




1、什么时候需要JVM调优
- 应用系统慢(响应性能下降,吞吐量下降)、卡顿(GC停顿时间长、次数频繁)
- 应用出现OOM等内存异常(使用的堆内存过大、本地缓存过大;会发生OOM的区域:堆、元空间、虚拟机栈、本地方法栈、直接内存)
2、JVM调优的原则
JVM调优是一种手段,但并不一定所有问题都需要通过JVM调优解决,最有效的优化手段是架构和代码层面的优化。所以JVM优化是最后不得已的手段,在架构调优和代码调优后对服务器配置的最后一次"压榨"。
JVM调优应遵守的原则:
- 上线之前应先将机器的JVM参数设置到最优;
- 大多数的Java应用不需要进行JVM优化;
- 大多数导致GC问题的原因是代码层面的问题导致的(代码层面);
- 减少创建对象的数量、减少使用全局变量和大对象(代码层面);
- 优先架构调优和代码调优,JVM优化是不得已的手段(代码、架构层面);
- 分析GC情况优化代码比优化JVM参数更好(代码层面);
3、JVM调优目的
- 吞吐量:用户代码运行时间 / (用户代码运行时间 + GC时间)
- 响应时间:STW越短,响应时间越好
官方Java参数文档:https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html
Hot Spot JVM调优参数区分大小写,参数分类:
- 标准参数:- 开头,所有的Hot Spot都支持;
- 非标准参数:-X 开头,特定版本的Hot Spot支持的特定命令;
- 不稳定参数:-XX 开头,下个版本可能取消;
输入:Java -X 查看非标准参数
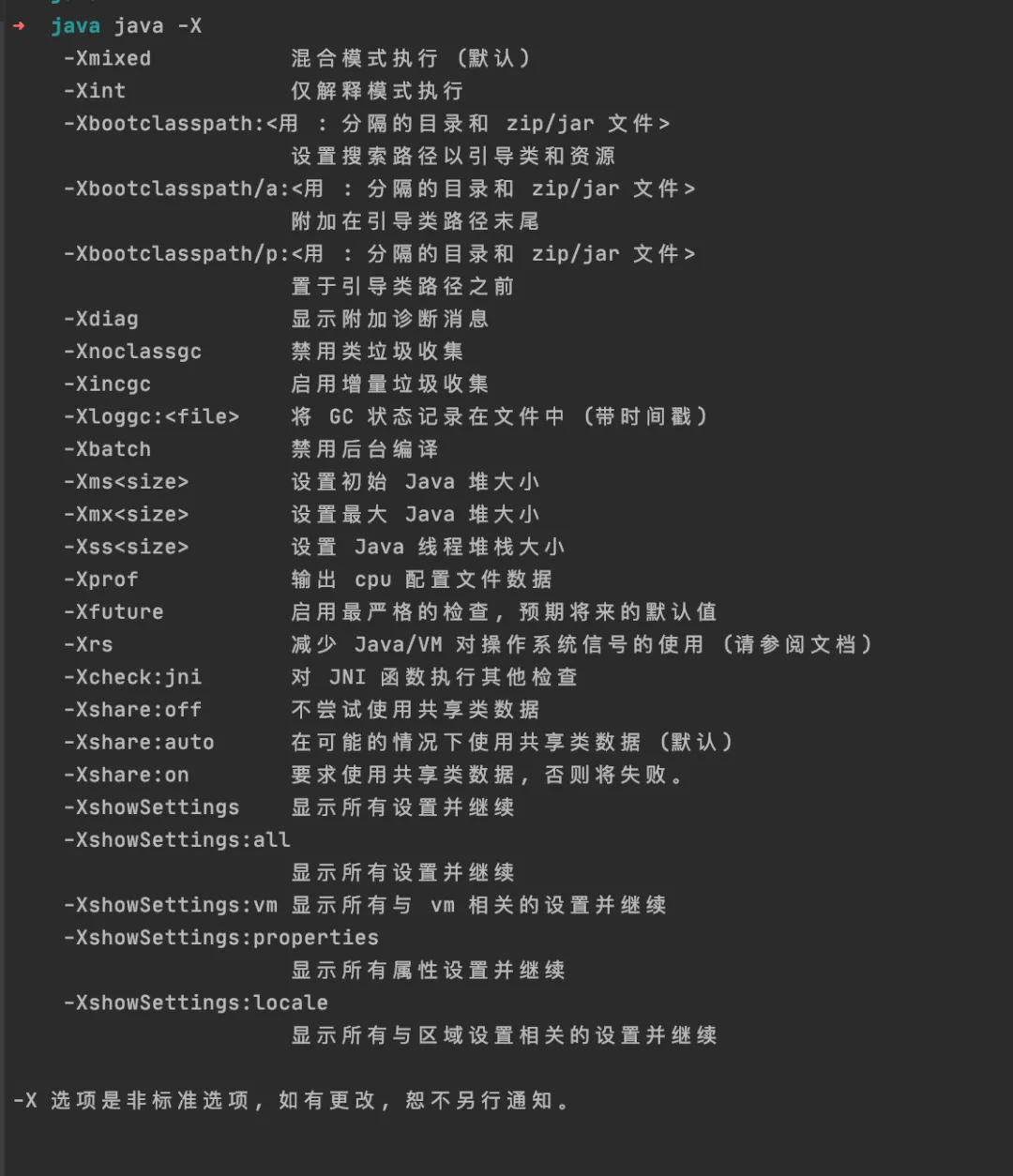
输入:Java -XX:+PrintFlagsInitial 查看默认参数及值
输入:Java -XX:+PrintFlagsFinal 查看最终生效参数及值
输入:Java -XX:+PrintCommandLineFlags 查看启动时的命令行参数
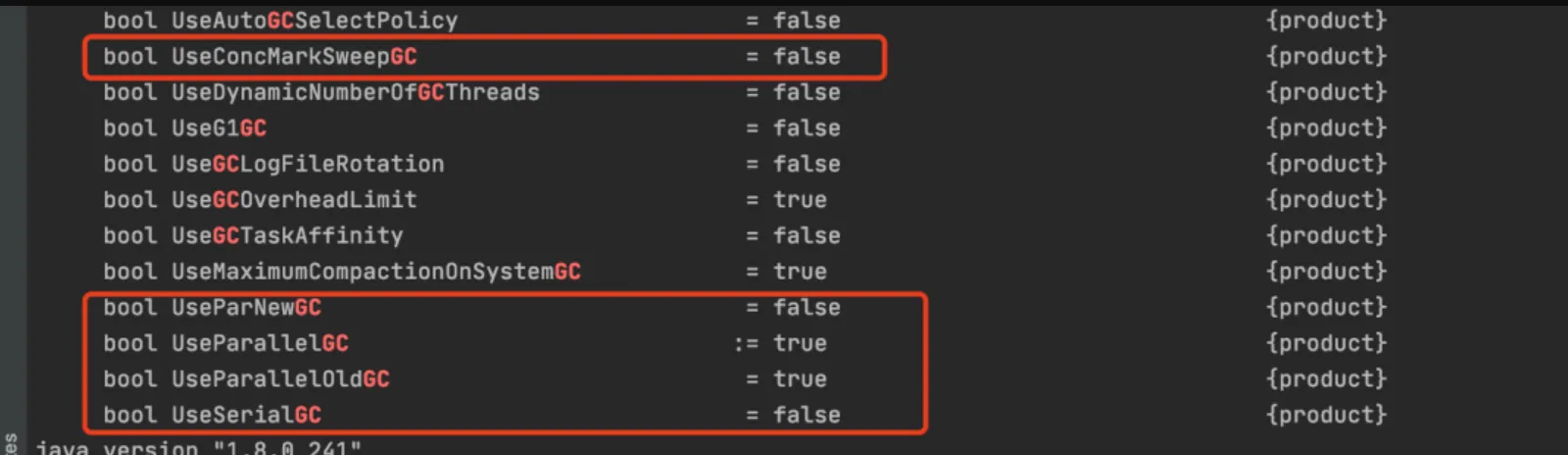
JVM垃圾回收器使用配置:
- -XX:+UseSerialGC:新生代使用Serial,老年代使用Serial Old;
- -XX:+UseParallelGC/-XX:UseParallelOldGC:新生代使用Parallel Scavenge,老年代使用Parallel Old
- -XX:+UseParNewGC:新生代使用ParNew,老年代自动使用Serial Old;
