





上一篇文章我们介绍了推荐算法如何影响我们的生活,今天我们来聊聊如何实现一个简单的推荐系统—关联规则学习。
一家公司的产品内容一般都是非常丰富的,但用户的兴趣往往会针对整个内容集进行筛选,挑选出用户感兴趣的产品,筛选的规则因人而异。为了让用户不迷失在丰富的产品集群中,并根据兴趣领域达到所需的个性化服务,一般都会制作各种过滤器。这些过滤器和算法显示就是我们的“推荐系统”。
市场上流行的推荐系统可以归纳在这 4 个主要实现方式上:
- 简单推荐系统:利用业务知识或简单的排序技术进行一般性推荐。
- 关联规则学习:根据关联分析学习到的规则提出推荐内容。
- 基于内容的过滤:根据产品的相似性提出推荐内容。
- 协同过滤:根据共同的兴趣对用户或产品进行推荐。它分为基于用户,基于产品和基于模型(深度学习)的3种方式。
本文是推荐系统实现的第一部分,重点将放在简单推荐系统和关联规则学习上。敬请关注基于内容的过滤和协同过滤方法。
简单推荐系统
简单推荐系统不关心用户行为或产品特性。这些系统一般会关注喜欢的、流行的、销量高的、得分最高的产品等,并直接向用户推荐这些产品。比如淘宝或京东的销量最高的,评分最高的等。
关联规则学习
它是一种基于规则的机器学习技术,用于查找数据中的模式。在进行关联规则学习时使用先验算法。Apriori 是一种关联规则挖掘算法,也是最经典的算法,用于揭示产品关联。Apriori 中有 3 个重要指标:
- 支持:测量一起购买产品 X 和 Y 的频率
Support(X, Y) = Freq(X, Y) / Total Transaction
- 置信度:购买产品X时购买产品Y的概率
Confidence(X, Y) = Freq(X, Y) / Freq(X)
- Lift:购买产品X时购买产品Y的概率增加系数。
Lift = Support(X, Y) / (Support(X) * Support(Y))
Apriori 是如何工作的?
Apriori算法根据过程开始时确定的支持度阈值计算可能的产品对,并根据每次迭代确定的支持度值进行淘汰,从而创建最终候选项。
