




上一篇文章我们介绍了推荐系统:ARL(关联规则学习),可以通过关联规则挖掘算法Apriori来实现关联规则推荐系统,今天我们来聊聊如何通过基于内容的过滤来实现推荐系统。
基于内容的过滤是用作推荐系统的另一种常用方法之一。内容的相似性是根据产品元数据计算的,它提供了制定推荐的选择,推荐与用户过往购买过的产品相关性最相似的产品。
元数据代表产品/服务的特性。例如,一部电影的导演、演员、编剧;作者、封底文章、书籍的译者或产品的类别信息。(别问我为什么用国外的数据)

此图像包含用户喜欢的电影的描述。根据用户喜欢的电影向用户推荐电影,需要使用这些描述得到一个数学形式,即文本应该是可测量的,然后通过与其他电影进行比较来找到相似的描述。
我们有各种电影和关于这些电影的数据。为了能够比较这些电影数据,需要对数据进行矢量化。在向量化这些描述时,必须创建所有电影描述(假设 n)和所有电影(假设 m)中的唯一词矩阵。列中有所有唯一的单词,行中有所有电影,每个单词在交叉点的电影中使用了多少。这样,文本就可以被矢量化。
基于内容的过滤步骤:
- 以数学方式表示文本(文本矢量化):
- 计数向量
- 特遣队-IDF
2.计算相似度
1.文本向量化
文本矢量化是基于文本处理、文本挖掘和自然语言处理的最重要的步骤。诸如将文本转换为向量并计算它们的相似度距离等方法构成了分析数据的基础。如果文本可以用向量表示,那么就可以进行数学运算。
将文本表示为向量的两种常见方法是计数向量和 TF-IDF。
- 计数向量:
-
第 1 步:所有唯一术语都放在列中,所有文档都放在行中。

-
第 2 步:将文档中术语的频率放置在交叉点的单元格中

- TF-IDF:
TF-IDF 对文本和整个语料库(即我们关注的数据)中的单词频率执行归一化过程。换句话说,它对我们将创建的词向量进行了一般标准化,同时考虑了文档术语矩阵、整个语料库、所有文档以及术语的频率。这样就消除了一些由于Count Vector产生的偏差。
-
第 1 步:计算 Count Vectorizer(每个文档中每个单词的频率)

-
第 2 步:计算 TF(词频)
(相关文档中术语 t 的频率)/(文档中的术语总数)

-
第 3 步:计算 IDF(逆向文档频率)
1 + loge((文档数 + 1) / (包含术语 t 的文档数 + 1))
样本检查文件总数:4

如果一个词t在整个语料库中出现频率很高,说明这个相关词影响了整个语料库。在这种情况下,对术语和整个语料库中的通过频率进行归一化。
-
第 4 步:计算 TF * IDF