- -XX:+UseConMarkSweepGC:新生代使用ParNew,老年代使用CMS + Serial Old;
- -XX:+UseG1GC:使用G1;
JDK1.8server模式下,默认使用PS+PO收集器。
2、GC常用参数
- -Xms:设置堆的初识内存大小,包含年轻代和老年代,JVM内存设置默认单位为Byte,也可以用k/K、m/M、g/G来声明其他单位。
- -Xmx:设置堆的最大内存大小,-Xms和-Xmx一样时,可以避免内存不够时动态调整内存带来的内存波动
- -Xmn:设置年轻代大小,包括Eden区和
- -Xss:设置线程最大栈空间,JDK5以后每个线程堆栈大小为1M,直接决定了函数可调用的最大深度。在相同物理内存下,减小这个值能生成更多的线程,但一个进程内的线程是有限的,也不是越多效率越高,经验值在3000~5000左右。
- -XX:MetaspaceSize:设置方法区(元空间)初始值,可动态扩展,如果没有设置元空间的上限那么他可以扩大到整个内存。64位的JVM元空间默认大小是21M,达到该值就会FGC,同时收集器会对该值进行调整,如果释放了大量的空间,就适当降低该值;如果释放了很少的空间,提升该值,但最到不超过-XX:MaxMetaspaceSize设置的值。
- -XX:MaxMetaspaceSize:设置方法区(元空间)最大值,如图默认为18446744073709547520接近无限大,也有说默认是-1,即不限制,受限于本地内存。8G内存的机器,初始和最大值一般都设置为256M或者512M。
- -XX:+UseTLAB:打开本地线程分配缓存区(Thread Local Allocation Buffer),用于线程上新对象的分配,默认是打开的
- -XX:+PrintTLAB:打印TLAB的使用情况
- -XX:TLABSize:设置TLAB的大小-XX:TLABSize=256k
- -XX:+DisableExplictGC:屏蔽代码显示调用GC,如System.gc()
- -XX:CompileThreshold:JIT热点代码编译的阀值
- -XX:+PrintGC:打印简单的GC日志信息
- -XX:+PrintGCDetails:打印详细的GC日志信息,不同垃圾回收器的GC信息格式不一样,同一垃圾回收器不同版本JDK也可能不一样
- -XX:+PrintHeapAtGC:每次GC前/后堆内存的使用情况,已经FGC次数(full 0)
