




知识图谱是一种非常强大的表示工具,它可以通过一张图表达复杂的概念,这就是为什么常说“一图胜千言”。但是,如果我们在没有明确定义的模式下创建知识图谱,就会存在一些问题。这就是为什么需要一种模式来限制链接的类型,充当文档,提供和机器可读的语义,并确保软件按照预期的方式来组织信息。
对于知识图谱而言,良好的模式设计比关系数据库更为重要和核心。不幸的是,对于如何完成相对简单的任务而言,目前缺乏详细的指导。根据我的经验,我想至少提供一些帮助。
为了更好地了解模式设计的模式和原则,我们可以使用TerminusCMS。虽然其中许多想法也适用于其他领域。
文档(Documents)
在知识图谱TerminusDB中,数据被视为由具有特定数据类型的字段组成的基本单元,这些字段可以是字符串、整数或日期等类型。这些基本单元会被组织成一个数据集合,称为“文档”。
举个例子,我们可以看看“Person”文档,以更好地理解这个概念。
{ "@type" : "Class",
"@id" : "Person",
"first_name" : "xsd:string",
"family_name" : "xsd:string",
"date_of_birth" : "xsd:dateTime"
}
这个人的信息包括姓名和出生日期,类似于关系型数据库(RDBMS)或逗号分隔值(CSV)文件中的行记录。为了让数据更加丰富,可以添加一些额外的链接。
{ "@type" : "Class",
"@id" : "Person",
"first_name" : "xsd:string",
"family_name" : "xsd:string",
"date_of_birth" : "xsd:dateTime",
"friends" : { "@type" : "Set", "@class" : "Person" }
}
在知识图谱中,我们可以将人与他们的朋友之间建立链接。这种数据结构非常适合用于社交网络或联系人管理应用程序。我们可以将每个人视为一个文档,其中包含许多数据属性,例如姓名和出生日期。此外,我们可以在文档中添加指向其他文档的链接,以建立人与他们的朋友之间的联系。这种建模方式非常简单和灵活,让我们能够方便地捆绑所有的数据属性和链接在一起。
子文档(Subdocuments)
有时,您需要在文档中包含一个内部结构,这个结构不仅仅是一个数据原子,而是与该对象有紧密联系,而不只是指向另一个对象的链接。这种类型的对象最常见的变体是注释了一些附加结构的数据。例如,我们可能希望在某个时间范围内得到数据点,该数据点具有特定的来源或可能有一个单位。
{ "@type" : "Enum",
"@id" : "Unit",
"@value" : [ "meters", "kilograms" ] }
{ "@type" : "Class",
"@id" : "UnitValue",
"@subdocument" : [],
"value" : "xsd:decimal",
"unit" : "Unit" }
有时候一个数据原子的值本身并没有意义,但是在特定对象的上下文中却很有用,例如人的身高。为了表达这种内在联系,我们可以使用子文档,它可以将数据与额外的结构注释关联起来。使用"@subdocument" : []指定一个子文档类,这个子文档将完全属于包含类,不允许其他人对其进行引用,并且当我们搜索包含文档时,它将始终以完全扩展的 JSON 文档返回。
{ "@type" : "Class",
"@id" : "Person",
"first_name" : "xsd:string",
"family_name" : "xsd:string",
"date_of_birth" : "xsd:dateTime",
"friends" : { "@type" : "Set", "@class" : "Person" }
"height" : "UnitValue",
"weight" : "UnitValue",
}
您可能已经发现,“height”和“weight”都被表示为“UnitValue”,但是可能没有使用正确的单位。为了确保单位的正确性,我们正在加入一些限制。
关系(Relationships)
并非所有关系都可以简化为一个简单的链接。xsd:decimal是表示数字的一种数据类型,然而,对于复杂的关系,通常可以使用子文档来表示它们,就像我们使用单位装饰基本类型以添加辅助信息一样。如果您有一个复杂的关系,将其升级为一级对象通常是有意义的。例如,假设我们要表示股权关系,我们可以使用子文档来描述持股人、股票数量、股份转让条款等详细信息。
{ "@type" : "Class",
"@id" : "Company",
"name" : "xsd:string" }
{ "@type" : "Class",
"@id" : "Shareholder",
"name" : "xsd:string" }
{ "@type" : "Class",
"@id" : "Company",
"@inherits" : "Shareholder" }
{ "@type" : "Class",
"@id" : "Person",
"@inherits" : "Shareholder" }
{ "@type" : "Class",
"@id" : "Shareholding",
"quantity" : "xsd:decimal",
"shares_in" : "Company",
"held_by" : "Shareholder",