-
第 5 步:L2 归一化
求行的平方和的平方根,并将相应的单元格除以找到的值。
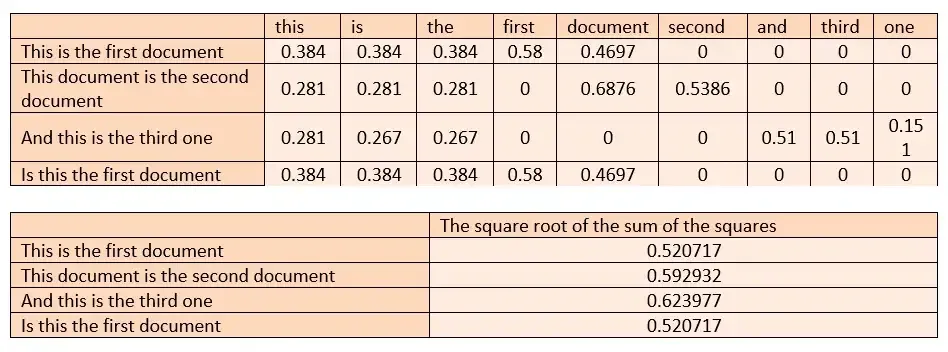
L2 规范化再次纠正某些行中存在缺失值而无法显示其效果的单词。
2.计算相似度
假设我们有 m 部电影,在这些电影的描述中有 n 个独特的词。在我们以编程方式找到这些电影基于内容的相似性之前,让我们看看我们如何实际地做到这一点:
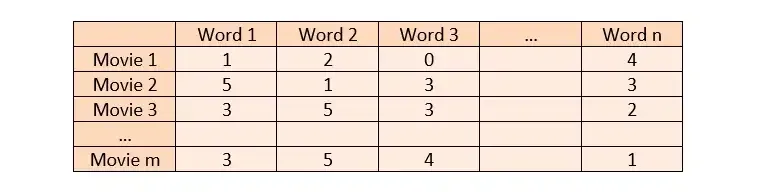
我们可以使用欧几里得距离或余弦相似度来找到向量化电影的相似度。
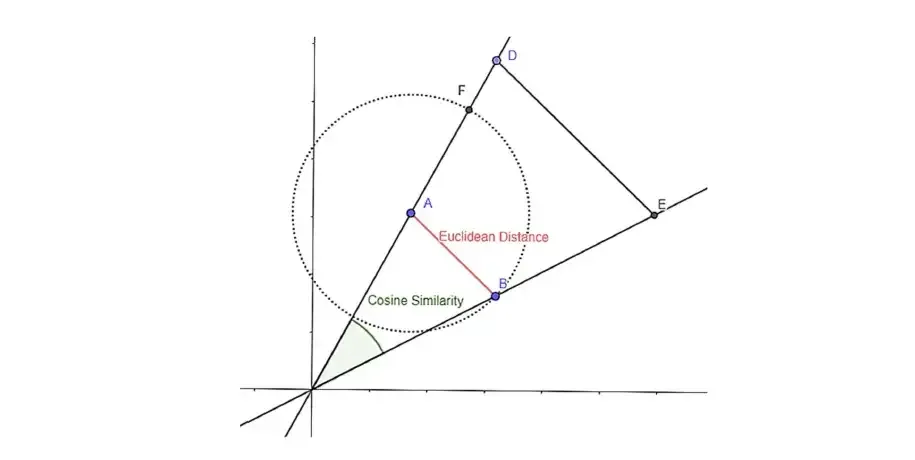
- 欧氏距离:
通过计算欧几里德距离,可以得到两部电影之间的距离值,它表示电影之间的相似性。可以看出,随着距离的减小,相似度增加。这样,就可以进行推荐过程了。
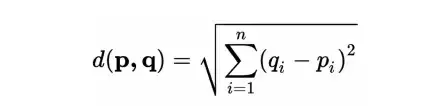
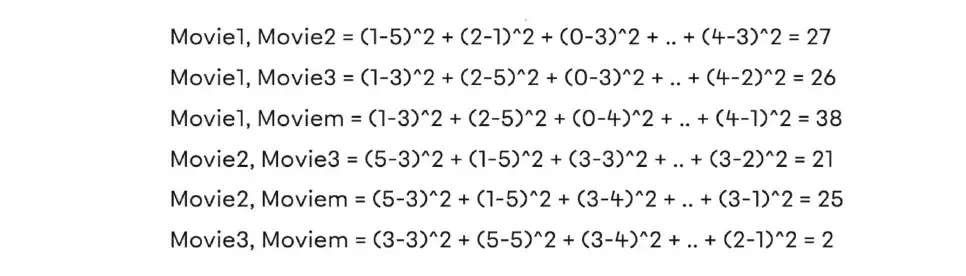
- 余弦相似度:
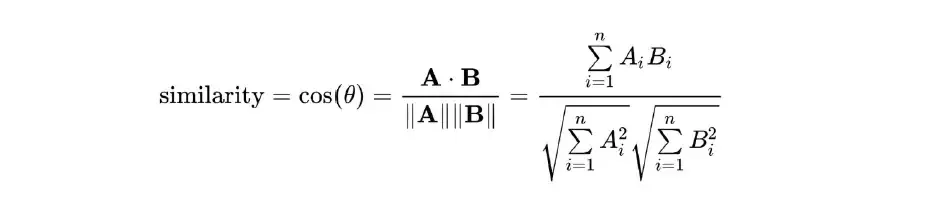
欧几里得中有距离的概念,而余弦相似性中有相似性的概念。距离接近性和相似性不同性对应于这里的相同概念。
现在我们已经介绍了基于内容的过滤的逻辑,我们可以深入了解一下基于内容的过滤推荐。
问题:
