




A/B Test系统几乎已经成为企业的立足之本,但我们应该要如何设计一个A/B Test系统呐
有时在线上,我们用户为什么喜欢这个体验或为什么不喜欢,因为我们在实际应用中,我们无法以用户的视角思考。
在物理学或化学中,用到一种叫做“对照实验”的方法,来找出根本原因。同理我们也可以对互联网流量使用相同的方式进行测试对比。
例子
某企业在 腾讯视频 上投放一些产品的广告。UI设计师制定了两种不同风格的广告(称为Style 1和Style 2),内部讨论无法确定哪一种更受欢迎。因此,引入了 A/B 测试。
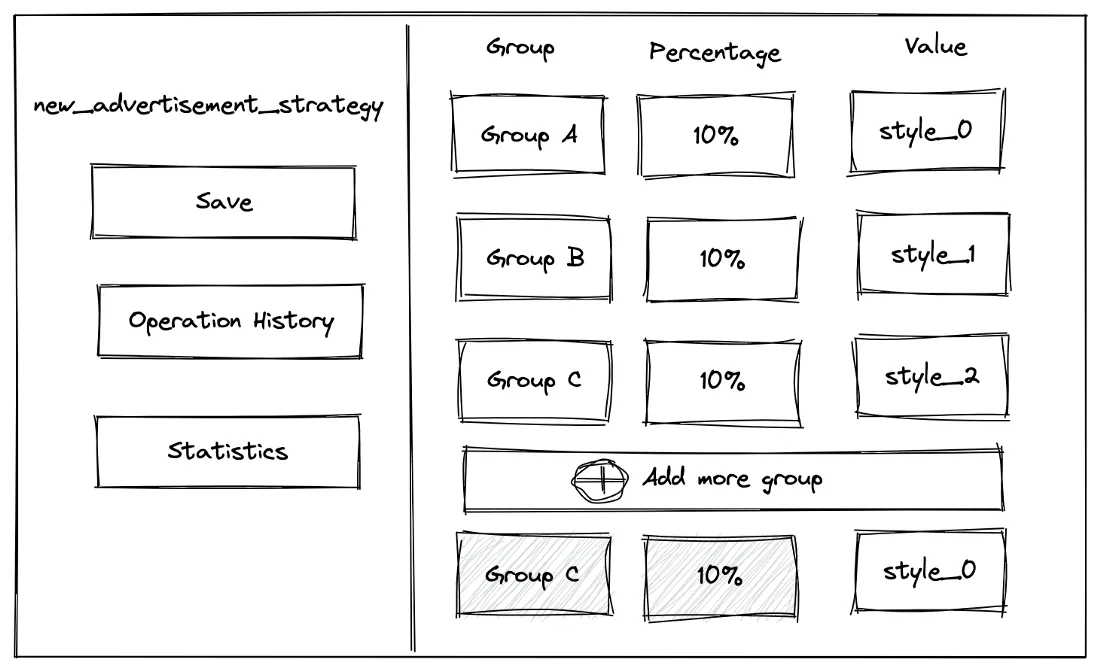
首先,我们设置了一个实验,在这个实验中,我们根据某种算法(后面会介绍算法)将用户分为 4 组:
- A组,占10%流量,不展示广告;
- B组,占10%流量,展示广告为Style 1;
- C组,占流量10%,展示广告为Style 2;
- 默认,占用70%流量,不显示广告。
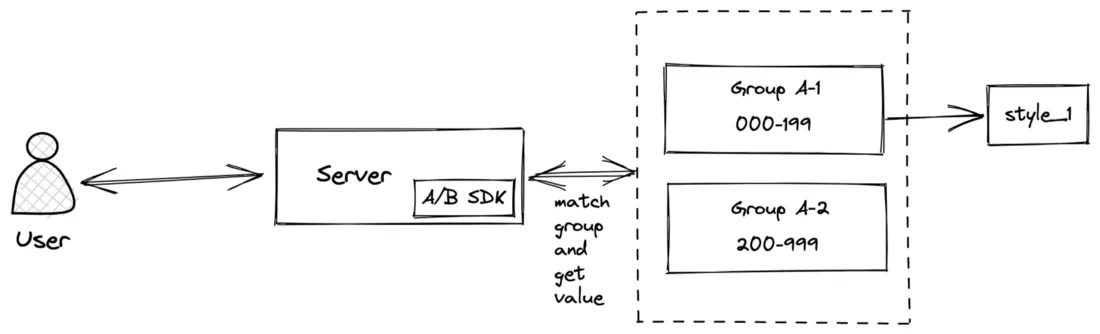
配置完成后,研发可以开发功能实现。在这种情况下,A/B 测试实验在后端进行,因此客户端只会渲染后端返回的样式枚举。
后端服务可以像下面这样实现:
experimentName := "new_advertisement_strategy", // A/B Experiment 的名称"new_advertisement_strategy" , // A/B 实验的名称
response.advertisementStyle = abtest.GetStringVal(
experimentName,
