




该文章来自字节跳动大佬的分享
一、科学革命:人类文明的新篇章
“Now I am become Death, the destroyer of worlds.”
“现在我成了死神,世界的毁灭者。”
——核物理学家奥本海默在目睹了第一颗原子弹爆炸的骇人景象后,引述《薄伽梵歌》说道

1945年7月16日凌晨5点29分45秒,科学家在美国新墨西哥州的阿拉莫斯沙漠中引爆了第一颗原子弹。这一秒可以称之为近百年来人类文明中最具有历史意义的一刻,从这一刻开始,人类不仅仅只是在改变历史进程,甚至有了终结历史进程的能力。
科学革命将人类带到阿拉莫斯沙漠,带上月球表面,搭载着刻录了人类文明喧嚣的镀金唱片的旅行者一号甚至已经飞往太阳系之外。近百年来,科学革命之下的人类文明发展之快,是任何最疯狂的梦想家都难以预料的。
在过去的数百年中,人们愈发相信可以通过加强科学研究来获得前所未有的强大力量。而且这并不是盲目迷信,而是经过了严谨的逻辑推导和反复的观察和证明,就像数学一样精确,就像我们可以自信地说出,1+1就是等于2,而绝不会是其他什么答案。如果没有科学带来的确定性和赋予人类的强大力量,人类永远无法分裂原子,无法在月球上漫步,更不可能冲出太阳系。
二、从玄学走向科学:为什么要做AB实验
一个人预测和应对未来的能力,取决于他对事物变化背后的因果关系的理解;一个人理解这些因果关系的能力,来自他对以往变化的发生机制的研究。
——原则:应对变化中的世界秩序-瑞·达利欧
1. 告别野蛮生长的经验时代
十多年前,曾经有过这样一句话:“站在台风口,猪都能飞上天。” 在当年智能手机普及引发的移动互联网大潮之中,“风口上的猪”成为许多企业的真实写照。
然而,今时今日,野蛮生长的互联网红利期一去不返,流量成本愈发昂贵,产品迭代试错成本高昂,制约了企业进一步增长的潜力。许多当年趁着潮水涌入的玩家们,如今面临着日益严峻的增长乃至生存困境。原因其实很简单,只有潮水退去了才能知道谁在裸泳,企业增长最终要依靠的,仍然是科学而又行之有效的增长策略,以及苦心历练而成的基于科学而非玄学的综合能力。
数据驱动是科学增长的底层逻辑。成功不应该靠玄学或者运气,而是有一套完备的方法论,每个人都应该学会,并且都能够学会。我们要像科学家研究原子弹和登月火箭一样做产品增长,通过科学实验,大胆假设,小心求证,发掘出增长背后的“第一性原理”。
当今的时代,日新月异,变化万千,被称之为VUCA时代(复杂性Complexity、模糊性Ambiguity、不确定性Uncertainty、波动性Volatility)。在不确定的时代下,科学增长的数学般精准的确定性,成为了我们最值得信赖的依靠。
通过科学的AB实验,我们可以确保每个决策都能带来正向收益,实现复利效应,实现持续循环的可持续增长:
- 消除产品设计中不同意见的无休止的争论,根据实验的效果,科学决策,确定最佳方案
- 让大胆创新快速试错成为可能,快速准确地检验新策略上线后的效果
- 快速定位问题的真正原因,避免低效而又昂贵的错误迭代
- 降低新产品或新功能发布的风险,为产品持续迭代提供保障
2. 什么是AB实验:随机对照实验
AB实验又称随机对照实验(randomized controlled trial,RCT)。随机对照实验最初来源于来自生物医学的领域。
