




上一篇文章我们介绍了推荐系统:基于内容的过滤,可以根据产品元数据计算的,提供制定推荐的选择,推荐与用户过往购买过的产品相关性最相似的产品,今天我们来聊聊如何通过利用用户和产品之间的相似性提供建议的方法。
协同过滤是一种利用用户和产品之间的相似性提供建议的方法。协同过滤分析相似的用户或相似评级的产品,并根据此分析推荐用户。
协同过滤分为3个小标题:
- 基于Item的协同过滤
- 基于用户的协同过滤
- 基于模型的协同过滤
基于Item的协同过滤
这种方法是一种分析产品相似度或用户对产品的评价,并根据分析结果提出建议的方法。
下表显示了 m 个用户对 n 部电影的评分。我们想向看过并喜欢《斯普利特》的用户推荐一部与《斯普利特》收视率相似的电影。

在这种情况下,可以为该用户推荐 Film 4,这是一部与 Split 具有相似取向(同时喜欢和不喜欢)的电影。
示例:
一家在线电影平台想要开发一个基于协同过滤的推荐系统,以满足其用户群体的需求和意见。当用户喜欢一部电影时,该系统将基于相似的喜好模式,向用户推荐其他类似的电影。这样做旨在提供更符合用户口味的推荐服务。
关于数据集:
电影:
- movieId:电影的id
- title:电影的标题
评分:
- userId:用户的id
- movieId:电影的id
- score:用户对电影的评分
- time:评分的时间戳
您可以在此处找到数据集。对于这个项目,我们将在“电影”上合并“电影”和“评分”数据集。
在项目开始时,数据集被读取并合并。您可以查看项目的完整代码。
创建用户电影数据框:
在这一步中,我们将创建用户电影数据框,但我们不希望其中存在稀疏性。例如,假设用户只对一部电影进行了评分。即使对 1 部电影进行了评分,该用户也会在 User-Movie 数据框中的所有其他电影中各占一个单元格。这会延迟要进行的计算并导致性能问题。为了避免这些计算问题并防止极少数用户观看的电影被包括在推荐中,应该做一些缩减过程。
缩减过程完成后,将创建一个数据透视表,行中包含“userId”,列中包含“title”,交集中包含“rating”。
在 User-Movie 数据框中,如果用户没有对电影进行评分,则其交集处的单元格由 NaN 表示。
基于item的电影预测:
由于已创建用户电影矩阵,因此可以通过查看电影之间的相关性来找到电影与其他电影之间的相似性。
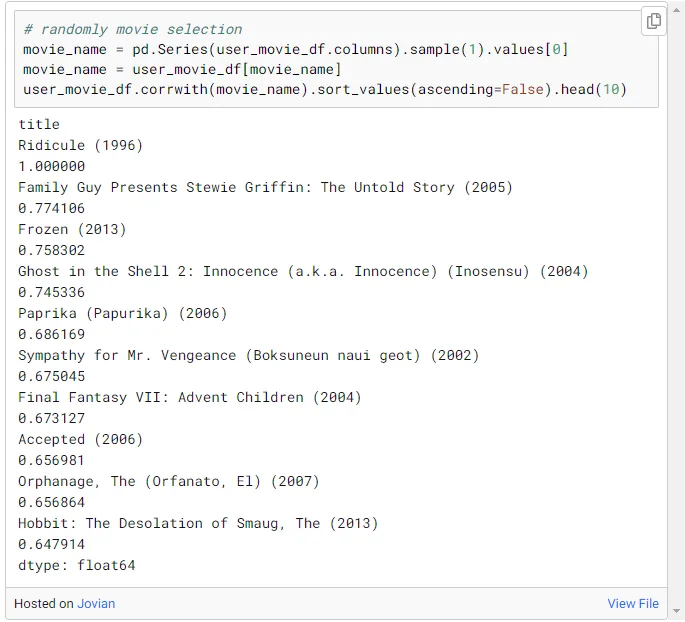
