




ChatGPT 是一个语言模型,是属于 NLP 领域的概念。那什么是语言模型呢?我们来举几个例子解释一下。
例1:请各位做一个完形填空:MobotStone是一个______的技术交流平台。
在这个例子里,上述的空格处应该填什么字呢?中文汉字总共有上万个,空格里填任何一个字,都算是完成了填这个动作,我们真正关心的,是填什么字才能让文字读起来通顺。
有的人觉得毫无疑问应该填“便捷”,而有的人觉得应该是“实用”,事实上填这两种答案都是正确的,可以让文字读起来通顺。再举一个例子:
例2:请补全这条语句:MobotStone是一个便捷的技术交流______
有的人觉得,应该填写“网站”,有的人觉得应该填写“社区”、“平台”等等,但总不太可能是其它别的答案了。
总结这两个例子,我们可以得出结论,空格处要填什么字,填几个汉字,是根据空格周围的上下文来决定的。能够正确根据上下文在空格处填入恰当的文字,表明其语言能力强,否则表示语言能力弱。
所谓语言模型,就是由计算机来实现类似于人的语言交流、对话、叙述能力,它集中体现在模型能够依赖上下文进行正确的文字输出。把上述这些预测空格内容的问题交给计算机建模来完成,就实现了语言模型的训练。换句话说,语言模型就是由上述的方式来进行训练的。
在上述第 1 个例子中,空格介于一段话的中间,填写需要依赖上下文。在第 2 个例子中,空格位于一段话的末尾,句子没有讲完,需要根据前面的信息,补充后面的信息。即,例 2 的填写只需要依赖上文,例 2 中的形式就是 GPT 所采用的建模形式。
ChatGPT 语言模型的数学建模
1、语言模型基础建模
最经典的语言建模就是根据上文,输出下文,也就是例 2 的形式,这也是 GPT 模型的建模形式。
语言模型的建模公式可以表示为:
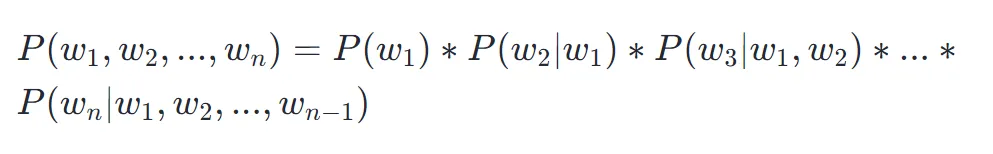
其中,表示一个句子中的字符序列,P(Wi)表示字符 Wi在语料库中出现的概率, 表示在已知前面字符的情况下,字符 Wi 出现的概率,即依赖上文,对下文的预测。把每一个字符都按照此方式预测出来,其结果就是整条语句的出现概率。
为了方便理解公式,我们依然以上述例 2 进行讲解。
例2:请补充未说完的语句:MobotStone是一个便捷的技术交流______
假设常用汉字总共有 10000 个,空格处要填写什么汉字,可以理解为从 10000 个汉字中随机地选取一个填入其中,因此可以建立概率模型。
