




尽管 ChatGPT 像是一颗核弹,突然在全世界媒体上引爆了。但是,ChatGPT 并不是 OpenAI 天降神力直接横空出世的,而是 OpenAI 历经多年,不断迭代、不断优化模型的结果。
GPT 是 OpenAI 发布的一系列模型的总称。主要经历了 GPT 初代、GPT2.0、GPT3.0、GPT3.5、ChatGPT,目前已经有了 GPT4,未来还会有 GPT-n 等等,模型之间有很强的关联。这几个模型的关系如下图所示:
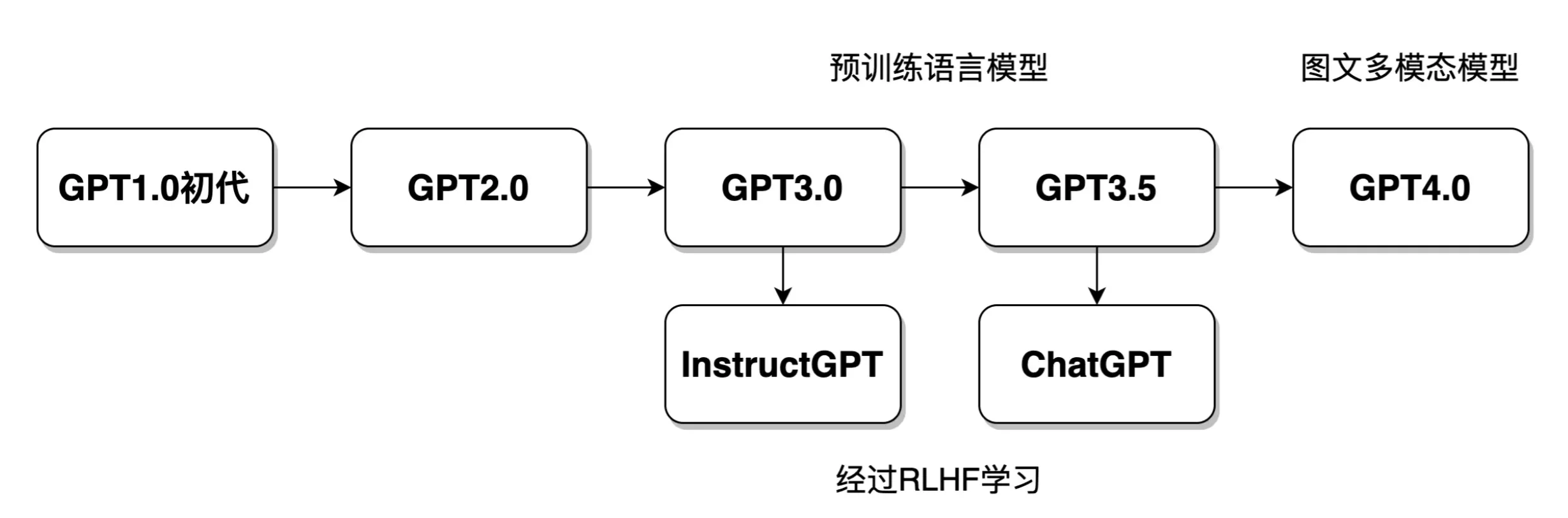
ChatGPT 中的很多技术点,都是由前几代模型设计并运用的,学习 ChatGPT 技术原理,势必要学习了解早期 GPT 模型的发展脉络。若把 ChatGPT 比作一个健康聪明的青年人,那么早期的模型就是他的婴儿时期、青少年时期,GPT 的发展历程像是朝着模拟人类发展。
GPT 初代
早在 2017 年,OpenAI 制作了一个名为 GPT 的模型,也就是 ChatGPT 的婴儿阶段。这个 GPT 初代模型,在很多 NLP 的具体任务中取得了前所未有的优质效果。 它与谷歌发布的 Bert 模型(比 GPT 初代更加流行,效果更好),还有 ELMO 模型,一起将 NLP 带进了大规模神经网络语言模型(Large Language Model, LLM)时代。它们正式标志着 NLP 领域开始全面拥抱预训练的方式。
GPT 的语言建模
这个 GPT 初代模型具体做了什么,可以用下面的例子来说明:
请各位做一个句子补全:中国互联网 BAT 三巨头主要包括阿里、腾讯、________
请问上述空格应该补写什么?有的人回答“百度”,有的人可能觉得“字节”也没错。但总不再可能是别的字了,不论填什么,这里都表明,空格处填什么字,是受上下文决定和影响的。