随机选择电影后,计算这部电影与其他电影的相关性。可以推荐具有高相关性的电影,这意味着已经推荐了表现出与这部电影相似行为的电影。
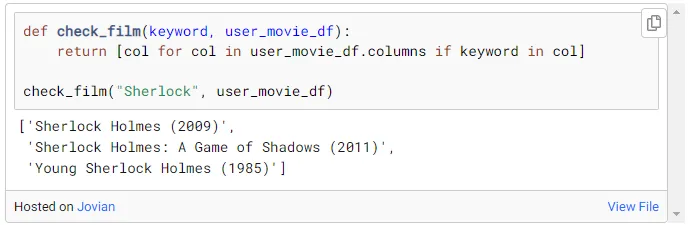
也可以手动选择和检查电影。您可以使用下面的代码片段按关键字进行搜索,以获取数据集中电影的全名。
基于用户的协同过滤
协同过滤是一种分析用户的行为(喜好-今日头条早期的推荐系统)并根据表现出相似行为的用户的喜好提供建议的方法。
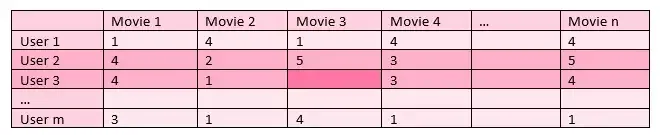
该表显示了 m 个用户对 n 部电影的评分。用户未观看的电影的评分留空。需要推荐与用户3相似并且他可能喜欢的电影。为此,首先应该找到表现出相似行为的用户。可见,在用户3评价的电影中表现出相似行为的用户为用户2,则选择用户2喜欢但用户3没有看过的电影3进行推荐。作为这个建议的结果,预计用户 3 会喜欢这部电影。
示例:
在这个项目中,将使用基于item的协同过滤中使用的相同数据集。将对在基于项目的项目中创建的用户电影数据框执行操作。这是项目的完整代码,用于检查数据集的过程并创建数据框。
确定推荐用户观看的电影:
用户是随机选择的。在这个选择之后,应该为这个用户减少使用电影数据框。这样就可以确定该用户看过的电影。
通过len(movies_watched),发现random_user观看了33部电影。
访问观看同一部电影的其他用户:
在这一步,我们首先需要找出其他用户与随机用户共同观看了多少部电影。
在这一点上,我们需要一个限制,因为只用 random_user 看过 1 或 2 部普通电影的用户不会成为推荐过程的标准。
识别与要建议的用户具有最相似行为的用户
这将分 3 个步骤完成:
第 1 步:聚合 random_user 和其他用户的数据
第 2 步:创建关联数据框
第 3 步:找到最相似的用户(顶级用户)
在前一阶段找到的值是所有用户的相关值。目的是覆盖与 random_user 具有高相关性的用户。因此,选择相关性高于 0.65 的用户。
计算加权平均推荐分数:
如果按照等级排序,就会忽略相关性的影响,如果按照相关性排序,就会忽略等级的影响。为了防止这种情况并同时看到两者的影响,将通过将这两个值相乘得到一个名为“weighted_rating”的新变量,并根据该变量进行排序。
以这种方式,可以向用户做出像上面那样的推荐,同时考虑到相关性和评级。