1747年5月20日,詹姆斯·林德做了人类历史上第一个随机对照实验。林德将船上患了坏血症的海员分为多组,每组喂食不同的食物,从而尝试验证哪种食物可以治疗败血症。虽然由于时代的局限性,林德当时没能成功指出橘子中含有的维生素C可以治疗败血症,但是由于这是历史上第一次用随机对照实验检验药物疗效的尝试,林德仍然青史留名。林德的实验标志着检验药物有效性的方法从蒙昧走向科学。
在现代生物医学领域的双盲测试中,病人被随机分成多组,在不知情的情况下分别给予安慰剂和测试用药,经过一段时间的实验后,比较这两组病人的表现是否具有显著的差异,从而确定测试用药是否有效。随机对照试验的基本方法是,将研究对象随机分组,对不同组实施不同的干预,在这种严格的条件下对照效果的不同。在研究对象数量足够的情况下,这种方法可以抵消已知和未知的混杂因素对各组的影响。
在互联网产品的迭代优化中,我们通常使用小流量AB实验,也即在线上流量中取出一小部分(较低风险),完全随机地分给原策略A和新策略B(排除干扰),再结合一定的统计方法,得到对于两种策略相对效果的准确估计(量化结果)。这一套基于小样本的实验方法同时满足了低风险,抗干扰和量化结果的要求,因此不论在互联网产品研发还是科学研究中,都被广泛使用。
3. AB实验是互联网公司的标配
随着互联网产业的发展,AB实验借着互联网科技公司的发展的大潮,不断发扬壮大。从远在太平洋彼岸的苹果、爱彼迎、亚马逊、脸书、谷歌、领英、微软、优步等硅谷弄潮儿,到国内的BAT巨头、以及字节跳动等科技公司,都在高频使用AB实验协助决策。早在2000年左右,谷歌工程师首先将AB实验应用在互联网产品的迭代测试中。
在这之后,AB实验渐渐普及开来,逐步成为数据驱动增长的经典手段,助力了大量互联网产品的迭代优化。今天,谷歌微软这些科技公司每年进行着数以万计的实验,覆盖了亿级的用户量,实验的内容涵盖了绝大多数产品特征的迭代优化,从产品命名到交互设计,从改变字体、弹窗效果、界面大小,到推荐算法、广告优化、用户增长等等。
2012年,一位微软必应搜索引擎的员工,创建了AB实验来验证不同展示方式的广告标题的效果。没有想到的是,这一小小的AB实验却带来了万分惊艳的效果。在数小时内,实验组广告收入增加了12%,同时没有给用户体验的相关指标带来任何负面影响。这个实验因为效果实在是太好而令人难以相信,所以后来微软将这一实验重复了很多次,结果却惊人的一致,都是巨幅的收入提升。具体的实验内容十分细微,仅仅是将标题下的第一行正文添加到标题行,形成一个更长的标题行。这一简单方案一开始并不被大家看好,因此这个需求的优先级较低,被搁置了长达6个月之久。这一微小的改动当时仅仅在北美就为微软创造了超过1亿美元的年收入,可想而知AB实验带来的潜在收益会有多大。事实上,微软也是世界上最早采用A/B实验评估每一个重大feature的科技公司之一,从bing的搜索排序到MSN的交互设计,数据驱动的决策无处不在,每年为微软规避大量风险并创造可观回报。
谷歌早在2000年就尝试通过AB实验来优化搜索结果页的结果条数。虽然当时的第一个实验由于页面加载过慢导致实验没有达到预期结果,但是AB实验的基础设施和通过实验评估迭代产品功能的理念就此生根发芽,为后续更加复杂的AB实验打下了基础。在首次运行AB实验11年之后,谷歌最多已经同时运行多达7000个不同的AB实验。2016年,谷歌对搜索结果页的链接颜色进行了实验。谷歌对进入到搜索结果页的用户进行随机分流,一部分用户看到的链接是蓝色,另有一部分用户看到的链接是黑色。谷歌甚至会对链接的不同深浅的蓝色做进一步的实验,在整整测试了41种蓝色之后,找到了颜色最佳的那一抹蓝。最终在实验中优胜的蓝色每年多为谷歌带来两亿美元的收入。
