

.png)
2026年4月2日,谷歌正式发布了 Gemma 4,并采用了 Apache 2.0 开源协议。别小看“采用 Apache 2.0”这句话,它的分量可比听上去重得多。上一代 Gemma 3 附带的是谷歌定制的许可证,里面的条款常常让各家公司的法务团队捏一把汗。但现在,Gemma 4 实现了真正意义上的完全开源:你可以自由地微调模型、拿它做商业产品去卖、或是直接部署在自己的硬件上,再也不用为那些烦人的使用限制提心吊胆了。
对于想要开发“本地优先(local-first)”AI助手或编程智能体(Coding Agents)的开发者来说,这一举措扫清了最后的绊脚石。它让 Gemma 不再仅仅是个“好玩的实验室模型”,而是真正变成了一个“能直接打包上线的硬核产品”。
这次发布之所以如此备受瞩目,除了开源协议,还在于它的模型尺寸设计、核心应用场景,以及当它作为“工具调用(tool-calling)”智能体的底层基建时,所展现出的出色表现。

Gemma 4 到底带来了哪些新东西?
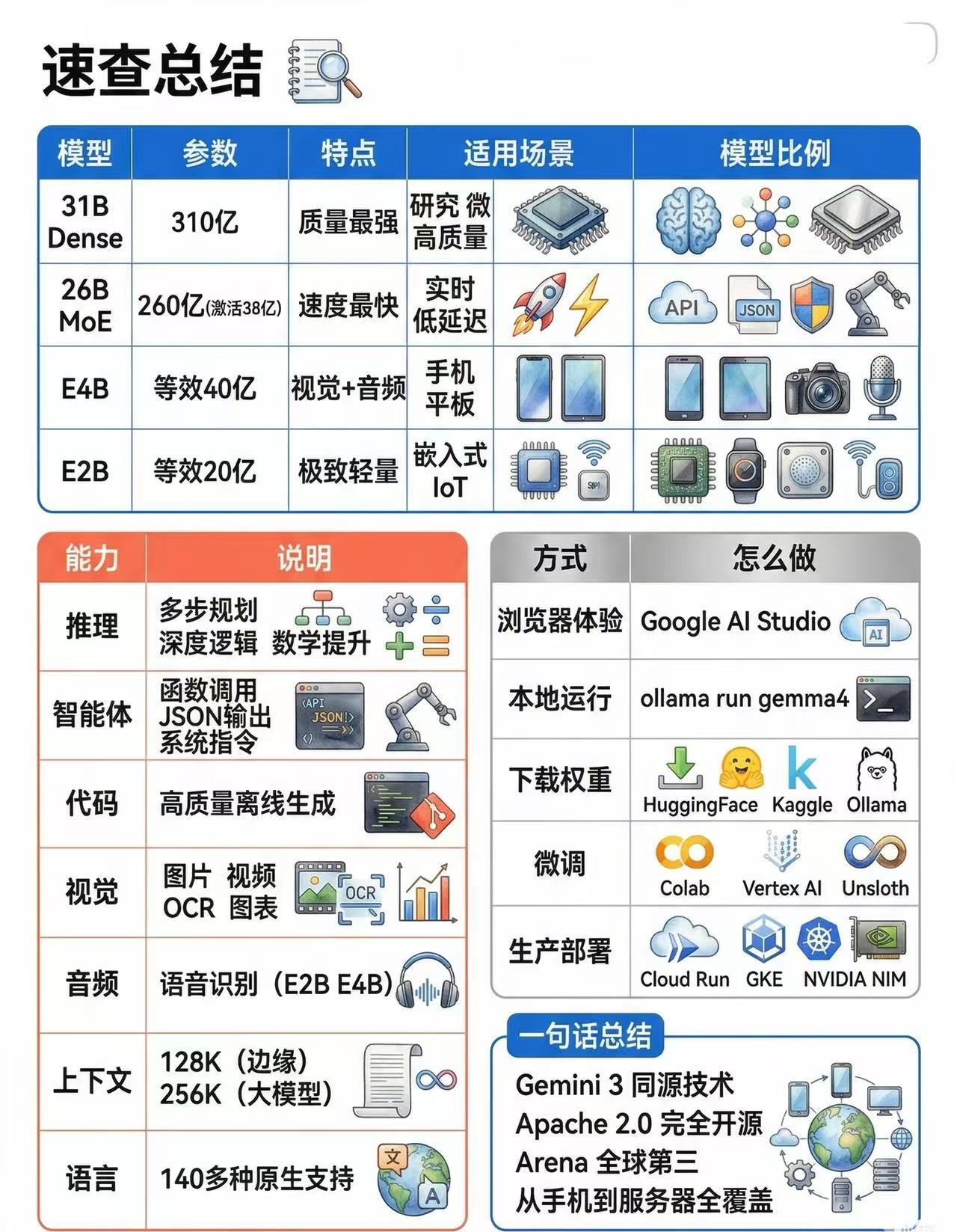
Gemma 4 系列由四款模型组成。其中两款轻量级模型命名为E2B和E4B——这里的“E”代表“Effective”(有效),指的是推理时实际参与计算的参数量,而非总参数量。
E2B:在 51 亿总参数中,推理时仅激活约 23 亿参数。
E4B:在 80 亿总参数中,推理时仅激活约 45 亿参数。
这两款是专为边缘计算设计的模型,可以在手机、平板、树莓派(Raspberry Pi)以及 NVIDIA Jetson 开发板上流畅地离线运行。它们具备全能的多模态处理能力,支持文本、图像和音频,并拥有 128K 的上下文窗口。
另外两款则是大参数模型:26B MoE(混合专家模型)和31B Dense(稠密模型)。26B MoE 虽然总参数量高达 252 亿,但推理时仅需激活 38 亿参数——这意味着你只需付出 4B 模型级别的速度和显存代价,就能获得接近 26B 模型的性能。在 4-bit 量化下,它仅需 18GB 显存即可运行。这两款大模型都支持高达 256K 的超长上下文窗口,支持文本和图像处理(暂不支持音频)。
此外,这四款模型都原生支持函数调用(Function Calling)、结构化 JSON 输出以及标准的**system 角色设定**。这些功能已深度融入模型的指令微调阶段,这对于在智能体工作流(Agent Loop)中实现稳定、可靠的工具调用至关重要。
在各项基准测试中,Gemma 4 的表现也非常抢眼:
综合排名:在Arena AI 文本排行榜上,31B 稠密模型在开源模型中位列第 3(1452 分),26B MoE 位列第 6(1441 分)。
数学与编程:在 AIME 2026(数学测试)中,31B 拿到了 89.2% 的高分;在 LiveCodeBench v6(竞技编程)中,两者的得分分别为 80.0% 和 77.1%。
智能体能力:在 Tau2 智能体工具使用测试中,31B 模型取得了 76.9% 的惊人成绩,相比 Gemma 3 27B 的 16.2% 实现了跨越式的提升。
技术解读:架构细节
Gemma 4 31B 的底层架构与 Gemma 3 27B 相比并没有“推倒重来”,更多的是在血统上的延续。它保留了混合注意力机制,以 5:1 的比例交替使用滑动窗口注意力层和全上下文注意力层,并采用了标准的分组查询注意力(GQA)。其中,小尺寸模型的滑动窗口为 512 token,大尺寸模型则为 1024 token。
真正有意思的是那些精细的优化:
双重 RoPE 配置:在滑动窗口层使用标准 RoPE,在全局层使用比例 RoPE。这种设计让模型在支持超长上下文的同时,不会牺牲生成质量。
逐层嵌入(PLE):每个解码层都会为每个 token 接收一个独立的、微小的调节向量,而不仅仅依赖于输入端计算出的单一嵌入向量。这以极小的参数成本换取了每一层模型的“专业化”处理能力。
KV 缓存共享:模型的最后 N 层会与之前相同类型的注意力层共享键值(KV)缓存。在生成长文本时,这能显著降低显存占用并提升计算速度。
总的来说,这些改进并非“奇技淫巧”,而是对现有成熟技术的精妙组合与调优。正如 Hugging Face 团队所言,性能的飞跃可能更多归功于训练集和训练方案的优化,而非架构上的彻底翻新。
模型选型指南
选择哪个版本的 Gemma 4,取决于你的硬件配置、对延迟的忍受度以及具体任务。
E2B 和 E4B:适用于需要在设备本地运行的场景。比如手机上的离线助手、边缘硬件上的轻量化多模态任务,或者你无法接受请求往返云端服务器的超低延迟需求。如果内存充裕,E4B 是更好的选择;若配置极其有限,则选 E2B。这两款还支持音频输入。
26B MoE:个人工作站的“性价比之王”。由于每次推理仅激活 3.8B 参数,它运行效率极高,性能却直逼 31B 稠密模型。如果你想在笔记本或桌面显卡上运行编程机器人或工具调用助手,且追求高吞吐量,它是首选。在 4-bit 量化下,它大约需要 18GB 显存。
31B Dense:全系列中的“性能天花板”。如果你需要处理复杂的编程逻辑、多步骤规划或极高要求的推理任务,且对速度不那么敏感,选它准没错。未经量化的版本需要单块 80GB 的 H100 显卡,但量化版可以在消费级显卡上跑起来。
将 Gemma 4 作为本地 Agent 运行:工具调用与思考模式
想让 Gemma 4 在智能体工作流(模型调用工具、接收结果、继续推理)中表现出色,需要注意提示词(Prompt)和对话管理的细节。
严格的 JSON 模式:为了保证工具调用的稳定性,请提供明确的 JSON Schema,并严格规定模型返回的格式。虽然 Gemma 4 原生支持函数调用,但清晰的定义和明确的指令依然能显著提升成功率。
多模态顺序:处理图像或音频时,请在提示词中将媒体文件置于文本之前。这是官方文档推荐的最佳实践,也更符合模型的训练方式。
剥离“思考过程”:这是多轮对话中最重要的技巧。当开启思考模式时,模型会先输出一段内部推理(Thinking trace)再给出最终答案。在下一轮对话中,请务必删除上一轮的思考路径,只保留最终回复。否则,这些冗余信息不仅会浪费上下文窗口,还会干扰后续对话的质量。
关于多轮 Agent 对话,最重要的一条实操建议是:千万别把模型的“思考过程(reasoning traces)”存进历史记录里。
推荐采样参数设置:temperature=1.0, top_p=0.95, top_k=64。
在 Ollama 中配置思考模式与上下文
在 Ollama 中,首先拉取对应的模型版本(例如 gemma4:e4b 或 gemma4:31b)。
关键步骤:不要使用默认的 4096 token 设置。请根据硬件和任务需求手动设置 num_ctx(例如通过命令 /set parameter num_ctx 131072 或通过 API 设置)。
针对 Gemma 4,Ollama 官方建议在系统提示词开头使用 <|think|> 标记来触发推理模式。再次提醒:在多轮对话中,记忆里只保留助手最终的输出,手动剔除之前的推理内容。
在 OpenCode 中结合 Ollama 使用