基于模型的协同过滤(矩阵分解)
在基于模型的协同过滤中,更全面地解决了这个问题。假设有一个问题需要优化。
目标是预测并填充 m 个用户和 n 部电影矩阵中标记为 BLANK 的单元格。
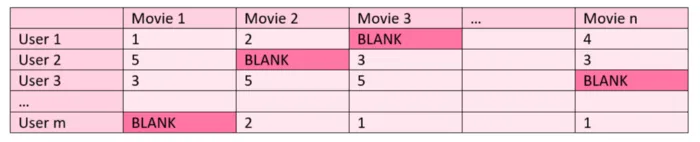
为了填补空白,假设用户和电影存在的“潜在特征”的权重是在现有数据上找到的,并用这些权重对不存在的观察结果进行预测。
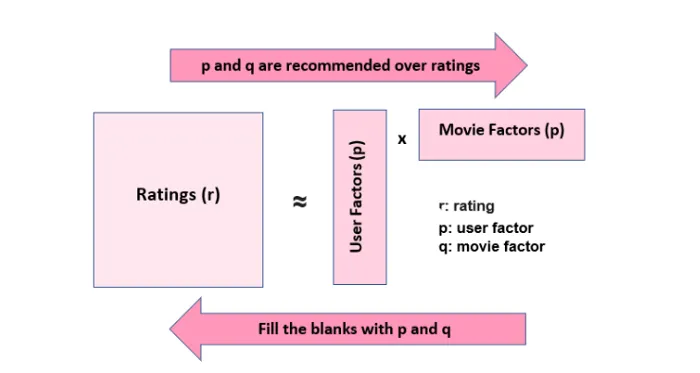
User-Movie 矩阵被分解为 2 个维数更少的矩阵。假设从 2 矩阵到 User-Movie 矩阵的转换发生在潜在因素下。潜在因素的权重在填充的观察结果中找到,空的观察结果用找到的权重填充。
为了更清楚地理解这个过程,通过一个例子会很有用。

我们有一个像上面那样的用户电影矩阵,我们想在这里估计空值。首先,我们将其分为 2 个维数较低的矩阵,分别是用户因子和电影因子。
在这一点上,潜在因素对填充观察的权重应该如下所示:
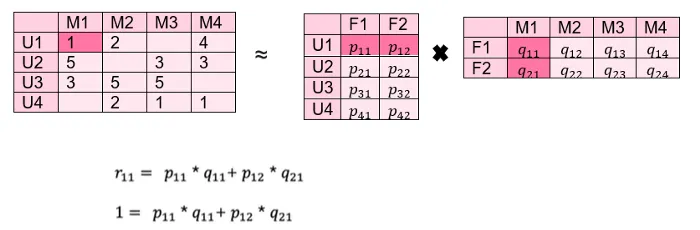
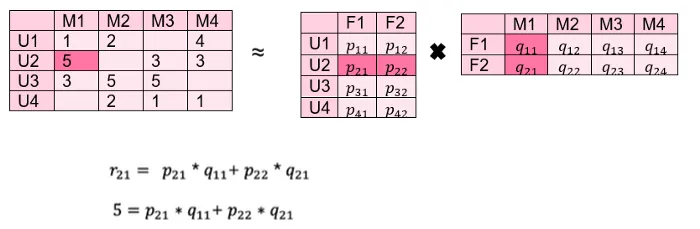
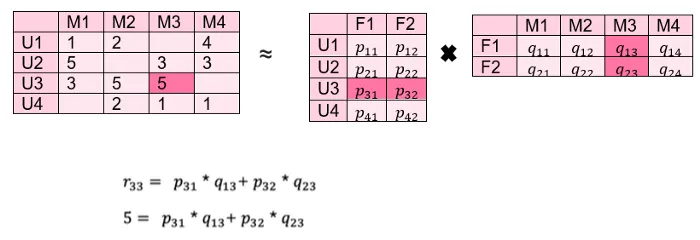
所有 p 和 q 值都是在现有值上迭代找到的,然后使用。最初,它尝试预测随机 p 和 q 值以及评分矩阵中的值。在每次迭代中,都会安排错误的估计,并尝试接近评级矩阵中的值。因此,作为特定迭代的结果,p 和 q 矩阵被填充。
要了解预测是好是坏,需要一个通用的衡量标准。为此,将所有估计值与实际值之间的差异的平方相加,然后求平方根,然后求平均值(RMSE 和 MSE 值)。这为我们提供了有关所有数据的信息。通过这种方式,我们可以获得有关我们在研究开始时根据分配给用户和电影矩阵的值所做的预测的平均误差的信息。更新 p 和 q 值以最小化此错误。
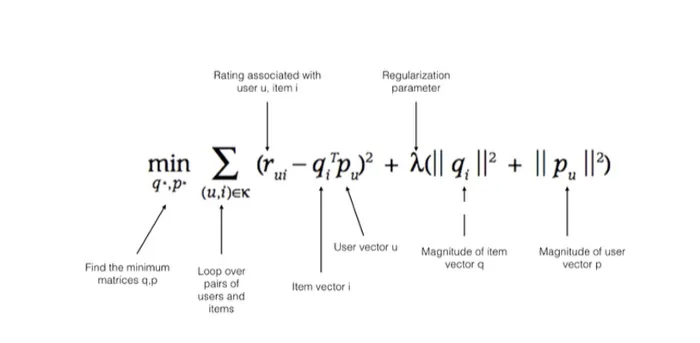
矩阵分解的梯度下降:
找到 p 和 q 权重的一种方法是使用梯度下降法。梯度下降是一种用于函数最小化的优化方法。
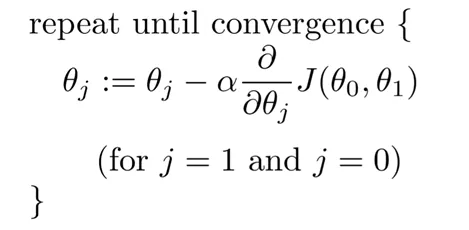
参数值在“最速下降”(定义为梯度的负值)的方向上迭代更新,并找到将给出相关函数最小值的参数。