字节跳动有着非常浓厚的AB实验文化,在字节跳动流行着这么一句话:AB 实验,是一种信仰,万物皆可试验。截至2022年8月,字节跳动累计已有150W+ 次实验,日新增实验 2000+,同时运行实验 3W+,服务 500+ 业务线。
A/B实验广泛应用于字节跳动方方面面,从产品命名到交互设计,从改变字体、弹窗效果、界面大小,到推荐算法、广告优化、用户增长。字节跳动几乎把AB实验应用到了每一个业务和每一项决策中。字节跳动的明星产品抖音,它的名字,就是AB实验的产物。字节跳动做短视频App的时候,将产品原型起成不同的名字、使用不同的Logo,封装成不同的应用包,在应用商店做AB实验。在最后的实验结果中,虽然“抖音”这个名字在测试结果中只排名第二,但大家觉得,这个名字更符合用用户认知,更能体现它的形态,所以还是选了它。
三、大型在线对照实验:现代AB实验系统综述
Instead of saying ‘I have an idea’, what if you said ‘I have a new hypothesis , let’s go test it, see if it’s valid, ask how quickly can we validate it.’ And if it’s not valid, move on to the next one. —— Satya Nadella CEO, Microsoft
与其说’我有一个想法’,不如说’我有一个新的假设,让我们去测试一下,看看它是否有效,问问我们能多快验证它。如果它无效,继续下一个。——Satya Nadella 微软首席执行官
在互联网的应用场景下,AB实验主要被用于大规模的在线测试,因此也被称为在线对照实验(Online Controlled Experiment,OCE)或者在线AB实验。在线AB实验中,部分用户被随机选出参与实验,并在打散后均匀分入不同的策略组。同时还会有日志系统根据实验配置情况标记不同的用户,并且记录用户的行为,然后大数据分析系统基于带有实验标记的日志数据计算各类实验指标结果形成可供决策者参考的实验报告。于是产品运营人员就可以通过这些指标去分析不同的策略对实验用户是否产生了作用,产生了什么样的作用,是否符合实验假设,最终科学指导产品的迭代方向。
1. AB实验的基本原理
为了验证一个新策略的效果,准备原策略A和新策略B两种方案。随后在总体用户中取出一小部分,将这部分用户完全随机地分在两个组中,使两组用户在统计角度无差别。将原策略A和新策略B分别展示给不同的用户组,一段时间后,结合统计方法分析数据,得到两种策略生效后指标的变化结果,并以此判断新策略B是否符合预期。上述过程即A/B实验,亦被称为“对照实验”或“小流量随机实验”。
从不同角度来看,AB实验可以有几种不同的分类。按照常见的分类方式,AB实验可以分为以下几类:
- 从实验产品的形态来看,AB实验可以分为:手机App客户端、桌面客户端、手机Web页面,桌面Web网页等。
- 从实验分流服务的调用方式来看,AB实验可以分为:客户端SDK分流、服务的HTTP接口分流等。
- 从实验分流的实验对象来看,AB实验可以分为:页面类型、元素类型,用户类型、会话类型等。
2. AB实验的随机分流