假设在汉语中,“网”、“社”、“平”三个字的自然分布概率分别为,它表示在长达 10000 个汉字的一段网上寻找的随机文本中,“网”字出现 4 次的可能性最大,“社”字出现 3 次的可能性最大,“平”字出现 2 次的可能性最大。
然而在填写上述空格的时候,我们并不是直接根据三个汉字的概率进行抽取的,而是要依赖其上下文进行判断,于是我们有条件概率公式:
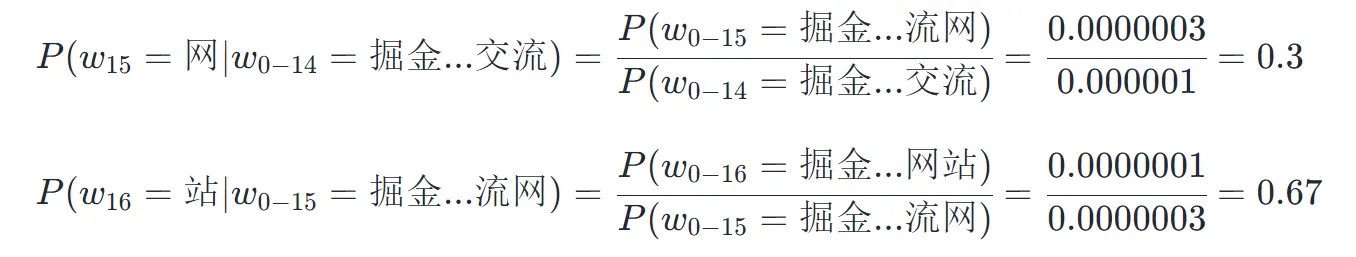
注意,在这个公式中,具体的数值是虚构的,重点在于,当依赖有上下文的前提条件下,空格处填写“网”字的概率要远远大于“网”字本身在汉语中的出现概率,“站”字出现在“网”字后面的概率也会非常大,这说明“网站”作为一个词汇整体出现的概率是非常高的。
2、N-gram 语言建模
日常生活中,接触到的新闻文本可以非常长,动辄上千字、上万字的文章随处可见。过长的文本将导致在计算语言模型的条件概率时非常复杂,因此我们通常考虑将上下文依赖局限在一个较短的范围内。
通常情况下,语言模型的建模公式采用 n-gram 模型,这个词没有对应的中文翻译,其含义是就近原则,距离第 i 个字符相隔 n 个字符距离以上的,就不在考虑范围内了。公式来讲,就是将条件概率近似为 ,其中 n 为 n-gram 模型中的 n 值。这样可以简化模型的计算,并且在一定程度上保持模型的准确性。
具体举例来讲,例 2 的计算中,上文依赖总共有 14 个字,“MobotStone是一个便捷的技术交流”,通常可以将其截短至大约 7 个字,也就是“便捷的技术交流”,因此,上述计算公式可以简化为:

3、语言模型 log 化
我们再来观察一下这个语言模型公式:
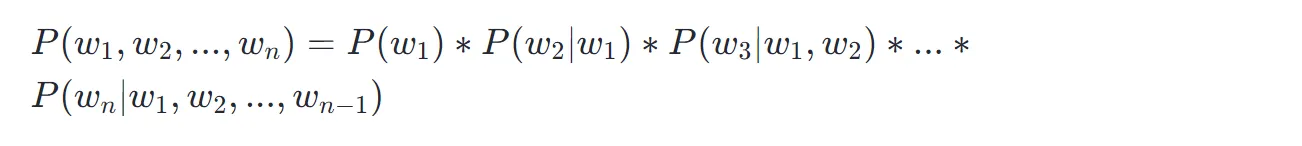
这个式子是一个连乘,其中每一个因子都是一个概率值,介于 0~1 之间。多个这样的数值相乘,其乘积会越来越小,趋近于 0。正如上文中的计算结果,=0.0000003,随着句子长度越来越长,概率值会越来越小。在实际的语言模型建模过程中,往往上下文联系多达上百个字,按照上述方法计算下去,其结果会逐渐趋近于 0。但是,这里这存在一个问题。
计算机存储小数值一般以浮点数的形式进行存储,包括 float 和 double 类型,分别占用 4 字节和 8 个字节。其中:
- float 类型表示的数据范围为 -3.40E+38 ~ +3.40E+38,精度为 6~7 位有效数字;
- double 类型表示的数据范围为-1.79E+308 ~ +1.79E+308,精度为 15~16 位有效数字。
这就说明,计算机表示小数是有一定限度的,小数点后的位数不可能无限小。一个无限趋近于 0 的小数,计算机是很难表示出来的。
因此,按照上述语言模型建模,对于计算机的系统和结构来说,都是无法实现计算的,很容易导致语言模型计算溢出计算机数据存储范围。
所以我们应当对上述式子做对数变换:
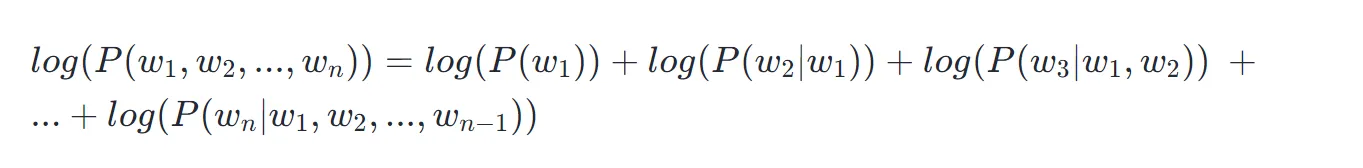
这种连加形式,实际上就是:
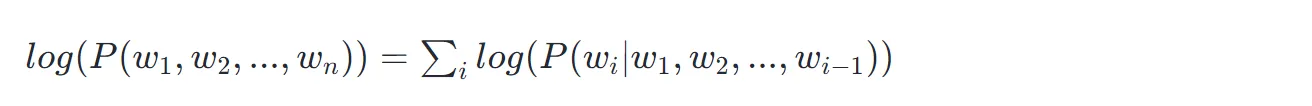
考虑 n-gram 模型建模,我们只取 k 个字符范围的上文进行建模,可以得到最终的语言建模公式为:
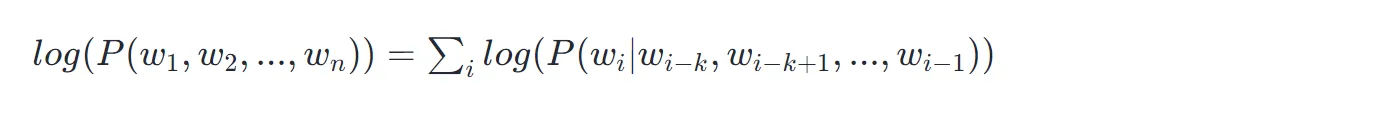
ChatGPT 的语言模型
1、ChatGPT 的建模公式
ChatGPT 就是一个复杂的语言模型,其内部原理和上述的概率模型本质上是一样的。
ChatGPT 是利用成千上万的文本语料训练得来的。每一篇语料都是一条文本,可以抽象成这样的一串字符序列,假设这个大的语料为 U,则我们的建模公式又可以表示成:
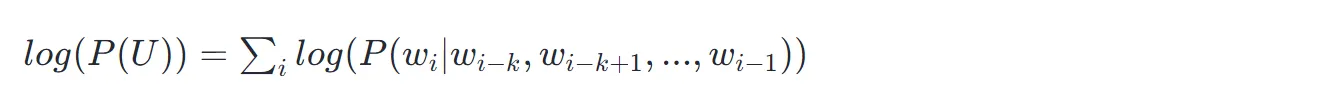
当然,ChatGPT 模型是由巨量的参数构成的,设ΘΘ为 ChatGPT 的参数集合,则模型的建模公式可以表示成:
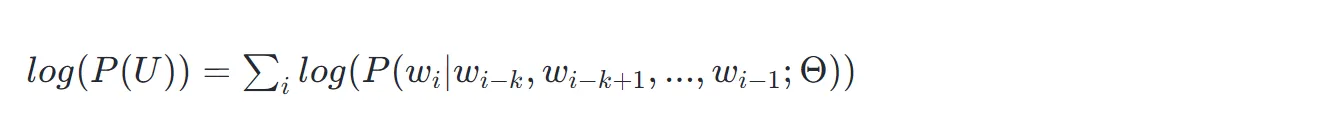
这就是 GPT 初代论文【Improving Language Understanding by Generative Pre-Training】中的模型建模公式。下图为论文中的建模公式,你可以从论文中仔细对比理解这个公式,除去公式中的字符不同,其它完全一致。
2、语言模型中的最大似然概率
在 ChatGPT 的语言模型公式中,左半边是,它其实就是一种最大似然的建模方式。在概率论中,最大似然概率是一种最为简单,也最为广泛应用的近似估计方法。比如:
2023 年,全中国人口总数大约 14 亿。作为国家统计局,应该如何花费最低成本,统计全国人口各个年龄段的分布情况呢?