GPT 初代所做的事就类似上文的例子,从大规模的文本语料中,将每一条文本随机地分成两部分,只保留上半部分,让模型学习下半部分学习到底该填写什么,这种学习方法让模型具备了在当时看来非常强的智能。所谓语言模型(Language Model,LM),就是从大量的数据中学习复杂的上下文联系(语言模型的详解将在第 3 节中展开)。
语言模型的编解码
上述语言建模包含一条输入和一条输出。接下来,我们仔细想一个问题:
人的大脑是由上百亿个神经元有机构成的,当人看到一段文字之后,是如何转化相应的信息,存储在大脑中的呢?当人们脑海中形成一个想法或观点后,是如何转换相应的信息,通过语言文字表达出来的呢?
语言是一个显式存在的东西,但大脑是如何将语言进行理解、转化和存储的,则是一个目前仍未探明的东西。这个问题实际上表达了一个人脑运用语言的特点:人脑并不直接存储文字,而是将文字编码成某种神经元信号,再经过解码,形成想要表达的文字,表述出来。
编解码的概念广泛应用于各个领域,在 NLP 领域,模型操控语言一般包括三个步骤:
人的大脑理解 -> 输出要说的语言。
大脑理解语言这个过程,就是大脑将语言编码成一种可理解、可存储形式的过程,这个过程就叫做语言的编码( E ncoder) 。相应地,把大脑中想要表达的内容,使用语言表达出来,就叫做语言的解码( D ecoder) 。
GPT 系列模型都采用了类似的结构工作,如下图所示。
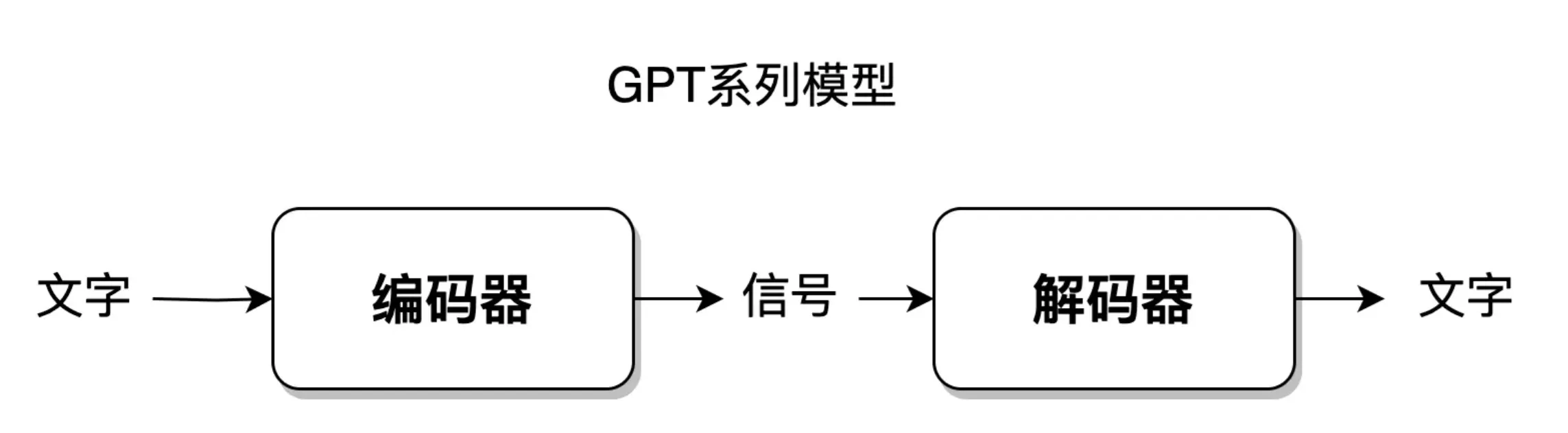
编解码具体结构介绍将在第 7 节展开。
GPT-2
自从 GPT 初代 和 Bert 模型开启大语言模型预训练大门之后,跟风效仿的改进模型也越来越多,比如 albert、ERNIE、BART、XLNET、T5 等等五花八门。