userId, // 来自请求的 userId
"style_0" , // 没有广告——exeption 的默认值
)
return response
功能发布后,新功能上线,我们可以查看实验组的统计数据,并进行分析:
- 将基本指标与基础指标(A 组)进行比较,例如 DAU、平均持续时间、留存率等。
- 将新指标与同行进行比较,在这种情况下,点击率是最重要的指标。
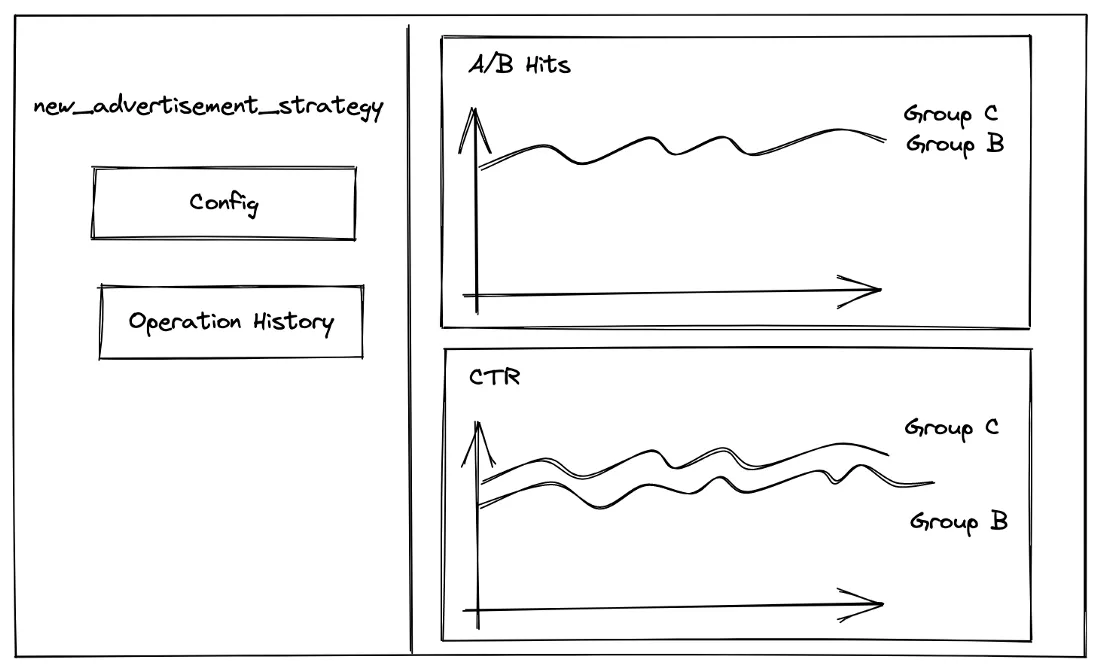
经过几天的分析,我们发现 B 组和 C 组对基本指标都没有副作用,这意味着这个广告可能不会让我们的用户不满意,所以可以放心地展示它。
并且,Group 3 拥有更好的点击率,这意味着 Style 2 将吸引更多用户点击并获得更多收益。
所以,最后,我们改变分组的策略:
- A组,占流量0%,不展示广告;
- B组,占流量0%,展示广告为Style 1;
- C组,占流量0%,展示广告为Style 2;
- 默认,占用100%的流量,以Style 2展示广告;
现在所有用户都将被分组为默认值,他们将看到此广告作为样式 2。
通过这种A/B Testing的方式,我们在有限的资源下找到了最合适的解决方案。
基本概念
在我们继续前进之前,我们必须澄清我们的概念。
A/B分组
分组算法的目标是将用户分成不同的组,并在其他组中使用不同的策略。
通过关注不同群体的不同行为,我们可以找出最有效的策略。
但分组不限于A、B两组,实验中可以有更多组。
并发实验
通常一项实验会影响所有用户,但系统中不会只有一项实验正在进行。
我们如何支持同时进行多项实验并确保它们能公平公正的进行实验呐?