开设A/B实验,顾名思义,我们至少需要一个A组和一个B组,那么究竟是什么决定了哪些用户被实验命中,以及哪些用户进入A组/B组呢?就是靠A/B实验分流服务。分流服务需要帮助实验者,从总体流量中抽取部分流量,并将抽取的流量随机地分配进A组与B组之中,尽量减少抽样误差。
在对实验对象进行随机分流时,我们需要特别关注以下几个问题:
- 实验对象如何被随机分为实验组和对照组
- 实验量增加后,流量不够用的问题如何解决
- 不同层之间的正交性是如何实现并保证的
下面会着重讨论这些问题。
① 哈希算法
随机分流的随机性是通过哈希算法来实现的。哈希函数在对用户进行分组的时候,由于只用到了用户标识,而且能把有规律的id集合散列的很均,所以在其他属性(比如机型、地域、年纪、性别等)上能分得很均匀。哈希函数还有一个特性:如果输入值是固定的,那么哈希函数的输出值也是固定的。因此,哈希算法可以保证用户不会跳组,即不会出现张三上午在版本A,下午在版本B。
AB实验分流系统中常见的散列算法有MD5、SHA、Murmur等,其中比较推荐的是Murmur。Murmur算法的计算性能更好,抗碰撞性更强,均匀性、相关性也是最好的,因此在工程实践中运用最多。
② 实验层
实验层技术是为了让多个实验能够并行不相互干扰,且都获得足够的流量而研发的流量分层技术。
假如现在有4个实验要进行,每一个实验要取用30%的流量才能够得出可信的实验结果。此时为了同时运行这4个实验就需要4*30%=120%的流量,这意味着100%的流量不够同时分配给这4个实验。那么此时我们只能选择给实验排序,让几个实验先后完成,但是这样会造成实验效率低下。
实验层技术就可以完美解决这个问题:我们把总体流量“复制”无数遍,形成无数个流量层,让总体流量可以被无数次复用,从而提高实验效率。各层之间的流量是正交的,可以简单理解为:在流量层选择正确的前提下,流量经过科学的分配,可以保证各实验的结果不会受到其他层实验的干扰。
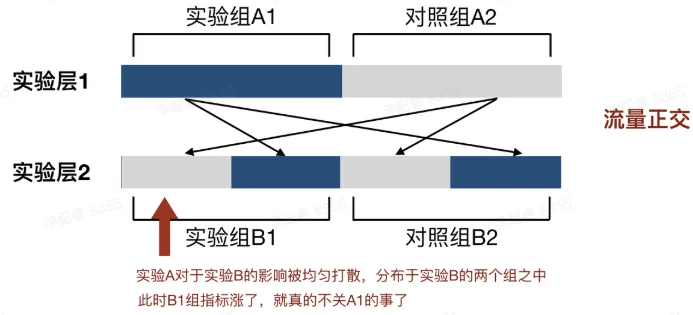
③ 流量正交
流量正交指的是每个独立实验为一层,一份流量穿越每层实验时,都会随机打散再重组,保证每层流量数量相同。
举个例子。假设我现在有2个实验。实验A(实验组标记为A1,对照组标记为A2)分布于实验层1,取用该层100%的流量;实验B(实验组标记为B1,对照组标记为B2)分布于实验层2,也取用该层100%的流量。(要注意,实验层1和实验层2实际上是同一批用户,实验层2只是复用了实验层1的流量)
如果把A1组的流量分成2半,一份放进B1组,一份放进B2组;再把A2组的流量也分成2半,一份放进B1组,一份放进B2组。那么两个实验对于流量的调用就会如下图所示。此时实验A和实验B之间,就形成了流量“正交”。
我们可以发现,因为A1组的一半流量在B1中,另一半流量在B2中,因此即使A1的策略会对实验B产生影响,那么这种影响也均匀的分布在了实验B的两个组之中;
在这种情况下,如果B1组的指标上涨了,那么就可以排除B1是受A1影响才形成上涨。这就是流量正交存在的意义。
3. AB实验的指标
在互联网行业中,指标是指反映某种事物或现象,描述在一定时间和条件下的规模、程度、比例、结构等概念,通常由指标名称和指标数值组成。指标,可以分为简单计数型指标和复合型指标。
- 简单计数型指标是指可通过重复加1这一数学行为而获得数值的指标,如UV(Unique Visit , 独立访客数)、PV(Page View,页面浏览量)。
- 复合型指标是由简单计数型指标经四则运算后得到的,如跳出率、购买转化率。