最初的时候,GPT 的学习方式仅仅是根据上文补全下文,就可以让模型有较强的智能。那么,给 LLM 模型出其它的语言题型,应该也会对模型训练有极大的帮助。
出语言题型就太简单了,英语考试里有的题型都可以拿过来,什么句子打乱顺序再排序、选择题、判断题、问答题、寻找文中的错别字、把预测单字改成预测实体词汇等等,都可以制定数据集添加在模型的预训练里。很多论文提出的模型也都是这么干的。
这个过程也和人脑很像,人脑是非常稳定和泛化的。所谓泛化,是指举一反三的能力。人脑既可以欣赏诗歌,也可以计算数学,还可以学外语、看新闻、听音乐等等。简而言之,就是一脑多用。
而在 GPT 出现之前的 NLP 任务,文本分类模型就只能分类,市面上的机器翻译软件只能完成翻译这一件事,而且还是限定了只能从中文翻译成英文这一种形式,非常不灵活。
GPT-2 的论文名就叫做【Language Models are Unsupervised Multitask Learners】,语言模型是多任务学习者。
GPT-2 主要就是在 GPT 初代的基础上,又添加了多个任务,比如机器翻译、问答、文本摘要等等,扩增了数据集和模型参数,又训练了一番。训练效果样例如下图所示,这是一些 GPT2 训练得到的结果,输入左边的问题,模型会给出第二列的答案。
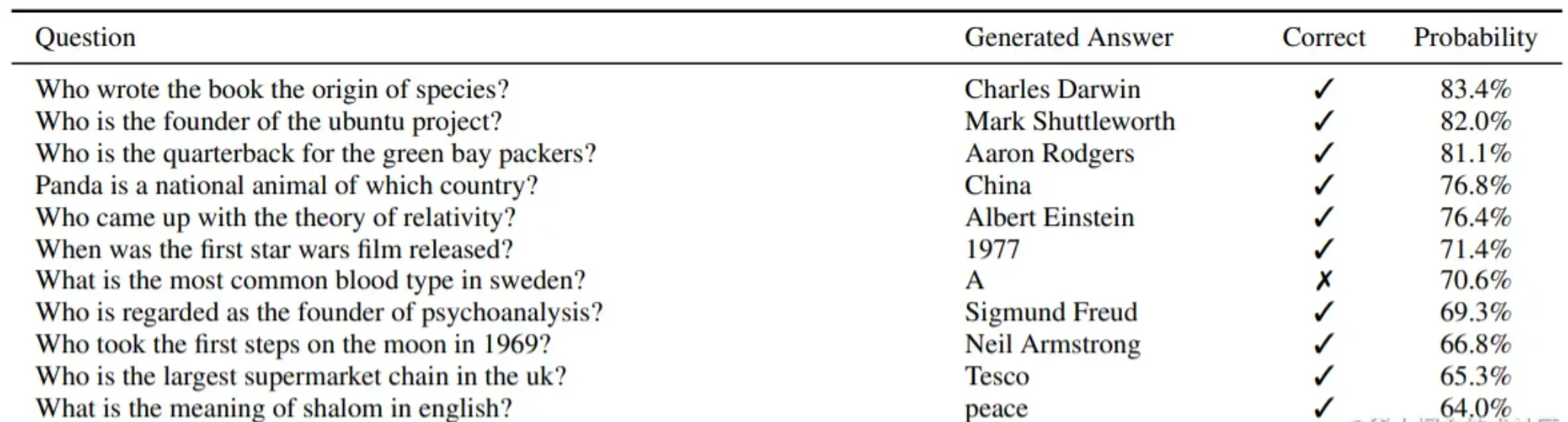
GPT2 中,多个任务都在同一个模型上进行学习。模型能承载的并不仅仅是任务本身,例如一条文本:“太阳距离地球非常遥远”,这条文字包含的信息量是通用的,假设有如下几个任务:
任务1,机器翻译:The sun is so far away from the earth.