- -XX:+PrintGCTimeStamps:打印进程启动到现在GC所运行的时间
- -XX:+PrintGCApplicationConcurrentTime:打印上次GC后停顿到现在过去了多少时间,当GC后时间置为0
- -XX:+PrintGCApplicationStoppedTime:打印GC时应用停顿的时间
- -XX:+PrintReferenceGC:打印强、软、弱、虚引用各个引用的数量以及时长
- -verbose:class:打印类加载情况
- -XX:+PrintVMOptions
- -XX:PreBlockSpin:设置锁自旋次数
3、Parallel常用参数
- -XX:SurvivorRatio=n:设置年轻代中Eden区和Survivor的比例,为Eden: S0: S1 = n:1:1
- -XX:NewRatio=n:设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。设置为n,则年轻代与年老代的比值为1 : n;
- -XX:PreTenureSizeThreshold:设置判定大对象的内存大小,大于该值直接进入老年代,只对Serial和ParNew两款新生代收集器有效
- -XX:MaxTenuringThreshold:对象进入老年代的年龄,默认为15。设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。设置值大,可以让增加对象在年轻代的停留时间,增加对象在年轻代回收的概率。
- -XX:ParallelGCThreads=n:配置并行收集器的垃圾收集线程数,即:同时多少个线程一起进行垃圾回收。
- -XX:+UseAdaptiveSizePolicy:自动选择堆内各区大小的比例
4、CMS常用参数
- -XX:UseConcMarkSweepGC
- -XX:ParallelCMSThreads:CMS线程数量
- -XX:CMSInitiatingOccupancyFraction:老年代使用内存回收阈值,超过该阀值后开始CMS收集,默认是68%。
- -XX:+UseCMSCompactAtFullCollection:在FGC时压缩整理内存
- -XX:CMSFullGCsBeforeCompaction:多少次FGC之后进行压缩整理
- -XX:+CMSClassUnloadingEnabled:使用CMS回收Perm区需要卸载的类