AB实验的指标,根据对实验影响的重要程度,有以下两类需要重点关注:
① 核心指标
核心指标,用来决策实验功能是否符合预期的「直接效果指标」 也叫「成功指标」。只可以设置一个指标为某个实验的核心指标,可在实验报告里面查看实验数据。
比如开设「按钮文案」的优化实验,那么「按钮点击率」就是该实验的核心指标。
一般常见的核心指标,如下:
- 转化率、uv/au类,如留存率;
- 人均次数类,如pv/au、pv/uv、sum/au、sum/uv;
- 平均值类,如sum/pv;
② 围栏指标
围栏指标,又称必看指标,指的是必须守护的业务线指标,实验功能可能对其无直接的因果关联、无法直接带来提升,但一般而言不能对其有显著负向影响。
4. AB实验的统计学原理
① 假设检验
A/B实验的核心统计学理论是(双样本)假设检验。假设检验,即首先做出假设,然后运用数据来检验假设是否成立。需要注意的是 ,我们在检验假设时,逻辑上采用了反证法。通过A/B实验,我们实际上要验证的是一对相互对立的假设:原假设和备择假设。
**原假设(null hypothesis):**是实验者想要收集证据予以反对的假设。A/B实验中的原假设就是指“新策略没有效果”。
**备择假设(alternative hypothesis):**是实验者想要收集证据予以支持的假设,与原假设互斥。A/B实验中的备择假设就是指“新策略有效果”。
利用反证法来检验假设,意味着我们要利用现有的数据,通过一系列方法证明原假设是错误的(伪),并借此证明备择假设是正确的(真)。这一套方法在统计学上被称作原假设显著性检验 null hypothesis significance testing (NHST)。
举个例子:我们要针对某页面的购买按钮做一个实验。我认为:将购买按钮的颜色从蓝色改为红色,可以提高购买率3%。在这个实验中,我们想通过统计学检验的“原假设”就是“购买按钮改成红色不能提升购买率”;“备择假设”就是“购买按钮改成红色能够提升购买率”。这是一对互斥的假设。也就是说,实际上我们要证明的就是“改成红色不能提升购买率”是错误的。
② 第一类错误和显著性水平(α)
第一类错误,指原假设正确(真),但是我们假设检验的结论却显示原假设错误。这一过程中我们拒绝了正确的原假设,所以第一类错误是“弃真”。
第一类错误在实际操作中表现为:实验结论显示我的新策略有用,但实际上我的新策略没有用。
在统计学中,我们用显著性水平(α)来描述实验者犯第一类错误的概率。
当某个实验组的指标是显著的,说明这个实验结果大概率是可信的。这个概率是95%,也就是说,系统有95%的信心确认这个实验结果是准确的。
显著性水平存在的意义是什么?
一个按钮从蓝色改成红色,一个窗口从左边移到右边,到底用户体验会变好还是变差呢?我们并不确定,因此我们试图使用A/B实验的办法,帮助我们转化这种“不确定”——观察小流量实验中新旧策略的表现,从而确定新旧策略的优劣。
但是,这样就能完全消除不确定性了吗?答案是不能,因为存在抽样误差。
举个例子,假设瑞士人均收入为中国的十倍,那么随机抽三个瑞士人和三个中国人,能保证样本里这三个瑞士人的平均收入是三个中国人的十倍吗?万一这三个中国人是马云,王健林和一个小学生呢?
反过来想,假设在1%的流量下,组A(按钮呈红色)比组B(按钮呈现蓝色)购买率高,将流量扩大至100%,能保证策略A的表现仍旧比策略B出色吗?显然,我们还是不确定。