为了解决这个问题,把全国所有人口的出生年月全部数据都拉出来统计一遍,得出“70 后总共 2.1 亿,80 后 2.4 亿,90 后 2.0 亿,00 后 1.5 亿”这样的结论,当然是可以的,但是成本太高了。
一个非常直观的思路,就是抽样调查,我们去大街上、菜市场里、学校里、写字楼里分别找一些人,询问他们的出生年月,然后做一个统计,直接把这个统计结果当作是全国人口的年龄分布。
在这个直观的思路背后,就蕴含了最大似然估计方法,我们利用采样的数据分布去估计整体的数据分布。它假设了一个前提,就是认定采样的数据非常具有代表性。只要我采样了 1000 个人的年龄分布数据,我就有理由充分相信,这一组数据是发生概率最大的那一组,是具有代表性的,这就是最大似然估计(Maximum likelihood estimation)。随着采样的数量越来越大从 1000 人到 10 万人,再到更多,估计的结果也就越来越接近全国 14 亿人的整体年龄分布。
回到上述的 ChatGPT 语言模型建模公式,我们同样可以做这样一个设想。
全世界所有人都在使用各种不同的语言文字,每一天,人们都说出各种各样的话语,媒体上刊登各种各样的文章,这可以构成一个集合——人类语言文字全量总集。
如果我们在训练模型的时候,能够全量使用这个总集合当然好,但实际上却办不到。我们只能取到互联网上存在的一部分文本数据,比如 Wikipedia 上的数据、BBC、今日头条上的新闻、论坛里的网民数据等等。当我们取到这样一个成规模的语料数据集之后,需要先假定一点,这些有限的语料数据,充分代表了人类语言文字全量总集。