- -XX:CMSInitiatingPermOccupancyFraction:达到什么比例时进行Perm回收
- -XX:GCTimeRatio:设置GC时间占用程序运行时间的百分比,建议比例,CMS会根据这个值调整堆空间
- -XX:MaxGCPauseMillis:GC停顿建议时间,GC会尝试各种手段达到这个时间,比如减少年轻代
5、G1常用参数
G1调优官方文档:Garbage First Garbage Collector Tuning | Oracle 中国
- -XX:+UseG1GC:使用G1垃圾收集器
- -XX:ParallelGCThreads:知道垃圾收集线程数
- -XX:+G1HeapRegionSize:指定分区大小(1M~32M,必须是2的N次幂),建议逐渐增大该值。随着size增加,垃圾存活时间更长,GC间隔更长,每次GC时间也会变长
- -XX:MaxGCPauseMillis:最大GC停顿时间建议值,G1会尝试调整Young区的块数来达到这个值,
- -XX:GCPauseIntervalMillis:GC的间隔时间
- -XX:G1NewSizePercent:新生代初识内存空间比例,默认堆的5%
- -XX:G1MaxNewSizePercent:新生代最大内存空间比例,默认60%
- -XX:GCTimeRatio:设置GC时间占用程序运行时间的百分比,建议比例,G1会根据这个值调整堆空间
- -XX:ConcGCThreads:并发线程数
- -XX:InitiatingHeapOccupancyPercent:设置触发GC标记周期的 Java 堆占用率阈值。默认占用率是整个 Java 堆的 45%。
可视化信息
1、CPU和内存的监控
Linux可使用top命令实时显示系统中进程的资源占用状况,
top:可以观察哪个进程PID的CPU和内存过高。
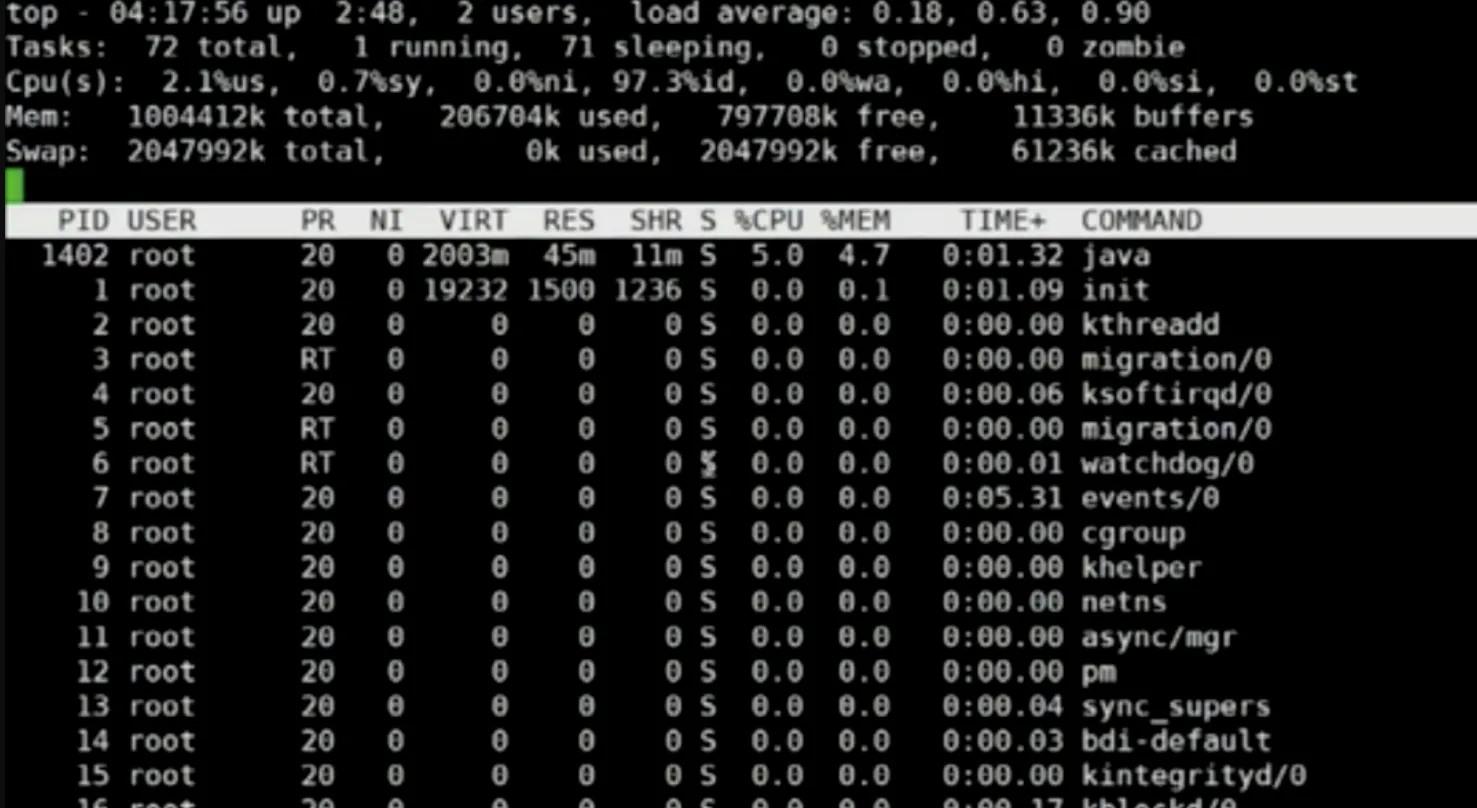
top -Hp PID:可以观察进程中的线程,哪个线程CPU和内存占比高。
一般公司有自己的可视化的监控告警平台。
2、Jconsole 和 JVisualVM图形工具
都是Java提供的观察JVM资源消耗和性能进行监控的可视化界面工具,可在JDK/bin目录下启动;JVisualVM是JDK6以后带上的工具,相当于升级版的Jconsole。(还有更好的 图形工具,收费的Jprofiler)
一般只用于本地测试 ,不用于在线系统的监控和定位:
- 远程连接监控需要虚拟机启动时开放端口供远程连接,增加不安全性