抽样误差带来的不确定性,使得我们在做小流量实验时,永远没法保证结论是完全正确的。幸运的是,对于抽样的不确定性,在统计学中,我们有一套方法来量化这种不确定性到底有多大,这便是显著性水平(α)存在的意义。
③ 第二类错误( β )和统计功效(statistics power)
第二类错误,指原假设错误(伪),但是我们假设检验的结论却显示“原假设正确(真)、备择假设是错误的”,这一过程中我们接受了错误的原假设,所以第二类错误是“取伪”。
第二类错误在实际操作中表现为:我的新策略其实有效,但实验没能检测出来。
在统计学中,统计功效 = 1 - 第二类错误的概率,统计功效在现实中表现为:我的新策略是有效的,我有多大概率在实验中检测出来。
④ 统计显著性/置信水平/置信度/置信系数
置信水平(也称置信度、置信系数、统计显著性),指实验组与对照组之间存在真正性能差异的概率,实验组和对照组之间衡量目标(即配置的指标)的差异不是因为随机而引起的概率。置信水平使我们能够理解结果什么时候是正确的,对于大多数企业而言,一般来说,置信水平高于95%都可以理解为实验结果是正确的。因此,默认情况下,「A/B 测试」产品将置信水平参数值设置为95%。
在A/B实验中,由于我们只能抽取流量做小样本实验。样本流量的分布与总体流量不会完全一致,这就导致没有一个实验结果可以100%准确——即使数据涨了,也可能仅仅由抽样误差造成,跟我们采取的策略无关。在统计学中,置信度的存在就是为了描述实验结果的可信度。
在实验的过程中,我们所抽取的样本流量实际上与总体流量会存在些许的差异,这些差异就决定了我们通过实验得出的结论或多或少会存在一些“误差”。
举个例子,实验中,我通过改变落地页的颜色让购买率提升了3%,但是因为样本流量并不能完全代表总体流量,有可能“我改变颜色这一策略其实没用,购买率提升3%是抽样结果导致的”。
那么发生这种“我的策略其实没用”事件的概率有多大呢?在统计学中,我们会用“显著性水平(α)”来描述发生这一事件的概率是多少。而置信度=1-α。
在「A/B 测试」产品上,根据业界标准,显著性水平α取0.05。在A/B实验中,如果发生“我的策略其实没用”这一事件的概率小于0.05,我们即称实验结论已经“统计显著/可置信”。这意味着你采取的新策略大概率(A/B实验中意味着大于95%)是有效的。相反,如果这一事件的概率大于0.05,则称实验结论“不显著/不可置信”。
⑤ 中心极限定理
显著性水平的理论依据便是中心极限定理。我们可以量化抽样误差的根基在于中心极限定理的存在。
什么是中心极限定理?
由于存在抽样误差,我们每次实验所得到的指标结果,都可能与我们期望得到的真正结果有误差。假设我们从总体中抽取样本,计算其指标的均值,每一次计算,样本均值都会受抽样误差影响。假如我们做无数多次实验,那么理论上,这无数多个样本均值中,总应该有一个是“真的”,不受抽样误差影响的,这个值在统计学里被称为“真值”。
中心极限定理定告诉我们,如果我们从总体流量里不断抽取样本,做无数次小流量实验,这无数次抽样所观测到的均值,近似呈现正态分布(就是下图这样的分布)。这个分布以真值为中心,均值越接近真值,出现的概率就越大;反之均值越偏离真值,出现的概率就越小。
PS:此处为了便于理解,放弃了阐述统计学概念,仅从A/B实验场景下出发,解释中心极限定理。
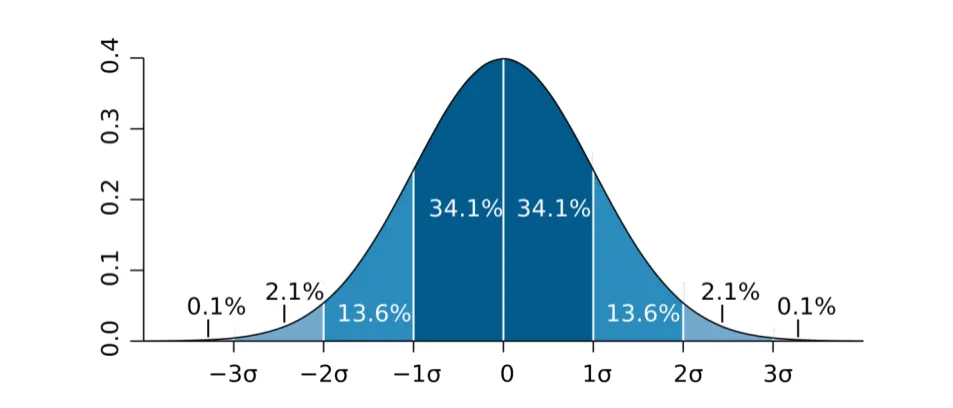
为什么样本均值越接近真值,出现的概率越大?