"from" : "xsd:date",
"to" : { "@type" : "Optional", "@class" : "xsd:date" }}
我们的Shareholding关系包含两个不同的角色:持股公司和股东,他们可以是个人或公司。此外,我们还添加了关于这个关系的两个附加信息:持股数量和持有时间。这种一流关系链接的方法可以扩展到处理超图,即涉及两个或更多对象的关系(例如接管)。
混合(Mixins):面向方面编程的多重继承
在编程语言中,多重继承是一种有效的工具,但在数据处理中,它更加实用。混合是数据建模中可重复使用的一种方法,可以用来解决一些通用问题,例如空间、时间、来源和单位等。在我的建模经验中,我发现这些通用问题在数据建模中屡次出现,它们是跨多个领域的共同问题。
时域范围(Temporal Scope)
上面的例子Shareholding使用了时间组件,但该组件也可作为mixin(混入)在其他地方重用。mixin是一种可组合的代码单元,可在不同类或对象中进行重复利用,以实现更高的代码复用性和灵活性。因此,将时间组件提取为mixin可以在其他数据建模中方便地进行复用,提高建模效率和代码质量。
{ "@type" : "Class",
"@id" : "TemporalScope"
"from" : "xsd:date",
"to" : { "@type" : "Optional", "@class" : "xsd:date" }
}
在数据建模中,时间范围的起始日期(from)是必须要有的,因为它描述了一些事情的开始时间。但是,结束日期(to)是可选的,这样可以建模尚未结束的时间范围。当然,并不总是需要这样做,但通常这是一种非常有用的方法。
此外,我们可能还需要建模只发生一次的事件,即在某个特定时刻发生且不再重复发生的事件,例如一个人的生日或一场比赛的开始时间。
{ "@type" : "Class",
"@id" : "Event"
"at" : "xsd:date"
}
空间范围(spatial scope)
在知识图谱中,我们可以利用几何形状为对象添加空间范围,这可以通过继承来实现。我们可以将不同的几何形状组合在一起来表示空间范围,例如矩形、圆形或多边形。这种方法使我们能够描述一个实体或概念在地理上的位置或空间范围。
{ "@type" : "Class",
"@id" : "GeographicScope",
"geometry" : "Geometry" }
在这个上下文中,“Geometry”所指的是GeoJson中的一个类,具体指的是“Geometry类”。
溯源(Provenance)
为了更好地了解某些信息,通常需要记录相关资源的来源。例如,当我们从网站等途径获取资源时,这种记录就很常见。在这种情况下,我们可能需要创建一个继承Event和Source类的对象来记录这些信息。
{ "@type" : "Class",
"@id" : "Source",
"source" : "xsd:anyURI"
}
{ "@type" : "Class",
"@id" : "WebScrape",
"@inherits" : ["Event", "Source"],
"page" : "xsd:string",
}
集合体(Collections)
在知识图谱中,有许多不同的方式可以对集合进行建模。TerminusDB 实现了三种不同的方法,旨在尝试简化建模过程,这三种方法是:Set、List和Array。了解这三种方法之间的差异非常重要:Set表示集合,List表示列表,而Array则表示数组。
集合(Set)
Set是三种集合模型中最简单的一种,因为它没有顺序,实际上只是一条边,可以包含多个元素。在图中,具有三个元素的Set集合可以表示为以下形式:

数组(Array)
Array是一个更复杂的对象,它通过索引来对元素进行编码,并且可以根据位置来访问它们。与Sets和Lists不同,Array具有固定的大小,其元素是有序的。此外,Array还提供了一些额外的功能,使其与Sets和Lists区别开来。
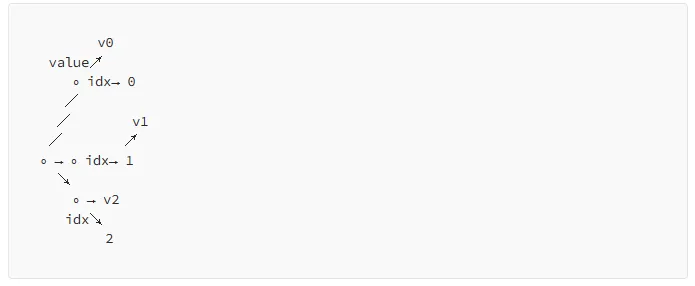
数组中的每个值元素都有一个附加的(隐藏)间接对象,带有索引(或多维数组的多个索引)。这使得我们不仅可以有顺序,还可以有多个维度来表示“间隔”。当返回 JSON 中的值时,我们将返回一个多维数组,其中包含未填充区域的null字段。但实际上,这些未填充区域并没有在数据库中出现。
列表(List)
List 是直接从 RDF 数据中提取 rdf:List 并使用 rdf:first 和 rdf:rest 字段来表示。三个元素的列表结构如下所示:
∘ → ∘ rest→ ∘ rest→ ∘ rest→ rdf:nil
↓ first ↓ first ↓ first
v0 v1 v2
链表式结构具有潜在的技术优势。相较于数组,您可以在列表中的任何位置插入新元素,而不必在给定元素之后重新索引所有内容。但是,链表式结构需要遍历图中的长链来解码列表,这可能会对性能产生影响。在列表非常长时,它可能会导致解码时间显著延长,因此需要权衡其优缺点来选择适合特定场景的数据结构。
结论
通过使用知识图谱,可以实现更加轻松地操作和发现数据。知识图谱是一个基于图形结构的数据模型,可以将各种实体和概念以及它们之间的关系表示为节点和边,使得数据之间的关系和结构更加清晰和易于理解。在使用知识图谱进行数据建模后,用户可以方便地进行数据操作和发现,从而更加高效地利用数据。