- 对JVM产生一些负载,增加在线系统的负载
Jconsole如下:
- 可以观测内存、线程、类的占用空间量
- 可以远程可视化监控服务器的Java进程
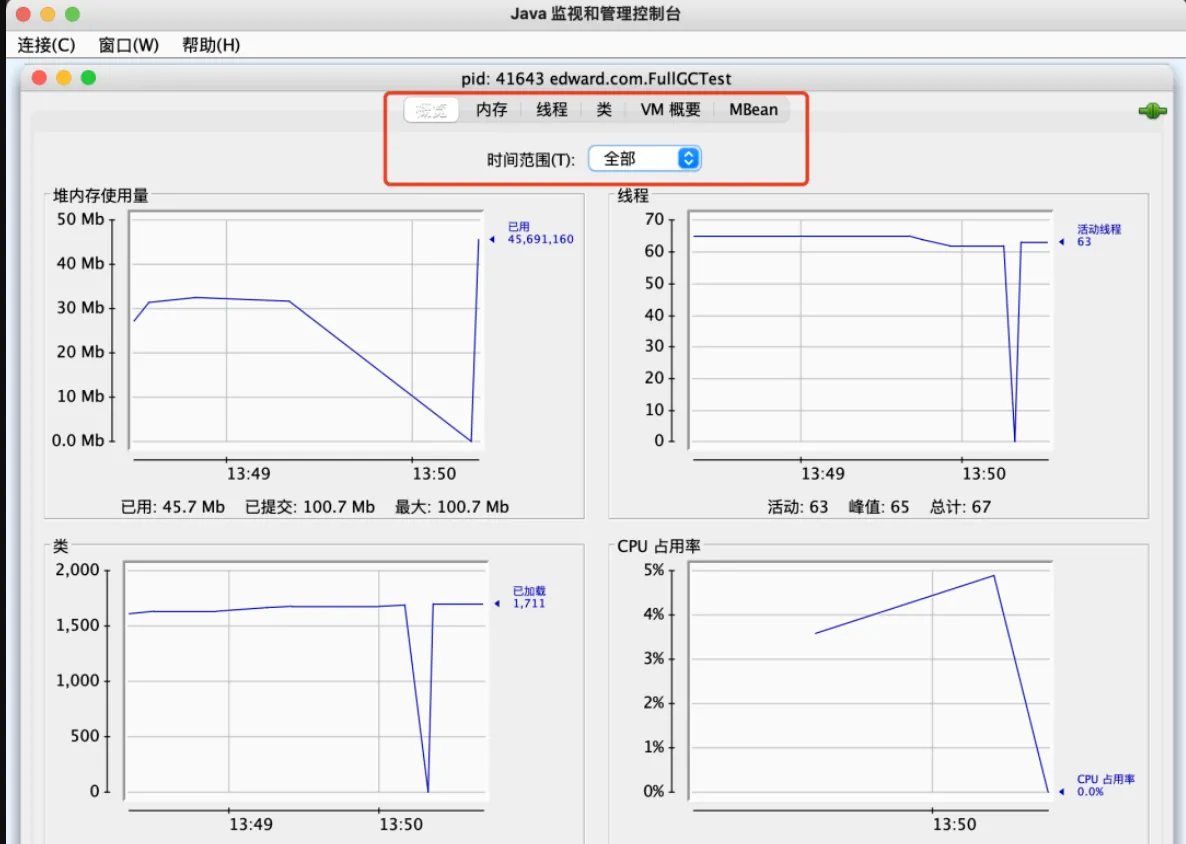
JVisualVM如下:
- 监控应用程序的性能和内存详细占用情况
- 进行线程转储(Thread Dump)或堆转储(Heap Dump)、跟踪内存泄漏、监控垃圾回收器、执行内存和CPU分析,保存快照以便脱机分析应用程序
- 也支持远程访问
- 安装插件可以变成多面手
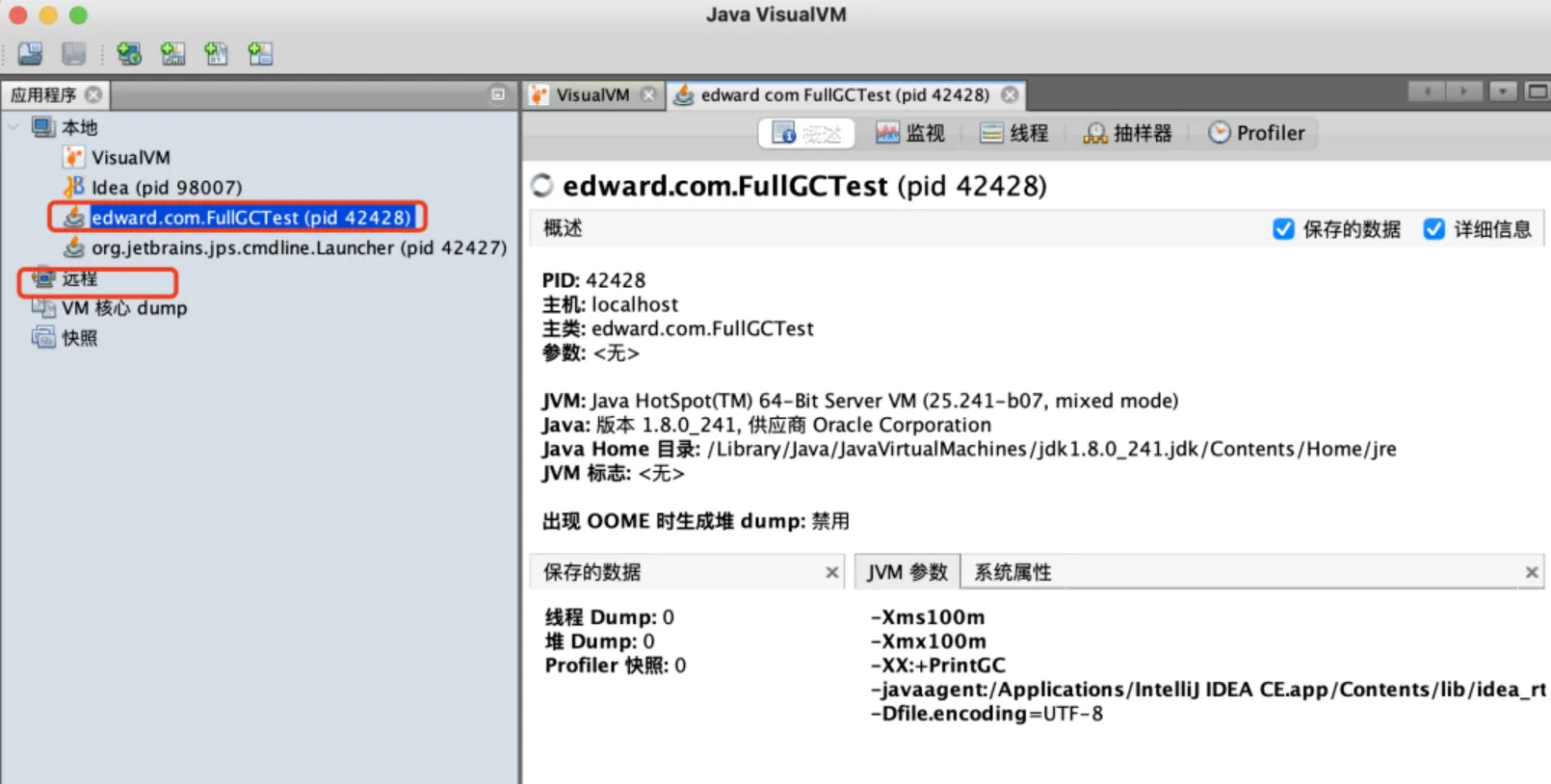
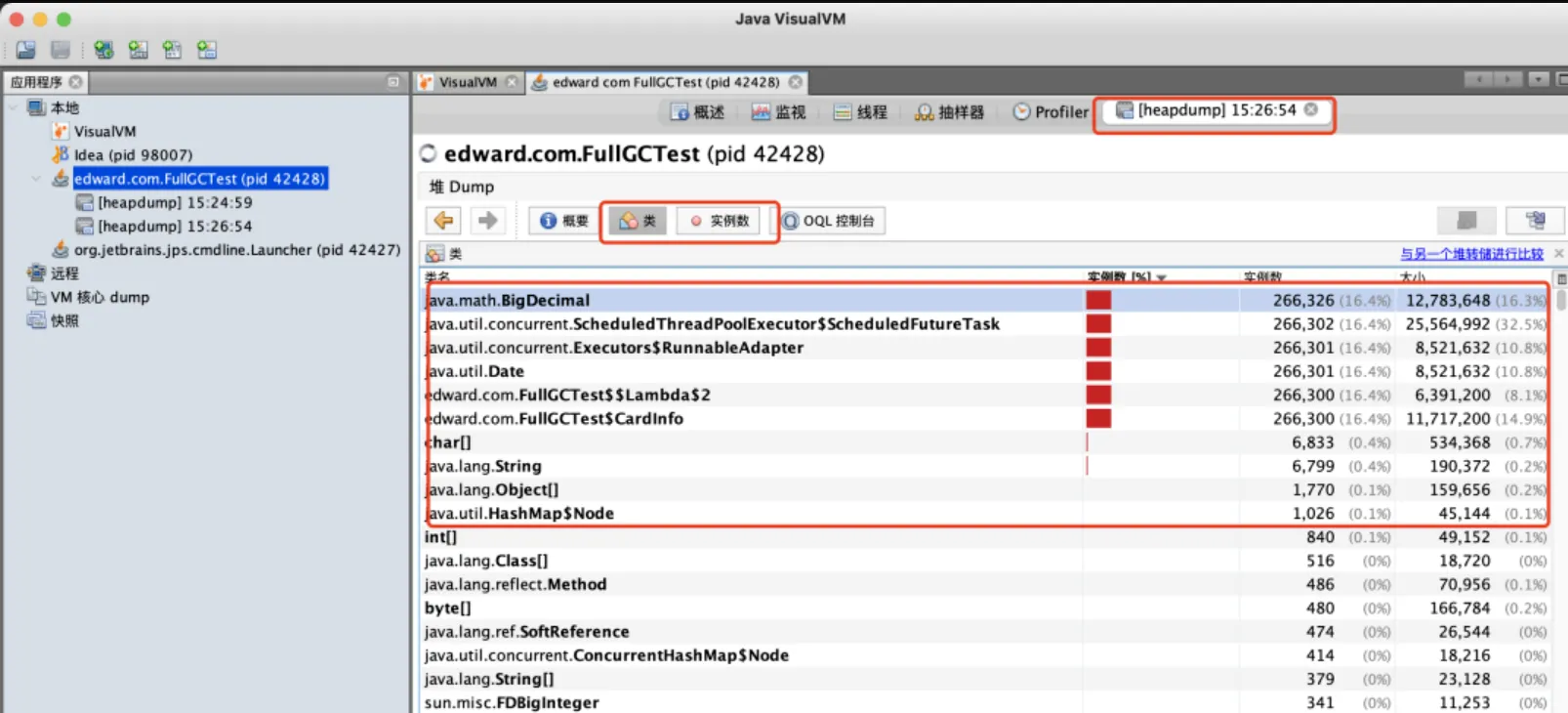
分析HeapDump文件,类实例个数详细信息分析
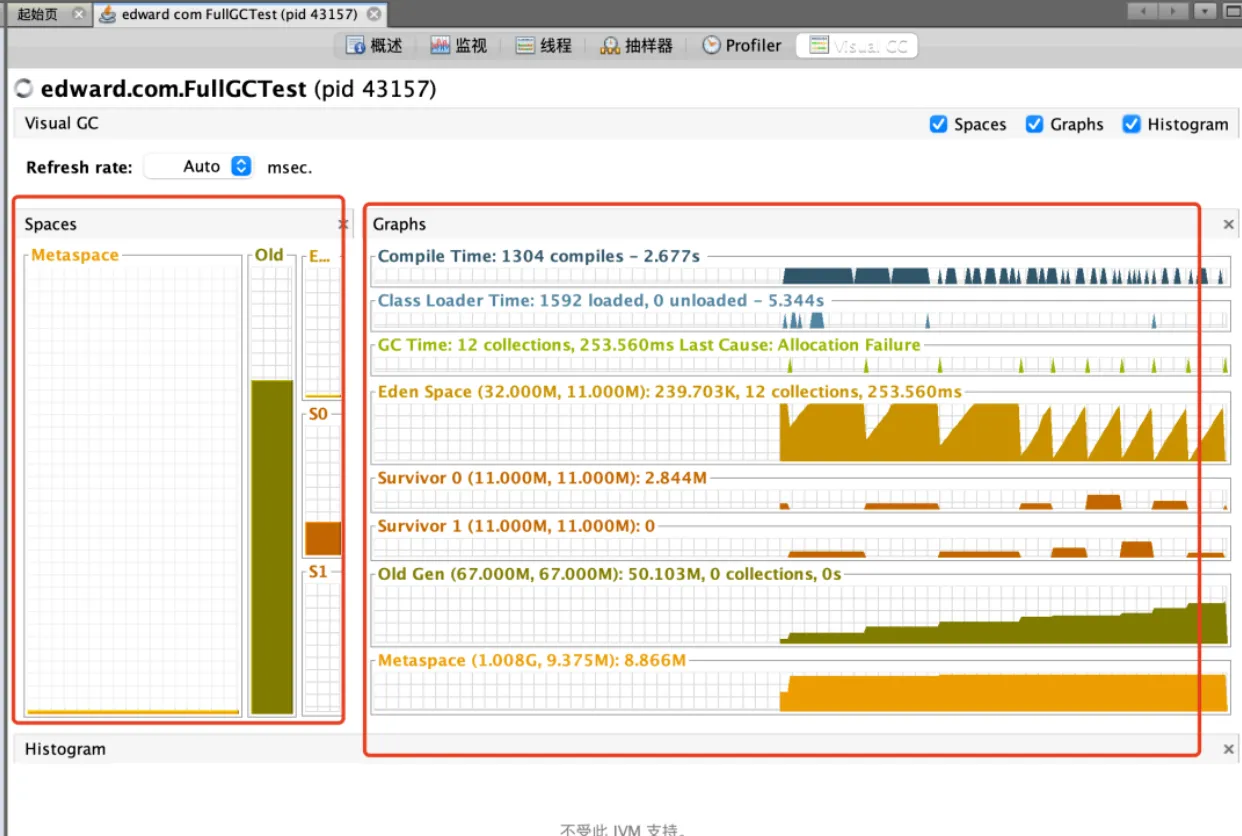
工具 -> 插件 -> 安装Visual GC插件,Jvisualvm内工具可以直接安装。
- spaces区域:虚拟机各区内存空间分布情况
- Graphs区域:编译时间、类加载时间、GC、各区内存等变化图形
- histogram:显示survivor区域各年龄层的对象
安装不上可以通过官方插件地址下载插入VisualVM: Plugins Centers,然后载入后缀.nbm的文件。
3、Java命令行工具
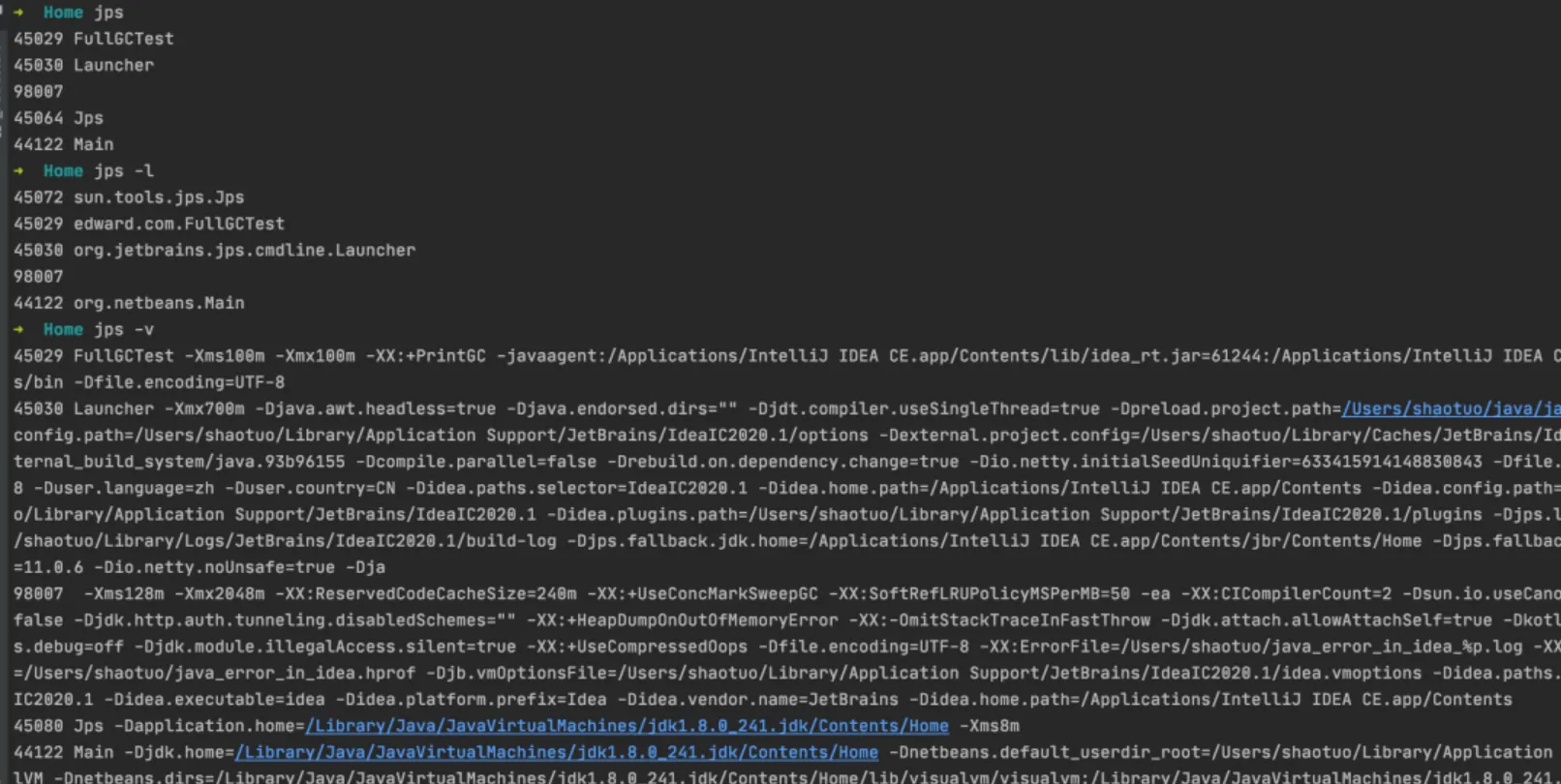
jps:列出Java进程信息,PID、启动方法
jps [ options ] [ hostid ]jps -q : 禁止输出main方法的类或者jar文件的名称和参数jps -m : 输出main方法的参数,JVM自带参数不会输出jps -l : 输出应用主类的完整包路径名称或者jar文件的全路径名称
jinfo:输出JVM一些信息
jinfo -flags pid : 输出JVM的全部参数jinfo -sysprops pid : 输出系统的全部参数
jstat:输出JVM虚拟机的性能统计信息,比如GC、内存大小、编译时间等
jstat [ generalOption | outputOptions pid [interval[s|ms] [count]] ]jstat -class : 类加载行为的统计信息jstat -compiler : 即时编译热点行为的统计jstat -gc : JVM中堆的垃圾收集情况的统计jstat -gccapacity : 显示各个代的容量以及使用情况