一个新成立的在线电影平台想要向其用户推荐电影。由于用户的登录率很低,用户的习惯是未知的。但是,可以从浏览器中的痕迹访问有关用户观看了哪些电影的信息。根据这些信息,希望向用户推荐电影。
关于数据集:
主要电影元数据文件。包含有关 Full MovieLens 数据集中的 45,000 部电影的信息。功能包括海报、背景、预算、收入、发行日期、语言、制作国家和公司。
创建 TF-ID 矩阵:
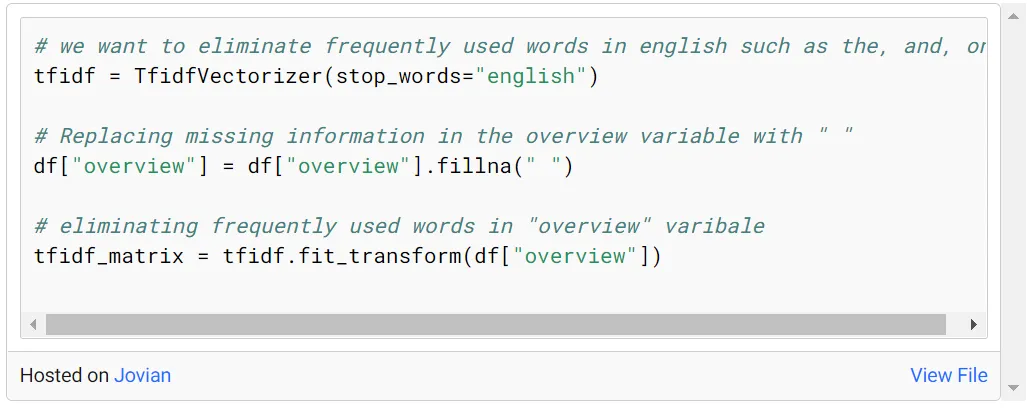
在项目开始时导入了必要的库,并读取了数据集。
这里要应用的第一个过程是使用 TF-IDF 方法。为此,调用了在项目开始时导入的 TfidfVectorizer 方法。输入stop_words='english’参数,删除语言中常用的不带测量值的词(and, the, at, on等)。这样做的原因是为了避免在要创建的 TF-IDF 矩阵中稀疏值会导致的问题。
tfidf_matrix 的形状为 (45466, 75827),其中 45466 表示概览数,75827 表示独特词数。为了能够在处理这种大小的数据时取得更好的进展,我会将 tfidf_matrix 交集处的值类型转换为 float32 并进行相应处理。
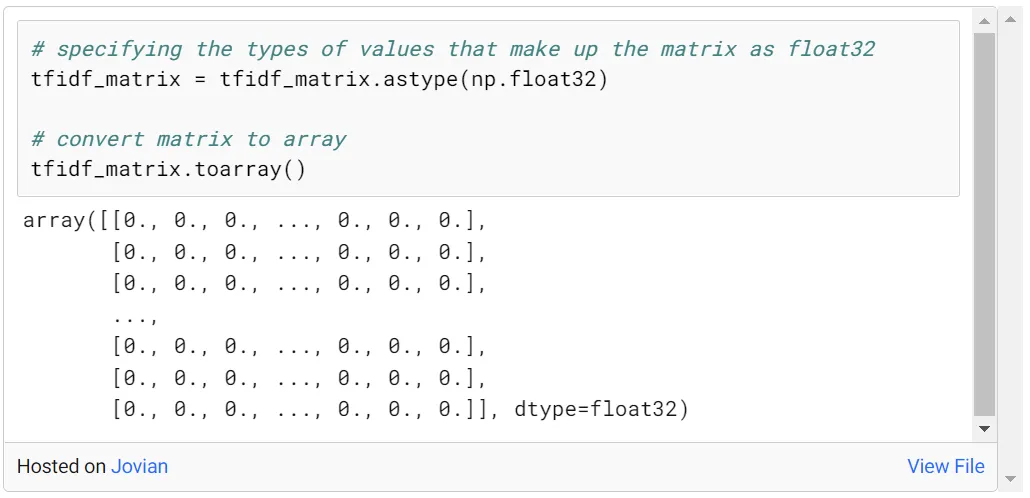
现在我们在 tfidf_matrix 的交集处有了分数,我们现在可以构建余弦相似度矩阵并观察电影之间的相似度。
创建余弦相似度矩阵:
使用项目开始时导入的cosine_similarity方法,求每部电影与其他电影的相似度值。