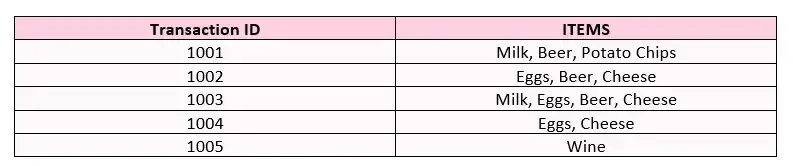
- 第一步:计算每个产品的支持值。
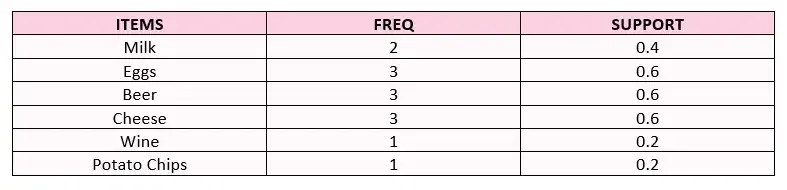
- 第 2 步:剔除支持值等于或低于流程开始时确定的支持阈值的产品。

- 第 3 步:识别可能的产品对并计算支持值。
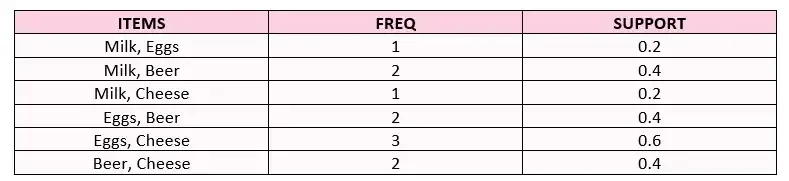
- 第4步:根据确定的支持度阈值进行剔除。

- 第 5 步:确定新的可能产品对并计算支持值。

- 第6步:根据确定的支持度阈值进行剔除。

- 第7步:决赛桌
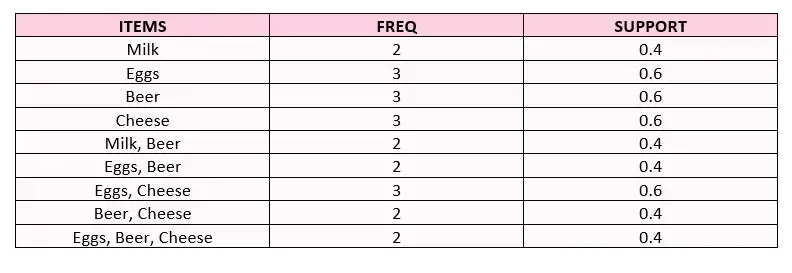
在所有购买的商品中,鸡蛋和啤酒占 40%。67%购买鸡蛋的顾客同时购买啤酒。购买鸡蛋啤酒销量增长1.11倍。根据最终表,可以进行这些评论。
由于我们已经检查了 Apriori 算法的工作逻辑,现在是时候创建一个 Python 项目,我们将在其中使用 Apriori 算法实现关联规则学习。