jstack:列出线程信息,观察线程状态和调用方法堆栈信息,重点关注WAITING BLOCKED状态
jstack pid : 列出当前进程的各个线程信息jstack pid > /Users/shaotuo/threadDump.txt : 生成Thread dump 文件,> 后面为dump的path
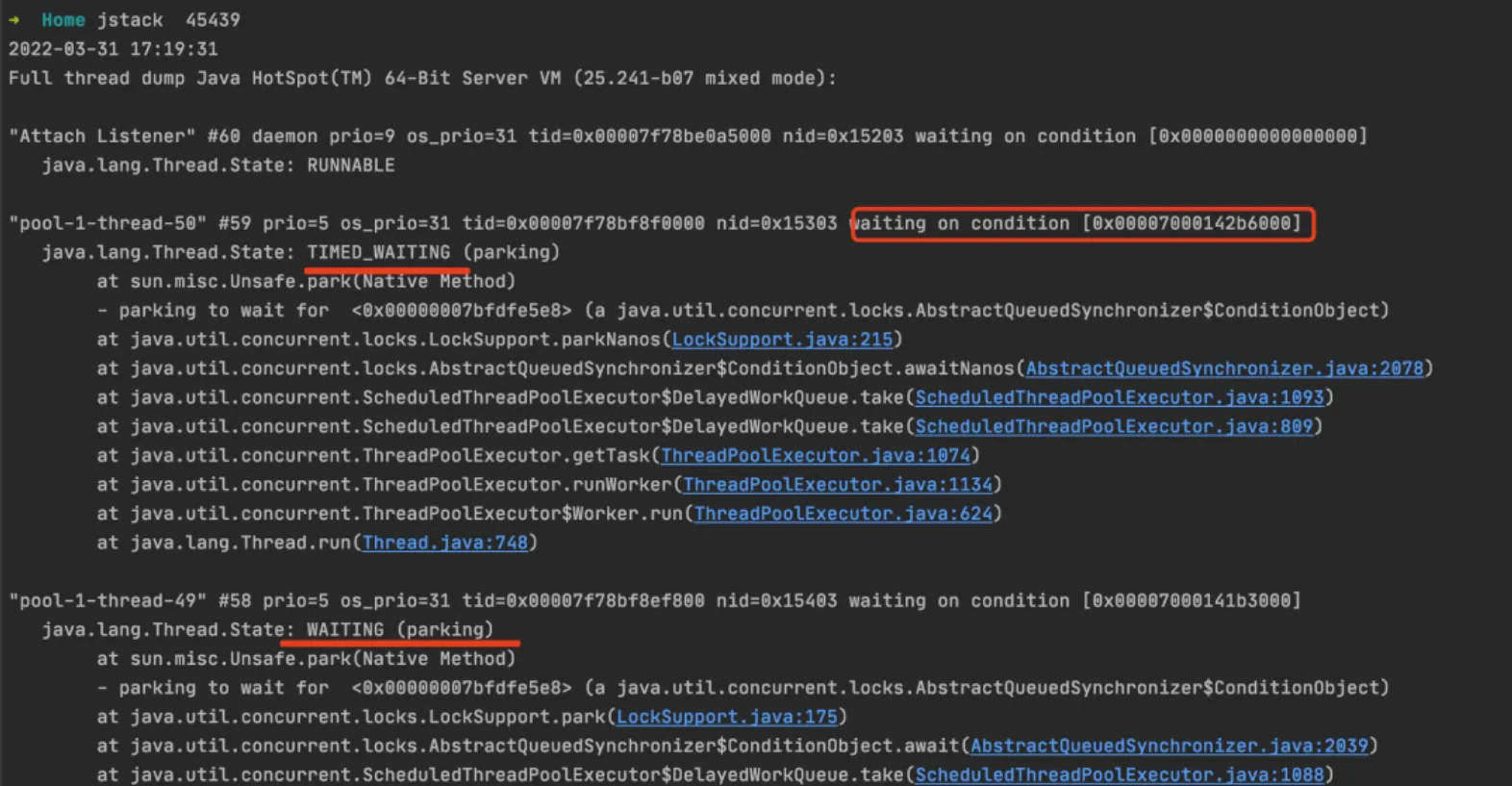
- Thread dump文件主要保存java应用中各线程在某一时刻的运行的位置,即执行到哪一个类的哪一个方法哪一个行上
- Thread dump是一个文本文件,打开后可以看到每一个线程的执行栈
- Thread dump可分析应用是否“卡”在某一点上,即在某一点运行的时间太长,如数据库查询,长期得不到响应,最终导致系统崩溃
- 单个的Thread dump文件一般来说是没什么用,因为它只是记录某一绝对时间点的情况。比较有用的是,线程在一个时间段内的执行情况。
- Jvisualvm也可以Thread dump。
- 当多个线程都处于WAITING状态waiting on xxx时, 可以确认是不是某一个线程长时间占用某把锁,通过搜索Thread dump文件中的RUNNABLE线程,进行问题排查。
- 创建线程或线程池时要指定有意义的线程名称,有利于出错时快速定位!。
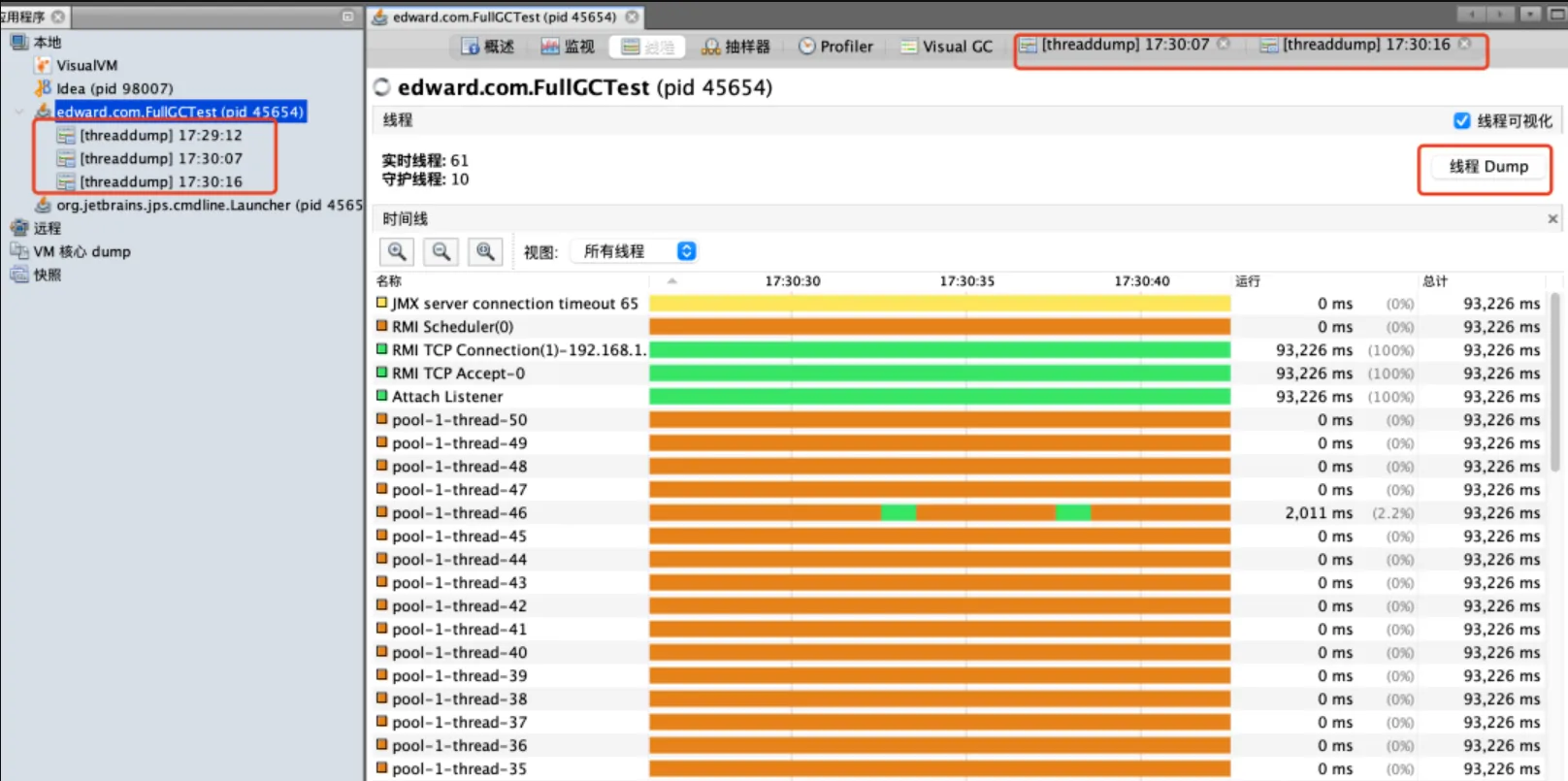
Thread dump常用来解决的问题类型:
- 高CPU
- 线程死锁
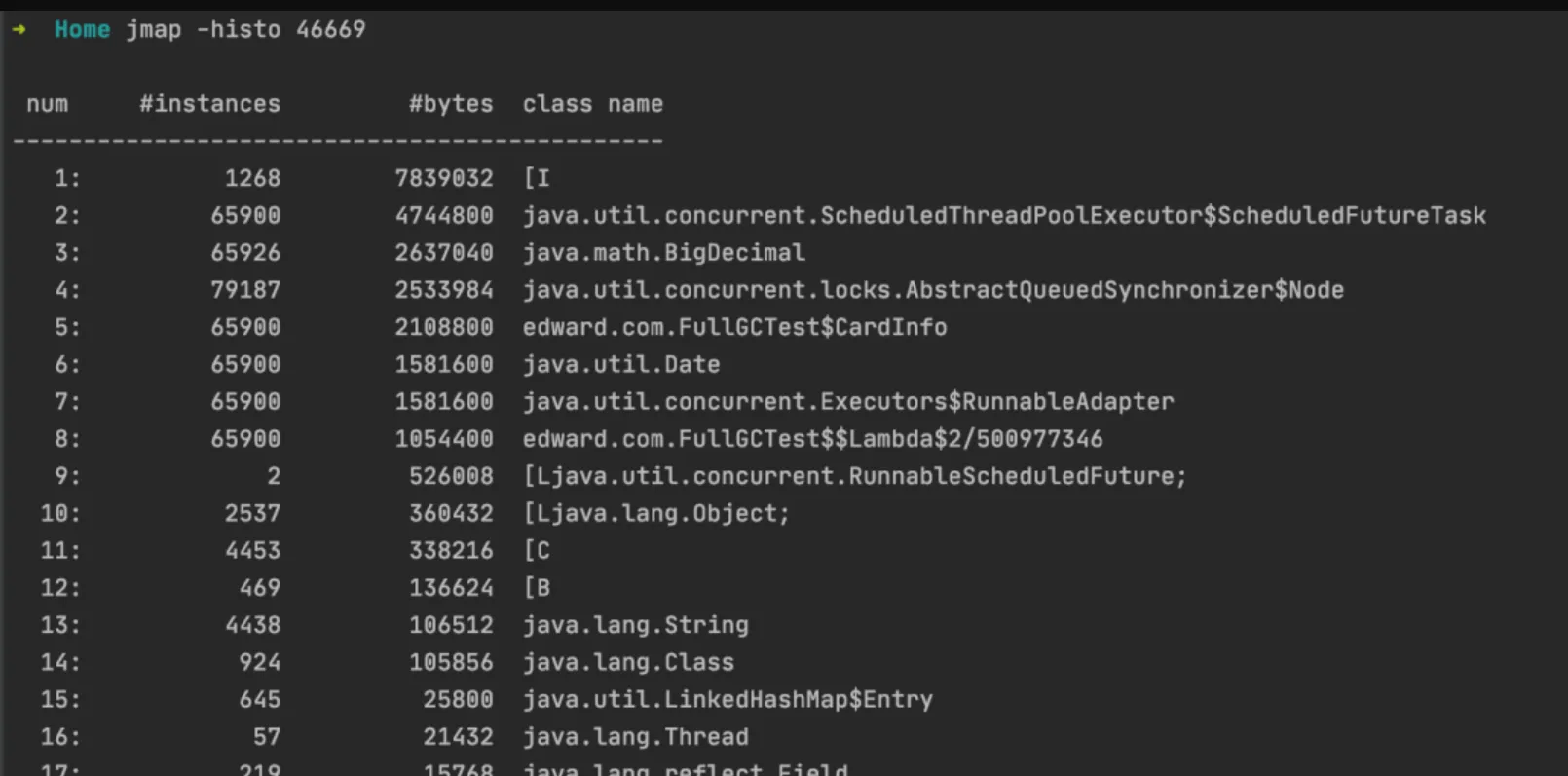
jmap:列表指定java进程的堆内存信息,对象的统计信息、ClassLoader的信息,可以使用jmap生成Heap dump文件
- java -histo pid:显示堆中对象的统计信息,内存占用,类全名信息,VM的内部类名字开头会加上前缀"*“”;
- java -histo:live pid :live子参数加上后,只统计活的对象数量。执行这个命令,JVM会先触发GC,然后再统计信息。
- jmap -dump:live,format=b,file=a.log pid:内存信息dump到a.log文件中,堆内存比较大,会导致这个过程比较耗时,并且执行的过程中为了保证dump的信息是可靠的,所以会暂停应用。线上不能生产dump文件。