答案是“正交”。我们使用不同的 hash salt 来拆分用户,这样一组 one experiment 将被统一拆分到其他组中。
比如我们让实验A和实验B同时进行,那么从整体来看,用户是统一划分的:
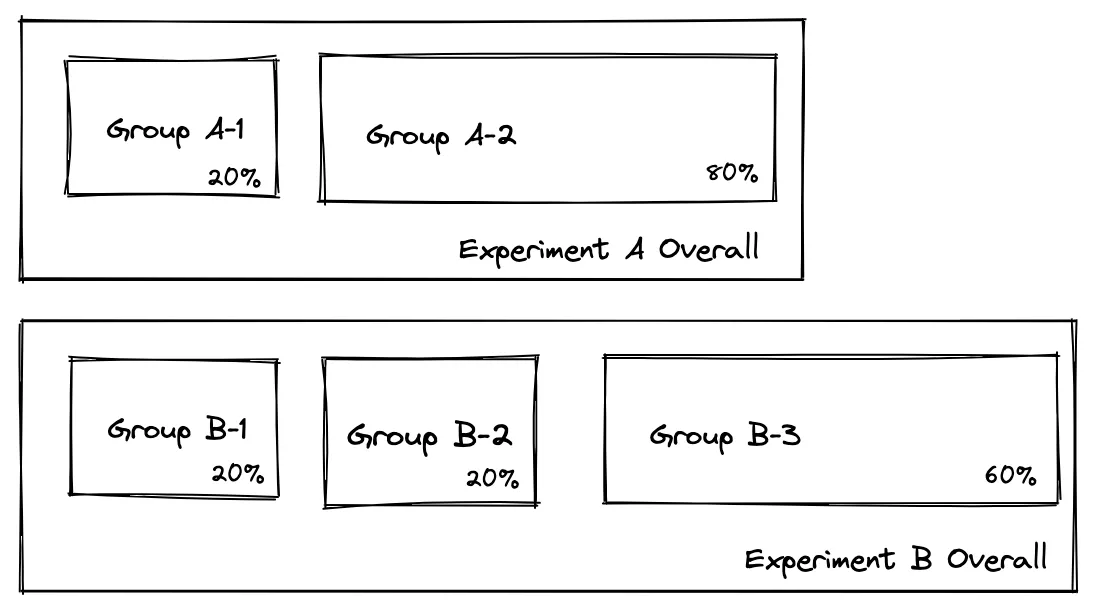
同时,A-1组内的用户也统一划分:
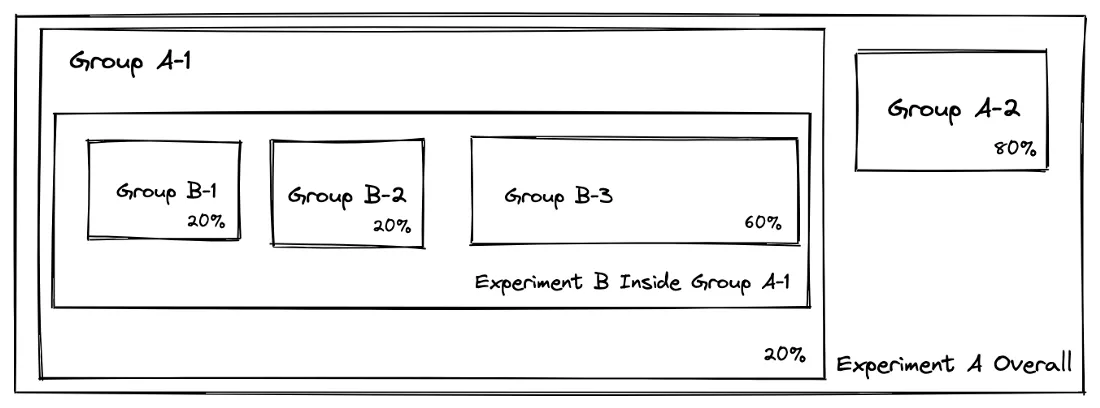
通过这种方式,我们可以支持大量同时进行且独立运行的实验。
基本组件
最简单的A/B Test系统应该包括这几个部分:
- 用于存储配置规则的数据库;
- 专为功能集成而设计的后端SDK;
- 数据仓库的分析工具。
数据库
在A/B Test的场景下,数据库应该就像KV存储一样,其中key代表实验名称,value代表分区规则和每组的值。
但对性能影响较小,读友好的KV存储应该更好,例如ETCD、ZooKeeper、Apollo等。
使用传统的数据库如 MySQL 或 MongoDB 是可以接受的,但我们最好在后端 SDK 中实现一些缓存策略。
后端SDK
有数据库的时候,后端SDK中应该也有数据库客户端。我们在为数据库实现客户端的时候,也应该更好的实现缓存部分。
然而,后端SDK最重要的部分是路由算法,因为我们需要从多方面进行考虑:
- 一次会有很多实验同时进行,我们应该考虑让这些实验对其他实验的影响较小;
- abtest#GetXxxVal(eg. GetStringVal) 系列函数应该是高性能的;
- abtest#GetXxxVal系列函数应该是稳定的,也就是说当实验没有变化时,只要参数没有变化,这些函数的返回值应该不会变化;
通常,我们会使用一个设计良好的哈希函数来完成,例如murmurhash或cityhash,核心逻辑将是这样的:
func GetStringVal (userId int64 , experimentName string , defaultVal string ) {
experimentConfig := getConfig(experimentName) // 从数据库获取配置
if experimentConfig == nil {
return defaultVal
}
salt := hashalgo.Hash(experimentName)
hashCode := hashalgo.HashWithSalt (userId, salt) % 1000 // 最小单位 0.1%
