者能够得到流量。
- 对创造者进行新手扶持,冷启动阶段会给高一些的权重。
- 但是更加考虑用户的满意度。所以如果创造者内容质量低,也有可能不给流量。
② 用户产品和商业产品的平衡:
- 有商业的产品,要保证收入。所以用户产品排完序之后,要把商业产品排到前面去。
- 具体商业产品的排序,要多种权重,不断权衡,尝试商业产品排序掉一点,商业价值不掉。
- 如果商业价值不变,但是整个模型数据提高,就可以上线。
06 其他步骤和需要注意的
1. 推荐系统的冷启动
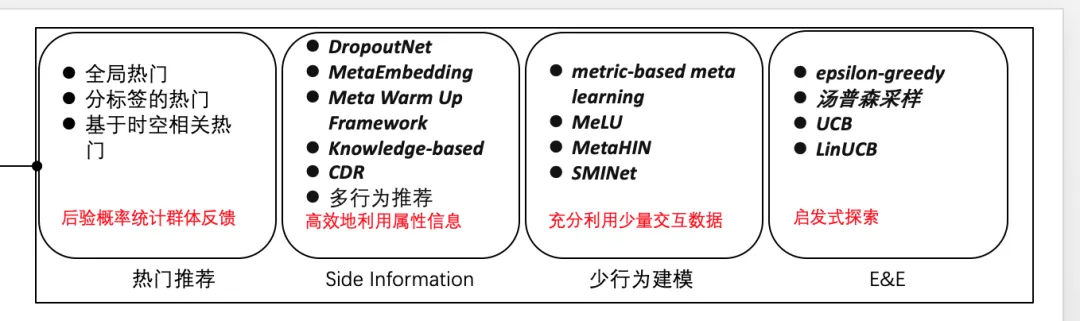
💬 个人观点:
冷启动的解决办法太多了。
① 类协同过滤的,找和新用户基础属性相似,又行为丰富的人,推荐这样的人喜欢的商品给新用户。
② 通过ml的方法,因为冷启动行为少,先利用之前的数据,训练好一个模型,直接赋给冷启动的用户,这样用少量数据,模型也可以快速收敛。
③ 通过业务的规则去做。什么场景下,给用户推荐什么内容。
④ 图神经网络。对物品冷启动有很好效果。
⑤ 用户的冷启动,可以收集跨域信息,比如去其他业务线包括二手房、商业地产收集用户信息。
⑥ 还可以通过提示是否喜欢一些标签,来获取用户数据。
⑦ 冷启动的基本原则是老物品给新用户,新物品给老用户。
- 老物品给新用户,指基于流行度,选择热门商品,给新用户,做新用户兴趣的探索。
- 老用户给新物品,老用户已经有行为,新物品与老用户行为过的已有物品有关系,就推给老用户,度过新物品的冷启动周期。
2. 推荐系统的评估指标
💬 个人观点:
离线评估指标:不同环节,不同指标。
- 召回和粗排中,使用hitrate。
- 精排中:是auc,NDCG。
业务场景中:
① 推荐系统评估使用工具:ab测试平台。
② 使用指标:CTR、CVR、人均使用时长、信息相关性等;
③ 也会关注留电率,但是这种线下数据太稀疏了,所以还是主要看CTR、CVR。
④ 平台在不同阶段关注的不同:
- 平台在前期追求点击率;
- 相对长的时间段,关注用户观看时长;
- 更长期:关注用户的留存率。
07 推荐系统的应用
💬 个人观点:
推荐系统在不同的界面(比如首页、购买成功页、商品详情页)等,推荐系统的算法逻辑差异比较大。
- 在商品列表页的推荐,主要是根据历史行为推荐;
- 在商品详情页的推荐,主要是根据当前商品推荐。
08 个人对整体推荐系统的观点
1. 推荐系统在业务上的难点
不同的公司目标不一样,选用什么样的数据模型来完成公司的战略意图。比如公司现在想要用户的真实互动和分享,推荐系统应该把分享多的内容推荐给用户,但是这样会导致诱导分享的内容更容易被推荐。
如何判断优质内容,从而更好地把优质内容推荐给用户,是推荐系统在业务上的难点。
2. 精准性和惊喜性的平衡
推荐系统的精准性现在很容易做,基于上述全链路的算法,再配合好的特征,那么能得到一些好的商品。但是会面临问题:推荐商品很单一。比如点了很多连衣裙相关的,会不断推连衣裙。推荐系统具有滞后性,只会推用户已经行为过这些东西。虽然用户可能也会点击,但是这样对于一个推荐系统,是不够优秀的。
如果用户有多种兴趣:连衣裙、小吃等,会有打散策略,给她推多种兴趣的商品,这样问题还小一点。
如果用户兴趣单一,推荐系统就会只推她喜欢的那个兴趣,就是推荐系统不够好。
好的推荐系统,要为用户提供惊喜性、发现性,要推荐用户恰好想要的。精准性和发现性需要兼顾,做一个平衡。
3. 没有数据是最难的。不断会有新的场景出来,新场景的数据不足。
4. 推荐系统给新的内容生产者的流量:没有看到一些很好的保量的算法。现在用的多的是pid,比例微分积分。投放速度快,就限制一些,投放速度慢,就减慢一些。
5. 推荐对业务的价值:怎么让推荐对整个业务起到作用,让整体业务增长。
6. 推荐所需的环境和条件:数据、abtest、线上工程,都能具有非常好的鲁棒性。