- 通常用来分析内存泄漏OOM,JVM启动配置OOM时自动生成Dump文件-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path。
4、阿里arthas监测工具的使用
dashboard、jad、redefine
相关问题
公司一般有相应的监控平台,对应重要指标的监控,如CPU、内存、GC|FGC、线程池、数据库连接池、Redis、日志信息等,当有指标异常时会有相应的告警通知,来即时发现问题。
1、JVM层面:Java高CPU占用排查步骤
1、top命令找到占用CPU高的进程PID;
2、jstack PID > threadDump.txt 导出当前进程的dump文体,各线程的状态信息;
3、top -Hp PID:找出PID的进程占用CPU过高的线程tid,或者使用命令ps -mp PID -o THREAD,tid,time命令查看线程列表;其中TID列表显示的十进制线程编号。
4、 printf “%x\n” TID:将10进制的tidD转为16进制tid,因为dump文件中的线程ID是16进制的;

5、less threadDump.txt:查找转换成为16进制的线程tid,找到对应的线程调用栈分析问题。
或者通过jstack PID > threadDump.txt | grep TID -A 30 (-A打印匹配行的后30行)
1、top2、jstack 1212 > threadDump.txt3、top -Hp 1212 或者 ps -mp 1212 -o THREAD,tid,time4、printf “%x\n” 288025、less threadDump.txt 或者 jstack 1212 > threadDump.txt | grep 7082 -A 30
grep命令:linux之grep使用技巧
less、cat、more命令:Linux浏览文件命令:cat、less、more详解!
2、线上CPU飙高的定位:
- 根据告警,查看监控、日志,找到出现问题的时间点;
- 确认是部分容器还是所有容器的CPU都飙高;
- 确认时持续性的还是间接性的,如果是部分容器间接性可能是因为网络抖动的原因;
- 如果是持续性的,大面积的,查看日志是否有错误、确认是否有上线版本;
- (jstat -gcutil 命令监控当前系统的GC状况)
- 一般是GC线程频繁GC问题,确认相关错误日志,定位代码
- 否则只能通过jmap dump:format=b,file= 导出系统当前堆的内存数据,分析哪些对象在消耗内存,来定位代码