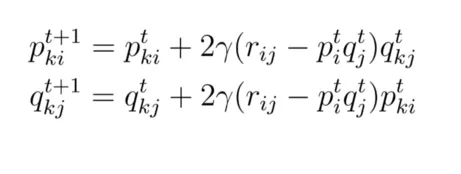
这里,p 和 q 矩阵中的权重根据导数交换。函数在一点的导数给出了该函数增加的最大方向。当迭代地沿着定义为梯度的负方向,即与增加方向相反时,更新参数值以最小化相关函数。
示例:
在这个协同过滤的最终项目中,将使用在基于项目和基于用户的协同过滤中使用的相同数据集。这是检查数据集过程的项目的完整代码。
资料准备:
在可追溯性方面,我会根据这 4 部电影及其 id 来缩减数据集,并从缩减后的数据集中创建用户电影数据框。
由于本项目要用到surprise库,并且有其特殊的数据结构,movie_user_df需要转换成这种特殊的结构。
建模:
对于建模步骤,首先应将数据分为训练集和测试集,比例为 75% 和 25%。然后应该创建 SVD 的模型对象,并用训练集执行拟合操作。接下来,应该在测试集上测试模型。
RMSE 度量可能更适合评估预测的平均误差。
userId为1.0,movieId为541的watch单元的实际评分值如下。
当我们用我们为同一个观察单元建立的模型进行预测时,我们得到了 4.33 的评分:
模型调整:
在这一步中,会进行模型的优化,也就是我们会尝试增加模型的预测性能。这将通过超参数优化来实现。
考虑到理论部分讨论的公式,超参数是 epoch、潜在因子、学习率和 λ。对于超参数优化,我们将定义 epoch 和学习率的参数集如下。然后,通过使用 GridSearchCV 尝试这些可能的参数集,计算纪元和学习率组合的平均误差,这将给出可能的最低平均误差。
最终模型和预测:
模型的默认值和我们用 GridSearchCV 找到的最佳参数彼此不同。因此,必须使用这些最佳参数重新创建 SVD 模型对象。
到目前为止,我们已经将数据划分为训练集和测试集,检查错误并优化超参数。如果模型建立在更大的数据之上,则可以进行更好的学习。因此,模型将建立在所有数据之上。
建模步骤中userId-movieId对的预测过程:
在建模步骤中,userId 为 1.0 和 movieId 为 541 的预测值为 4.33。经过超参数优化后,可以看到新的预测是 4.23。超参数优化后,预测过程已执行到更接近实际值 (4.00),即误差已减少。
由此产生的优化模型提供了对所需的user-movie对进行预测的可能性。做出相关预测后,就可以对电影进行筛选了。向这些用户推荐对某些用户具有预测高收视率的电影。