任务2,事实判断:似乎一个人乘坐太空飞船,一天就能从地球抵达太阳。
两个任务都用到了相同的信息“太阳距离地球非常遥远”。既可以用于翻译,也可以用于文本分类,判断某些句子的错误等等。也就是说,信息是脱离具体 NLP 任务存在的,举一反三,能够利用这条信息,在每一个 NLP 任务上都表现好,这个是元学习(meta-learning),实际上就是语言模型的一脑多用。
GPT-3
大模型中的大模型
2020 年,OpenAI 发布了 GPT-3 模型,它所采用的数据量,模型参数量之大,学习之复杂,计算之繁复不说了,看图表吧。
| 模型名 | 模型结构 | 参数量 | 训练数据 |
|---|---|---|---|
| Original GPT (GPT-1) | Transformer decoder (第5节介绍) | 1.17 亿 | 4.5 GB文本 |
| GPT-2 | Transformer + normalization(第6节介绍) | 15 亿 | 40 GB文本 |
| GPT-3 | Sparse Transformer(第6节介绍) | 1750亿 | 570 GB文本 |
GPT-3 里的大模型计算量是 GPT-1 的上千倍。如此巨大的模型造就了 GPT-3 在许多十分困难的 NLP 任务,诸如撰写人类难以判别的文章,甚至在编程语言方面,编写 SQL 查询语句、React 或者 JavaScript 代码上都具有优异的表现。
为什么需要这么大的参数量?从某种角度讲,只有模型参数足够大,才能够体现出复杂的智能。
超大的模型参数量,就好比人类的大脑。
可能人类的大脑中,各个神经元细胞之间的联系、结构,与一只兔子的大脑无明显区别。主要区别在于,人类的大脑具备了 100~200 亿神经元,兔子则只有 5 亿左右神经元细胞。神经元的个数决定了人类具有超高的智能,而兔子只懂得最简单的生存智能。这部分内容将在第 12 节中详细介绍。
对话模式
首先 GPT 系列模型都是采用 decoder 解码器结构进行训练的,也就是更加适合文本生成的形式。即输入一句话,输出也是一句话。这被称之为对话模式。它非常像人类的沟通交流模式。
我们是如何学会中文的?从出生开始,听别人说话,说出自己想说的话,也就是对话。我们每个人都是中文高手。
我们是如何学外语的?看教材、听广播、背单词。唯独缺少了对话! 正是因为缺少了对话这个高效的语言学习方式,所以我们的外语水平才如此难以提高。
对于语言模型,同理。对话是涵盖一切 NLP 任务的终极任务。从此 NLP 不再需要针对特定任务建模这个过程。比如,传统 NLP 里还有序列标注这个任务,需要用到 CRF 这种解码过程;文本分类模型需要给每一个模型打标签;在对话的世界里,这些统统都是冗余的。这部分内容会在第 7 节详细来讲。
小样本(Few-Shot)学习
GPT3 的论文标题叫做【Language Models are Few-Shot Learners】,语言模型是小样本学习者。
以往在训练 NLP 模型的时候,都需要用到大量的标注数据。可是标注数据的成本实在是太高了,这些都得人工手工一个个来标注完成!有没有什么不这么依赖大量标注的方式吗?