- 查看超时日志,下游接口调用超时或耗时长,不定时出现;确认是否吻合,因为线程阻塞住,需要处理的线程数堆积越来越多,所以CPU会飙高。
- 查看错误日志,是否某个功能停滞阻塞,线程死锁阻塞其他线程,检查产生死锁的两个线程的具体阻塞点,死锁会导致CPU占用率过高,也可通过jstack查看该线程的堆栈信息。
- 一般可以通过日志查看到和GC频率来确认,有用户线程的错误日志无GC,则直接定位业务线程代码;有业务线程的错误且GC频繁,则可能是代码问题导致GC;
- 业务线程的问题:
- VM线程频繁GC导致CPU过高:
- 如果找不到问题代码,高可用但架构可以隔离部分机器,在线定位,流量复制、流量回放重复进行问题重现和压测,这样不影响在线机器就可以通过远程工具观察JVM的内存情况。
死锁排查:线上服务器cpu占用过高、程序死锁,该如何排查问题?
一般通过日志分析就能定位代码不用JVM相关命令查看。
3、OOM日志的错误,怎么排查?
确认内存溢出的原因:
- java.lang.OutOfMemoryError:…java heap space…
- 堆栈溢出,代码问题可能性很大;
- 线程池运用不当OOM,不断往list加对象,导致回收不了;
- 重写finalize引发频繁GC:finalize方法内会拯救对象,导致对象不被回收;重写finalize但不拯救 ,也会将对象推到F-Queue队列,等待下次GC才回收;
- java.lang.OutOfMemoryError:GC over head limit exceeded
- 系统处于高频GC状态,且回收效果作用不大;有可能内存不够导致,某引用使用不当,导致不能被回收
- java.lang.OutOfMemoryError: Direct buffer memory
- 直接内存不够,JVM不会回收直接内存,查看是否是使用ByteBuffer.allocateDirect方法,没有clear导致;一般为使用NIO的问题
- java.lang.OutOfMemoryError: unable to create new native thread
- 堆外内存不够,导致无法为线程分配内存
- java.lang.OutOfMemoryError: request {} byte for {} out of swap
- 地址空间不够
- java.lang.StackOverflowError
- 线程栈溢出,由-Xss控制线程栈大小,一般是代码里面循环调用的问题