for _, group := range experimentConfig.Groups {
if group.EnableFor(hashCode) { // 如果 hashCode 在范围内则返回
report(userId, experimentName, group.Name) // 用于分析
return group.Val
}
}
return defaultVal
}
分析工具
统计数据是A/B测试的关键模块,因此数据仓库的分析工具必不可少。
但是不同的团队可能希望在不同的技术堆栈中实现他们的数据仓库,因此分析工具也会有所不同。
正如上面有一行代码,例如:
report(userId, experimentName, group.Name) // 用于分析// 用于分析
大多数情况下,我们会向 Kafka 或 Pulsar 等队列发送一条消息,然后我们将消费这些消息并将其写入 Hive 或 Clickhouse 等数据仓库。
然后,当我们查询业务指标时,我们可以将它们与 A/B 测试命中率结合起来,以便我们可以分析组之间的差异。
延伸话题
特征过滤器
当我们需要设置一个新的 A/B Test 实验时,通常它会需要一些前提条件,例如:
- 作为一个全国性应用,我们为来自不同地区的用户提供服务,但有时由于区域习惯,某些地区需要禁用某个功能;
- 对于移动应用程序,我们应该处理版本碎片化。不是每个人都使用最新版本的应用程序,所以我们应该过滤一些旧版本的应用程序,这就需要用到版本过滤器。
所以,在这些情况下,我们应该过滤掉无效流量,然后再做实验。

客户端SDK
有时我们只想在客户端进行实验。例如,更改标题的颜色或更改图标(经典案例是张一鸣当初做九房网时的logo测试)。
我们可以让服务器来帮助客户做这些实验,这就比较复杂和多余。
为客户端设计一个 SDK 可以帮助我们解决这个问题。在Client SDK中,纯客户端特性实验不需要服务器后端协助。
Client SDK 会在应用程序启动时请求 A/B 测试值,然后缓存这些值直到下一次成功响应返回。
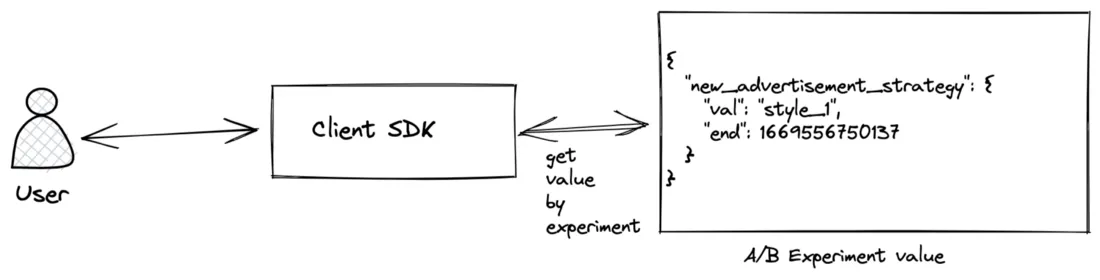
A/B 测试值是某种地图:
{
“new_advertisement_strategy” : {
“val” : “style_1” ,
“end” : 1669556750137
}
}
结论
所有公司都关心业务指标,A/B 测试是我们指导产品方向的最强大有效的工具。
构建 A/B 测试系统非常简单,但也并不容易,需要根据具体业务具体分析。