OpenCode 是一款基于终端的开源 AI 编程助手,与本地运行的 Ollama 是绝配。有两种简单的配置方法:
1. 快速启动(一行命令):
ollama launch opencode --model gemma4
2. 自定义配置:
在 ~/.config/opencode/opencode.json 中添加如下配置块,即可精细控制模型行为并开启思考模式:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"ollama": {
"npm": "@ai-sdk/openai-compatible",
"name": "Ollama (本地)",
"options": {
"baseURL": "http://localhost:11434/v1"
},
"models": {
"gemma4-26b": {
"name": "gemma4:26b",
"thinking": true
},
"gemma4-e4b": {
"name": "gemma4:e4b",
"thinking": true
}
}
}
}
}
配置完成后,你可以在 OpenCode 里通过 /models 选择要使用的模型。建议先拿一个需要频繁调用工具的任务来做测试。OpenCode 官方建议,上下文窗口最好至少设为 64K tokens。如果你发现工具调用不够稳定,那就把 Ollama 的 num_ctx 往上调——可以先从 16K 到 32K 开始,再根据显存或内存情况逐步增加。默认的 4096 对大多数 Agent 工作流来说,确实太小了。
哪些地方需要特别注意
正如不少模型评测分析里提到的那样,Arena 这类对战式榜单并不完全可靠。这类测试有被“刷分”或“针对性优化”的空间,而且它们往往更偏向那些更符合人类表达习惯和偏好的模型,而不一定是在严格衡量模型的真实能力。所以,跑分数据可以参考,但最好把它看作多个信号中的一个,而不是唯一标准。
另外,显存和内存压力是实打实存在的。256K 的上下文窗口听起来很诱人,但真要在一张 24GB 显卡上把它塞满,你就会发现压力非常大。量化确实能帮你省下一部分资源,共享 KV Cache 的优化也能降低一些开销,但长上下文依然会吃掉大量内存。因此,num_ctx 的设置要根据你手头硬件实际能承受的范围来定,而不是只看模型“理论上支持多少”。
还有一点非常重要:工具执行的安全性,责任在应用层,不在模型本身。 Gemma 4 可以帮你生成函数调用,但它并不知道这些调用是不是安全、有没有权限、执行后能不能回滚。像审批边界、沙箱隔离、安全校验这些事情,都需要你在自己的应用里亲自做好,不能指望模型替你兜底。
现在值得上手吗?
如果你手上有一块 18–24GB 显存的工作站级 GPU,而且正在做本地编程 Agent 或 AI 助手,那么 26B MoE 是一个很不错的起点:性能和效果都比较均衡,运行效率也高,再加上 Apache 2.0 许可证,不会给部署带来额外的法务麻烦。
如果你更看重推理能力,而且 GPU 资源更充裕,那么 31B Dense 也值得考虑。虽然它更吃显存,但能换来更强的复杂推理和规划能力。至于边缘设备和移动端场景,E4B 已经能覆盖大多数常见需求;而 E2B 则更适合那种资源特别紧张、每 1GB 都得精打细算的环境。
从架构创新的角度看,Gemma 4 并不算特别“新”。它真正带来的价值在于:这是一套经过充分优化、可以本地运行、没有许可证束缚,而且能跑在你现有硬件上的模型。 对于那些正在做“本地优先”Agent 的开发者来说,这才是它真正值得认真评估的地方。

评论区