因此,训练模型时,就是在利用极大似然估计的方式,使得建模公式的左边概率值最大,它也是模型预训练的目标。
3、ChatGPT 语言模型的训练方式
假设我们已经获取了大量的语料数据,即将训练一个自己的 ChatGPT 模型,语料样例如下:
文本1:甲方应当在收到上述租金后 15 日内,应向乙开具合法有效的增值税专用发票。
文本2:去餐厅吃饭的时候,别人都不愿意和我坐在一起,我只能孤零零的一个人,所以很不开心。
文本3:"止咳化痰”及其它对症治疗后,咳嗽咳痰较前好转。患者当地医院支气管镜我院病理会诊(H2019-00310):阅杭州迪安医学检验中心 HZ2019066642 HE×2张,IHC×8张
文本n:… …
这些语料描述的内容千奇百怪,长度各不相同,当然还有错别字、特殊符号等等。我们该如何组织利用这些数据呢?
模型的训练方式,归根结底就是要做概率的预测。首先,抽取其中一条文本,例如这一条法律领域的文本:
甲方应当在收到上述租金后 15 日内,应向乙开具合法有效的增值税专用发票。
首先,我们只关注句子的开头,把“甲方”二字当作模型的输入,预测模型接下来最有可能输出什么汉字:
一个优质的 GPT 预训练语言模型应当能够根据上文,来对下文进行预测。这里的训练过程就用到了前述的最大似然估计,“甲方”二字是一个不完整的句子,后续可以接续很多可能的汉字组成连贯的句子,比如“甲方应当在……”“甲方如有违约……”“甲方可以申请……”等等。后续可以接任何汉字,所有的条件概率加起来概率等于 1,如下图所示。