举个例子,如果从全中国人这个总体中,抽取很多很多次样本,计算很多很多次平均收入。
可以预见,我们会因为样本不同而得到很多个不同的平均收入值。这些数值确实有可能因为偶然抽到顶级富豪而偏高,或因为抽到极贫困的人口而偏低。但是,上述两种情况毕竟是少数(均值越偏离真值,出现的概率小)。随着抽样次数增多,我们会发现,平均收入落在大多数普通人收入范围内的次数,会显著增多(均值接近真值,出现的概率大)。并且,有了中心极限定理的帮助,我们可以知道每个均值出现的概率是多少。
5. AB实验的应用场景
产品优化迭代的各方面都可以使用AB实验,其中有以下几类典型应用场景:
① 产品优化
产品优化的最终目的在于提升每一个用户的用户体验,理想的用户体验是用户感到高兴、满足、骄傲甚至是爱上这款产品。不过,一千个人眼中有一千个哈姆雷特。每个人对于美的喜好都不相同,有的时候甚至是完全不一样的。尤其是在面对来自不同背景不同文化的用户的时候,产品运营和设计人员更难以准确揣摩用户的喜好。汝之砒霜彼之蜜糖,只有通过AB实验才能够科学衡量不同设计方面的实际效果。
② 算法迭代
互联网时代发展到今天,算法已经渗透到了互联网产品中的每一个角落,从短视频信息流,电商购物,打车出行,到个性化音乐视频推荐,每一项功能背后可能都蕴含着复杂的算法。以推荐系统中的推荐算法为例,特别是广泛应用的深度学习模型,参数的量级可能是上千万的,有着很强的黑盒属性,完全依靠人工优化已经不再现实。优化一个特征、一个模型、一路算法、一个参数之后,用户体验如何,是不是向着期望的方向迭代,都无法简单通过经验来判断。算法模型参数复杂,影响因子众多,一个简单的策略优化对用户体验的影响是难以预料的。如果不用AB实验,我们很难评估算法模型的实际效能。可以说,AB实验是智能时代算法迭代的最佳搭档。
③ 私域运营
客户运营场景下的许多活动,例如用户社交裂变、红包活动、短信拉活都是可以使用AB实验的典型场景。使用大额红包等运营策略,一般都可以在短时间内大幅提升产品的各项核心数据,但是谁也没法说准是否能够有效提升长期roi,很多情况下成本过高的运营活动可能在整个用户生命周期都无法回本,长期以往对于产品的长远发展无异于饮鸩止渴。如果没有AB实验的科学量化和数据说话,很难避免短期利益对于长期利益的损害。
④ 公域营销
公域下的广告营销也是一个典型的可以使用AB实验的场景。“我有一半的广告费都被浪费了,但就是不知道是哪一半。” 零售大亨约翰·沃纳梅克这句经典名言被称为广告界的哥特巴赫猜想,道出了广告营销的难点。应该如何科学的衡量广告的效果一直既是业界的重点、热点也是难点。基于AB实验,我们可以针对性别、年龄、职业、地域等不同的广告人群定向,或者不同的广告预算出价、风格各异的广告素材,乃至线上线下不同的广告投放渠道等进行科学的对照实验,发掘出最优的投放策略,有望为广大广告主节省下巨额的营销资金。
四、展望未来:所有企业都是数据驱动的企业,AB测试不可或缺
动荡时代最大的危险不是动荡本身,而是仍然用过去的逻辑做事。——彼得·德鲁克
我们知道数据驱动这个概念。
如今,越来越多的企业正在积极拥抱数据驱动,希望通过数据技术来帮助业务做好科学决策
展望未来,在数字化转型的大背景下,所有企业都将会变成数据驱动的企业,AB测试也将会成为数据驱动下的一种“标配”,驱动企业科学增长。
一个社会的发明创新力是生产率的主要驱动因素。创新和商业精神是经济繁荣的命脉。
AB测试让大胆创新快速试错成为可能,能够激发创新,提升收益。改良、发明、发现和从失败中吸取教训的动力使人们不断学习,发现新的、更好的方法,创造有价值的东西。通过科学的AB测试,我们可以确保每个决策都能带来正向收益,实现复利效应,实现正向循环的可持续增长。