GPT3 就提出了小样本学习的概念,简单来讲,就是让模型学习语言时,不需要那么多的样例数据。
假设,我们训练一个可抽取文本中人名的模型,就需要标注千千万万个人名,比如“张雪华”、“刘星宇”等。千千万万个标注数据,就像是教了模型千千万万次同一个题目一样,这样才能掌握。
而人脑却不是这样,当被告知“山下惠子”是一个日本人名以后(仅仅被教学了一次),人脑马上就能理解,“中岛晴子”大概率也是一个日本人名,尽管人脑从来没听说过这个名字。
小样本学习的具体方式,主要放在第 9 节展开来讲,它的实现必然依赖超大规模的语言模型预训练。
ChatGPT
需要说明的是,OpenAI 并没有发表 ChatGPT 模型原理论文,从严格意义上讲,ChatGPT 模型的实现细节,外界是无从知晓的。但是,OpenAI 在2022年发表了一篇 InstructGPT 论文:【Training language models to follow instructions with human feedback】让模型更好地听从人类反馈的指令。这两个模型几乎可以被认为是采用了完全相同的策略。
从此后各个科技公司的模型训练上看,InstructGPT 的原理几乎可以与 ChatGPT 画上等号。
唯二的差别,就是 ChatGPT 是基于 GPT3.5 的,而 InstructGPT 基于 GPT3;并且,ChatGPT 用上了更大更优质的训练文本语料数据。
ChatGPT 模型结构上和之前的几代都没有太大变化,主要变化的是训练策略变了。
强化学习
我们在第 1 节介绍到,ChatGPT 将 NLP 带入了强化学习时代,这是它爆火的关键原因。
训练 ChatGPT 所需要的文本,主要来自于互联网,这是一个有限的集合。而人类对 ChatGPT 提出的问题则无穷无尽,永远没有尽头,人类想要知道、感兴趣的内容,并不一定就存在互联网上。