在这个项目中,我使用的数据是Online Retail II 数据集,大家可以到这里下载相关数据集,Online Retail II 数据集相关属性信息如下:
属性信息
- Invoice:发票编号,为每笔交易唯一分配的 6 位整数编号。如果此代码以字母“C”开头,则表示取消。
- StockCode:产品(商品)代码,唯一分配给每个不同产品的 5 位整数。
- Description:产品(商品)名称。
- Quantity:每笔交易的每个产品(商品)的数量,数字。
- InvoiceDate:发票日期和时间,生成交易的日期和时间,数字。
- UnitPrice : 单价。数字。以英镑 (£) 为单位的产品单价。
- CustomerID:客户编号,唯一分配给每个客户的 5 位整数号码。
- Country:国家名称,客户所在国家/地区的名称。
与数据集相关的操作和各种操作已经在前面的部分代码中完成,你可以在这里找到项目的完整代码。
我们要应用 ARL,首先,您应该准备 ARL 数据结构。我们需要一个 0 和 1 的发票项目矩阵,但在创建这个矩阵之前,我将把数据集缩减为一个国家。我选了法国,你可以选别的国家自己试试。
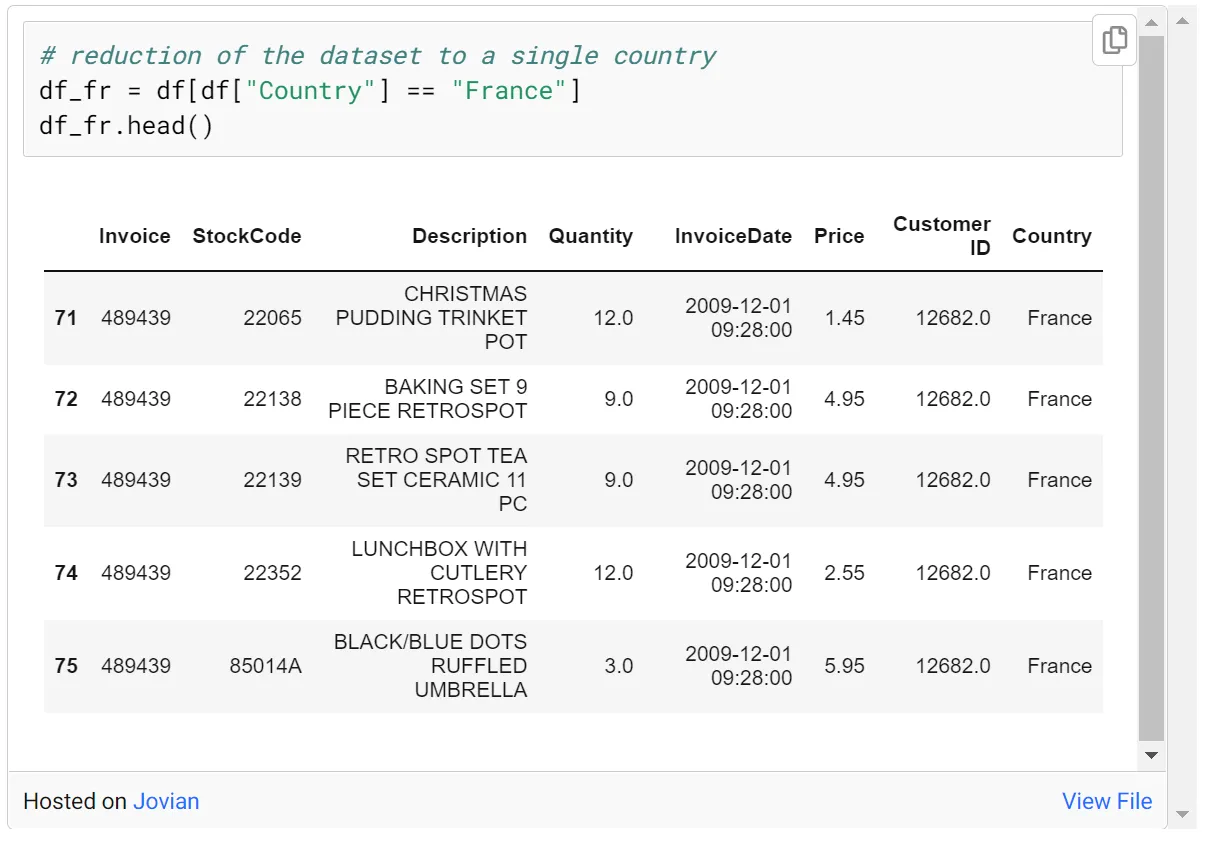
由于我们将数据集缩减为法国,接下来我们可以创建 Invoice-Item 矩阵。我们可以把StockCode和Description都作为Item,但是把Description作为Item会占用内存大,代码运行慢,所以把StockCode作为Item会更友好,而不是把产品名称作为Item。
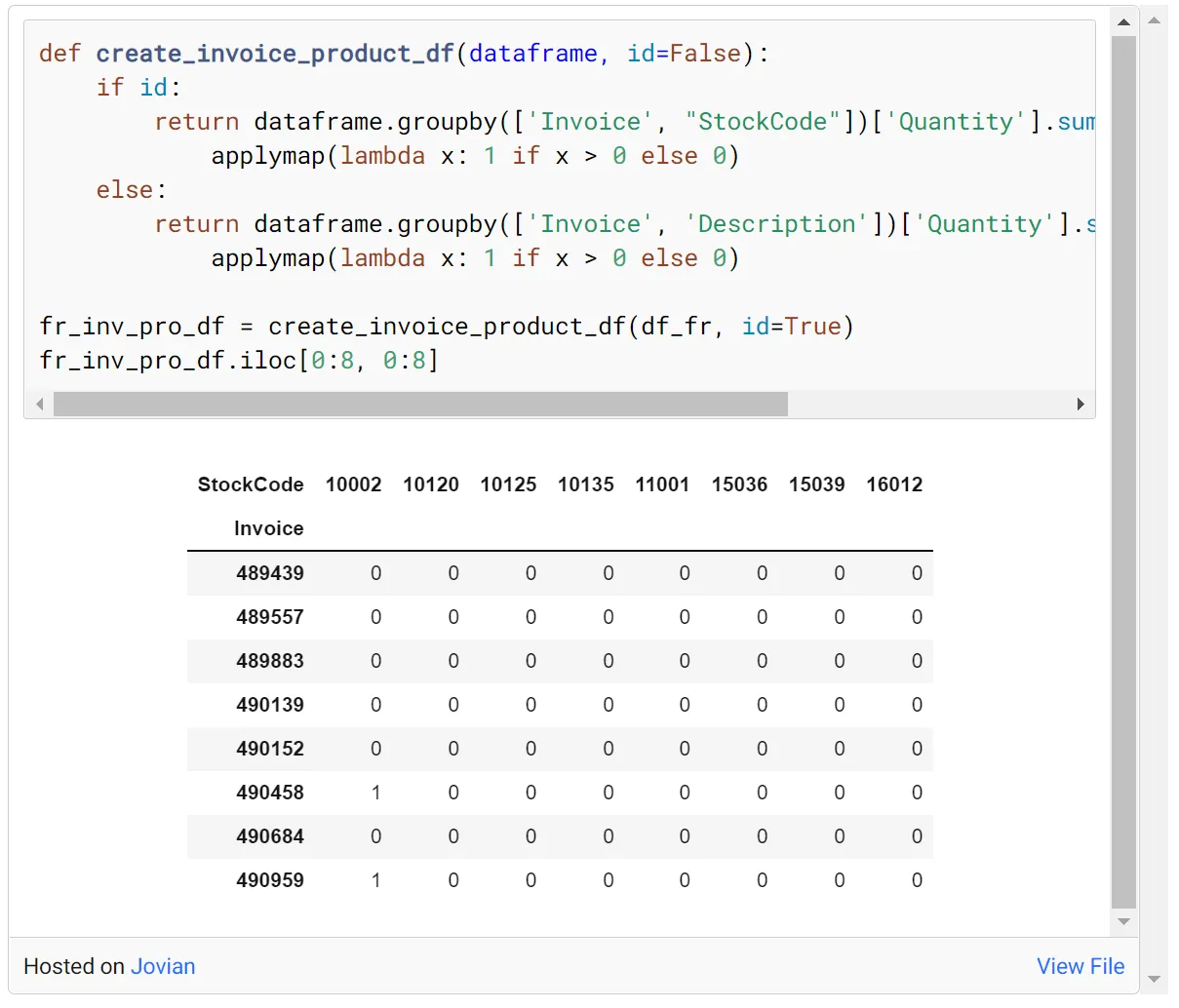
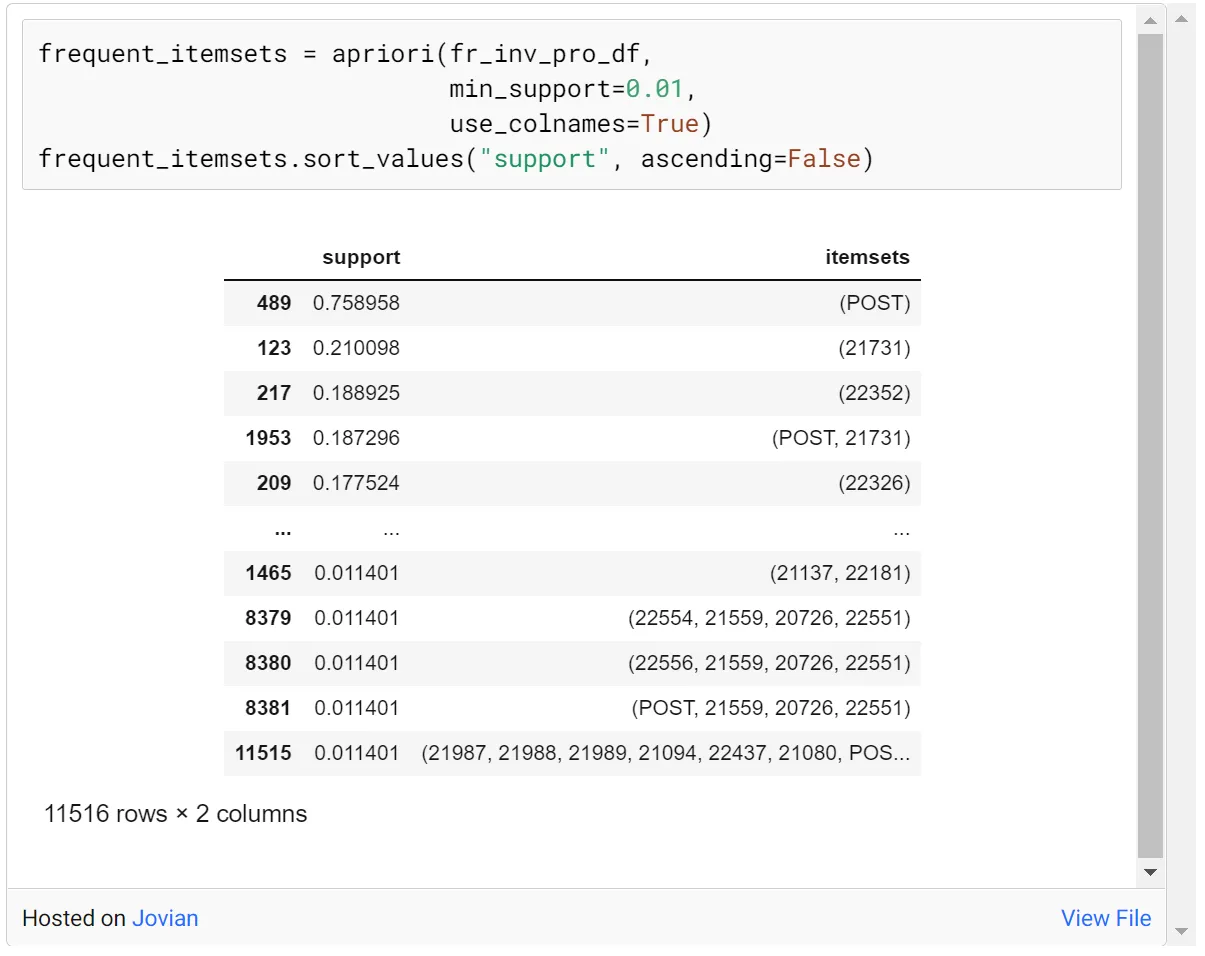
频繁项集是一组经常一起出现并达到预定义的支持度和置信度的项集。可以使用关联规则找到频繁项集。

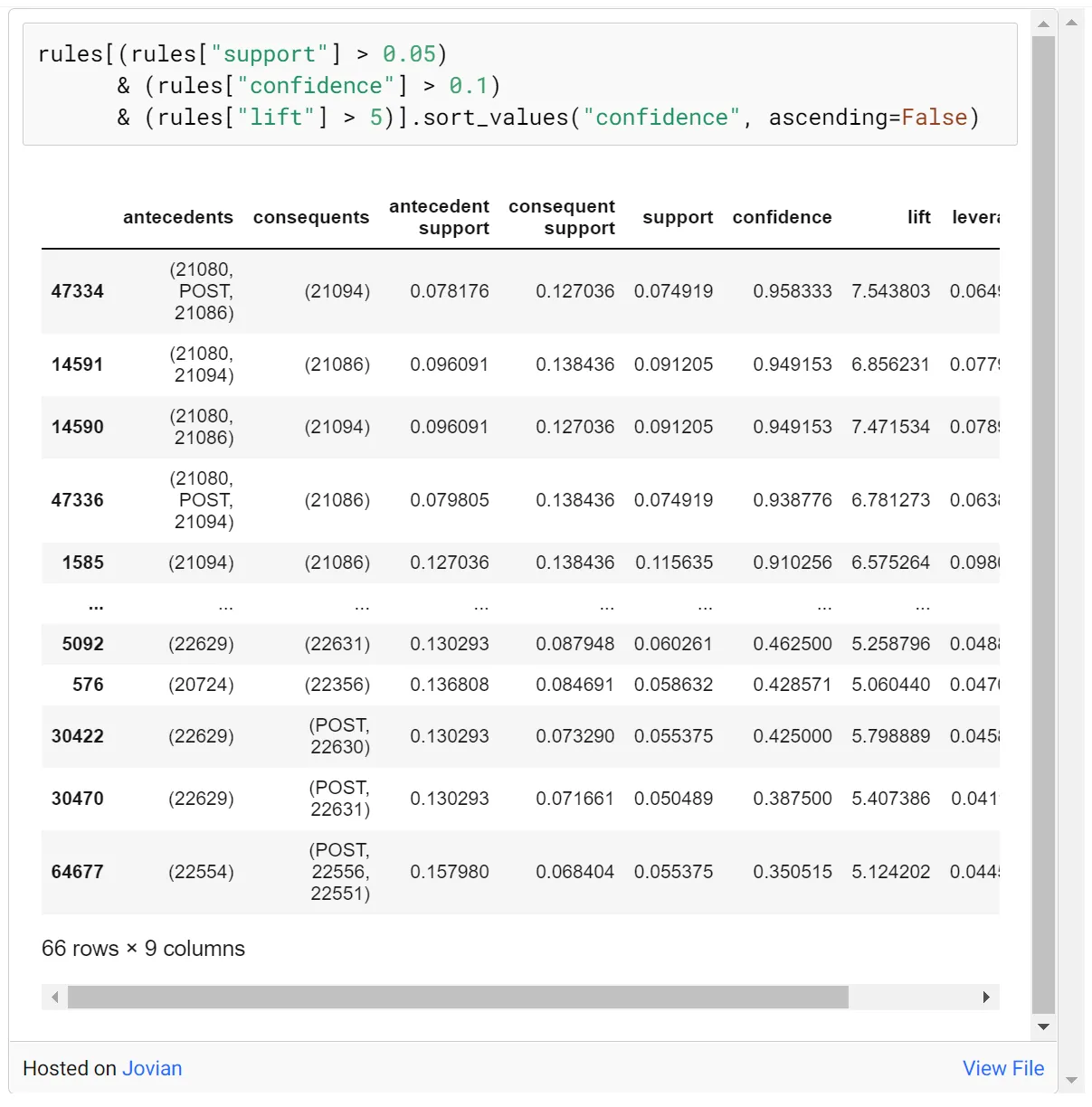
antecedents : first product
consequents : second product
antecedent support : proportion of transactions that contains antecedent A
consequent support : proportion of transactions that contains consequent C
support : items’ frequency of occurrence
confidence : conditional probability of purchasing consequents Y
when antecedents X is purchased
lift : How many times the probability of purchasing consequents Y
increases when antecedents X is purchased
leverage : similar to lift but it gives priority to higher support.