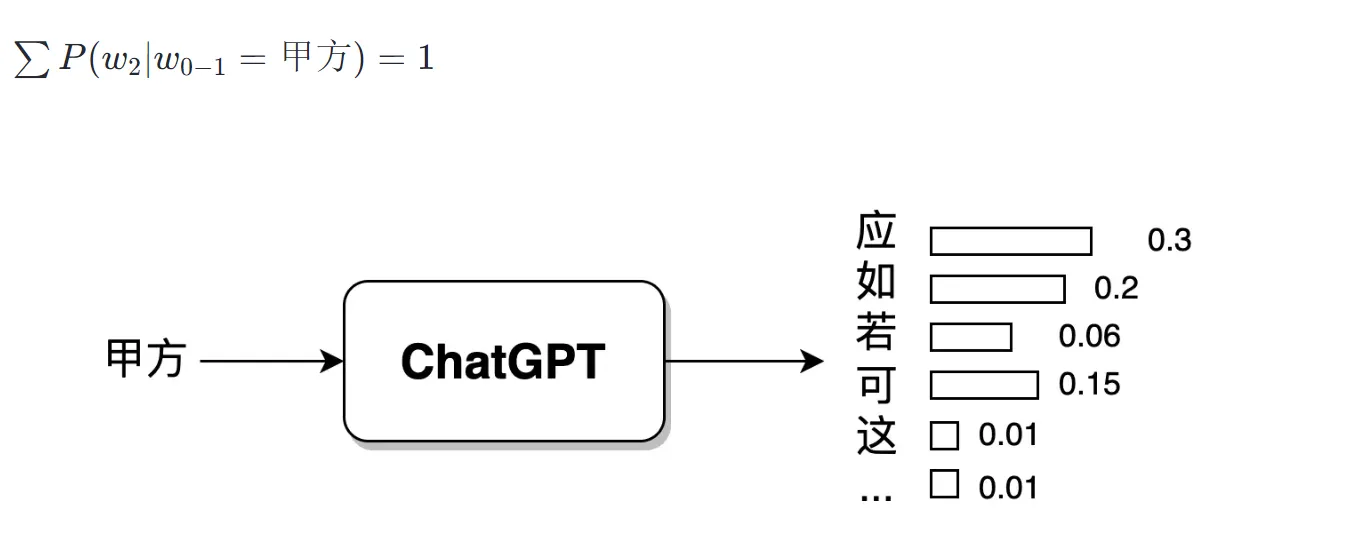
在图中,我们大致可以看出,“应”字的条件概率值最高,为 0.3。
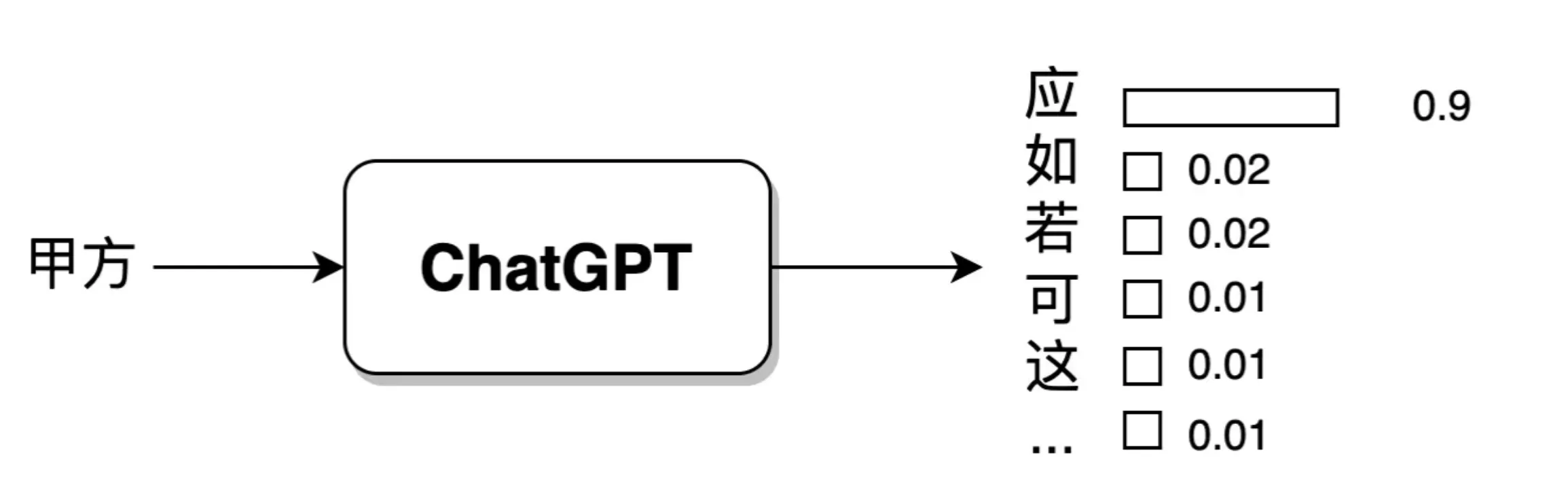
但是目前我们仅仅有上述这一条文本数据,根据最大似然估计原则,最有可能的出现在“甲方”这一句子之后的字,是“应”字。那么,我们在模型训练的过程中,就要使“应”字出现在“甲方”之后的概率尽可能地大。下图所示的就是一个根据当前举例的数据,训练得到的模型结果。
接下来,就是重复上述过程,递进地让模型学习上述一整句话,方法如下图所示。
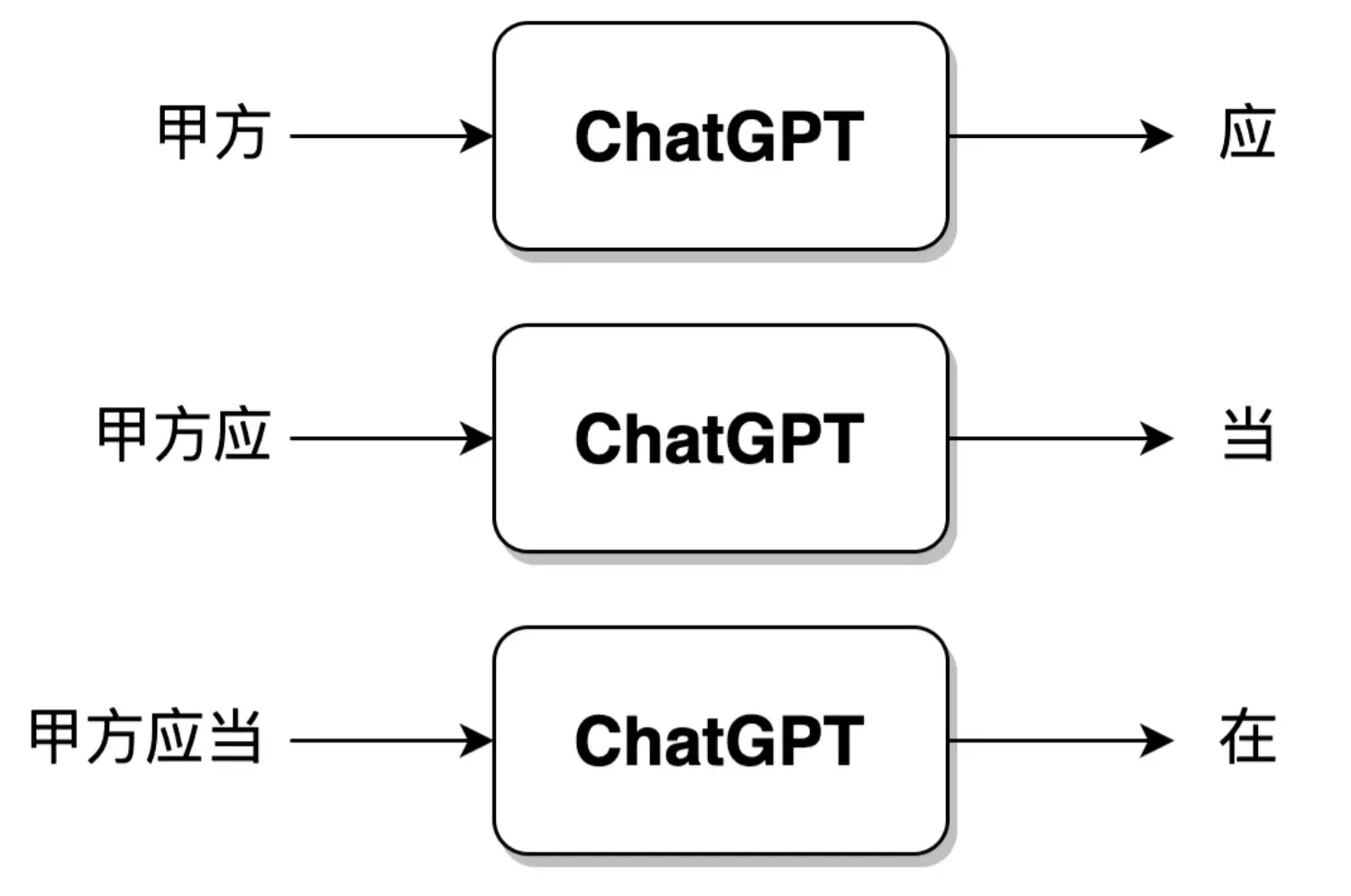
用一句话来概括上述的 GPT 训练方式,就是让模型学会文字接龙游戏。
实际上,ChatGPT 训练语言模型的过程,就是 ChatGPT 模型预训练的过程。本节主要介绍语言模型的建模,预训练的内容将在第 8-9 节中展开介绍。
总结
- ChatGPT 的语言模型建模公式为:
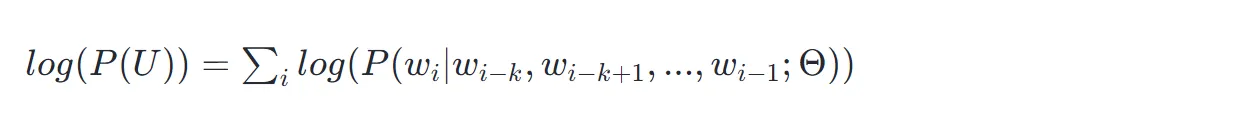
- 语言模型的训练就是让模型根据上文,猜测下文最可能的内容,即文字接龙。
- 最可能的内容,实际上是一种最大似然的准则来约束模型的训练目标。