按照传统的深度神经网络模型的训练思路,它只能根据互联网上已有的数据,做问答对标注,进训练模型。它学习的只是已有的数据本身。
而 ChatGPT 所利用的强化学习的思路,则是模拟一个环境模型(Reward 模型)。 首先,ChatGPT 会针对某一个问题,生成一个回答,环境模型会对 ChatGPT 生成的答案做评价,评价一个分值出来(如 10 分、3 分等等,高分代表奖励,低分代表惩罚),而不具体给出标准答案。ChatGPT 接收到评价反馈后,可以根据这个数值做模型的进一步训练,朝着生成更加恰当答案的方向拟合。
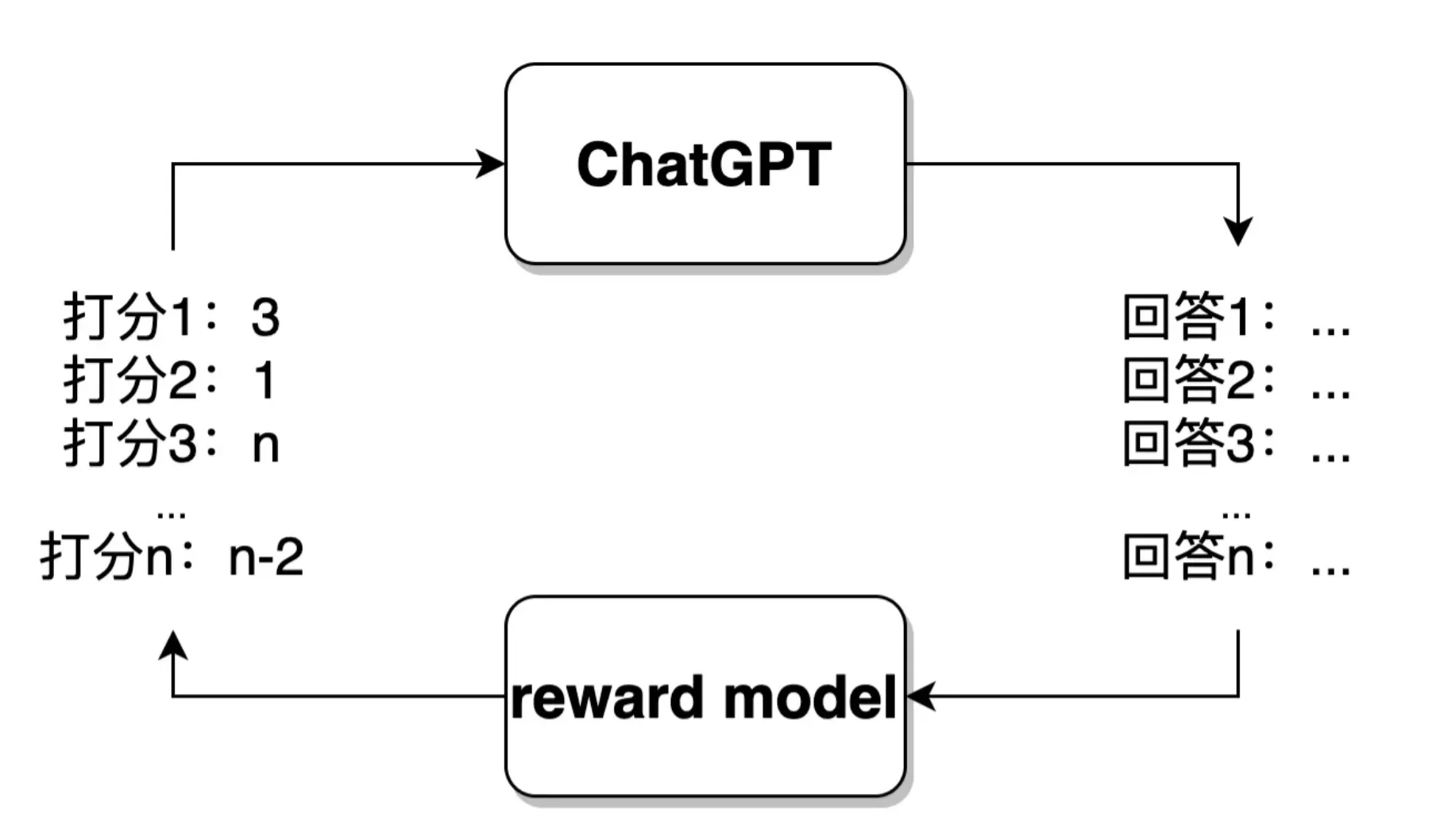
由此,ChatGPT 模型已经不再局限于已有的训练数据集(标准问答数据对),可以扩展至更大的范围,应对从未见过的问题。具体的强化学习与 RLHF 原理将在第 10-11 节展开。
总结
纵观 ChatGPT 模型的进化历史,可以看出,模型的发展脚步就是在朝着模拟人类的方式前进着。
- 人类接收语言文字信息,输出语言文字,应用了编解码方式,ChatGPT 也利用了编解码的方式。
- 人类的大脑神经元数量是所有生物中最多的,ChatGPT 应用了超千亿的大规模参数模型。
- 人类采用了对话的方式进行交流,ChatGPT 建模也采用了对话的方式。
- 人类的大脑具有多种多样的功能,ChatGPT 也融合了多任务,各种各样的NLP任务。
- 人类可以通过极少量的样例进行学习,ChatGPT 也可以完成小样本学习。
- 人类可以在与实际环境的交互中学习知识,塑造语言,ChatGPT 也添加了强化学习,模拟与人类的交互。
- ChatGPT 的发展史,就是人工智能模拟人脑的历史。