conviction : expected frequency of antecedents X without consequent Y
创建规则表后,可以根据需要(Support、Confidence、Lift、Leverage)进行排序,然后进行实现推荐过程。
作为最后一步,我们将进行产品推荐。为此,我们将使用一个函数,该函数将规则数据框、产品 ID 和要进行的推荐数量作为参数。
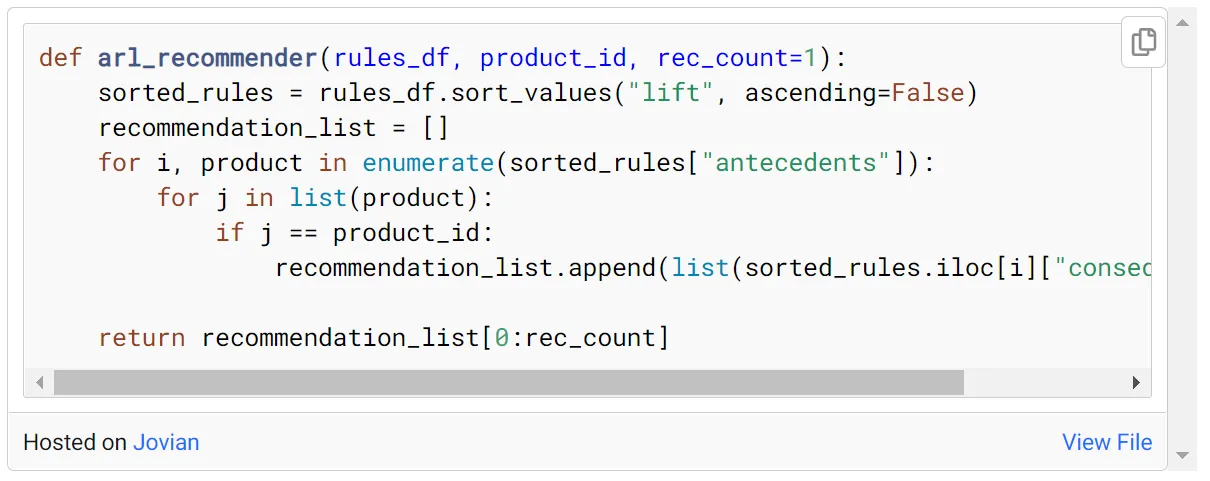
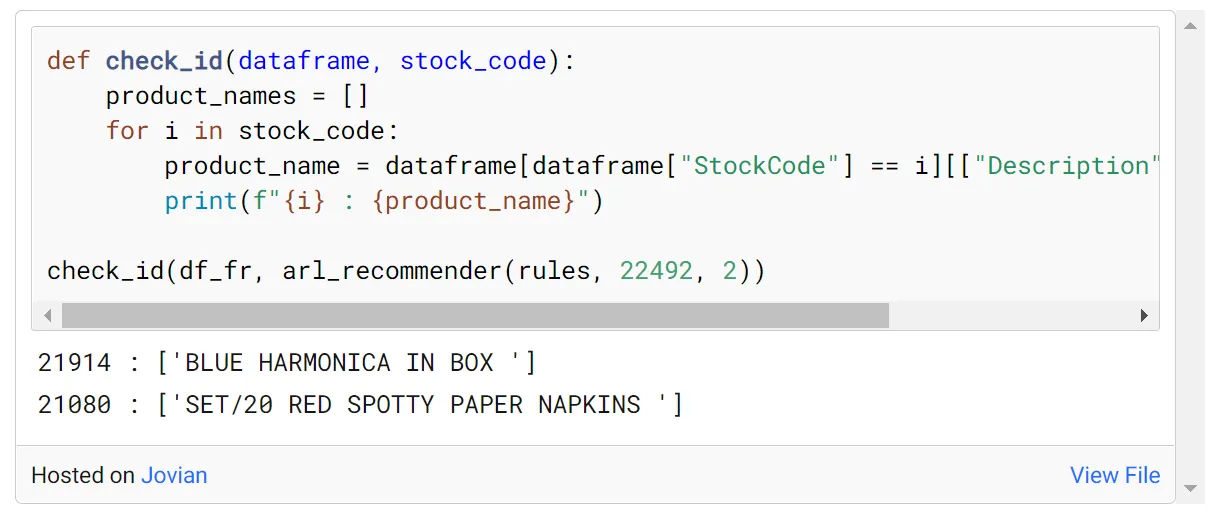
假设我们为商品id为22492的商品推荐2个商品。

通过使用以下函数,我们可以从我们要推荐的产品的 id 中检查产品名称。
推荐系统是一种常见的人工智能应用,其目的是为用户提供个性化的、有价值的内容或商品建议。它通常在电子商务、新闻门户网站、视频流媒体服务和社交媒体平台等场景中使用。
推荐系统通常会利用用户的历史浏览、购买、搜索等行为数据来对用户进行建模,然后根据用户的偏好为其提供建议。这些建议通常是按照用户的可能感兴趣的内容或商品的相关性排序的。