例如,我们可以找到第一个索引中的电影与所有其他电影的相似度得分如下:
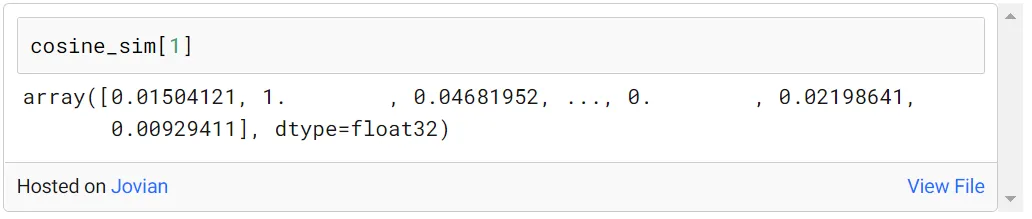
根据相似性提出建议:
相似度是用余弦相似度计算的,但需要电影的名称来评估这些分数。为此,一个 pandas 系列包含哪部电影在哪个索引中被创建为indices = pd.Series(df.index, index=df[‘title’]).
如下所示,在一些电影中观察到多路复用。
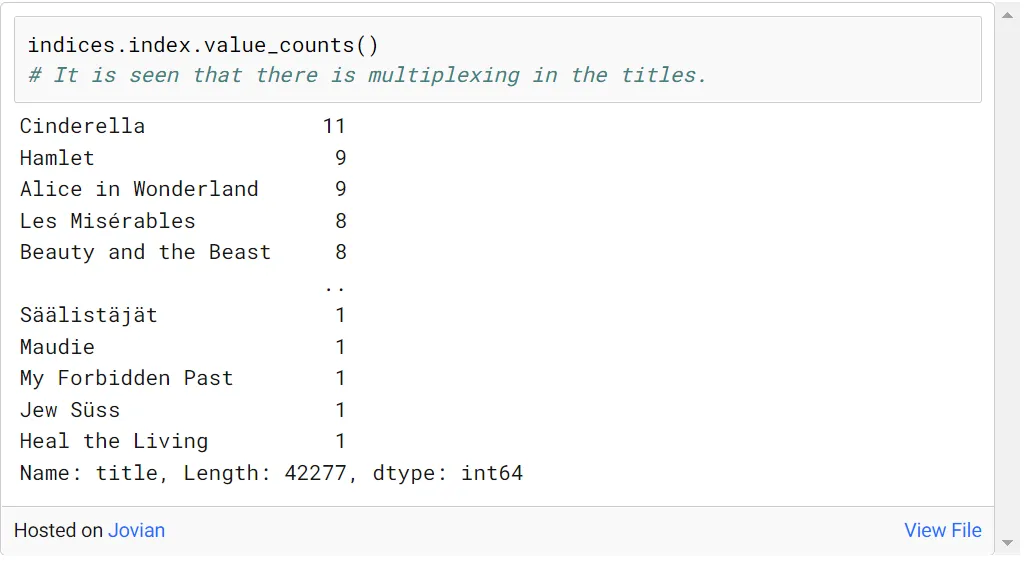
我们需要保留这些倍数中的一个并消除其余的,在最近的日期取这些倍数中最近的一个。这可以通过以下方式完成:

作为操作的结果,可以观察到每个标题都变成单数并且可以通过单个索引信息访问。
假设我们想要查找 10 部类似于夏洛克·福尔摩斯的电影。首先,通过在cosine_sim中输入福尔摩斯的索引信息来选择福尔摩斯电影,并访问表示这部电影与其他电影之间相似关系的分数。
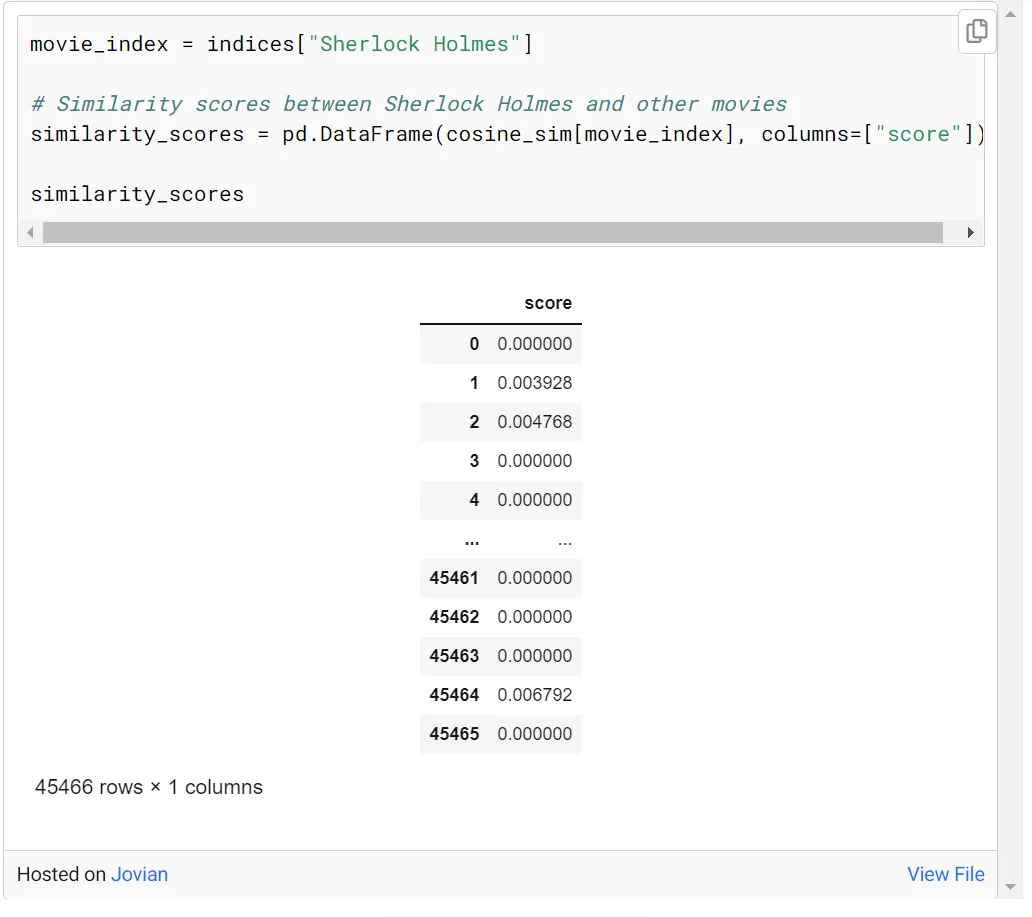
名为 similarity_scores 的数据框被创建为更具可读性的格式。与 cosine_sim[movie_index] 的选定相似性保存为该数据框中的“分数”变量。
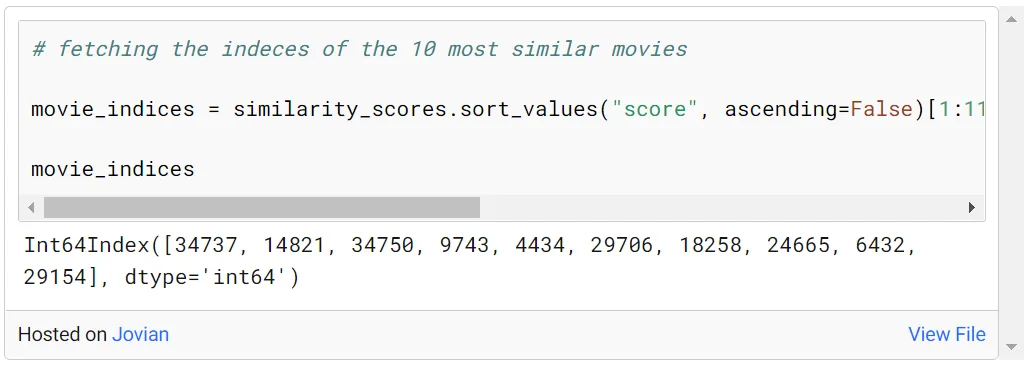
上面选择了与夏洛克电影最相似的 10 部电影的索引。这些索引对应的电影名称可以通过如下方式访问:

这10部电影在描述上与福尔摩斯最相似。这些电影可以推荐给看过福尔摩斯-夏洛克的用户。也可以尝试不同的电影,并观察推荐结果。